Trust in AI is Priceless
Many machine learning models fail to deliver. Sadly, it’s often due to a lack of focus on data quality.
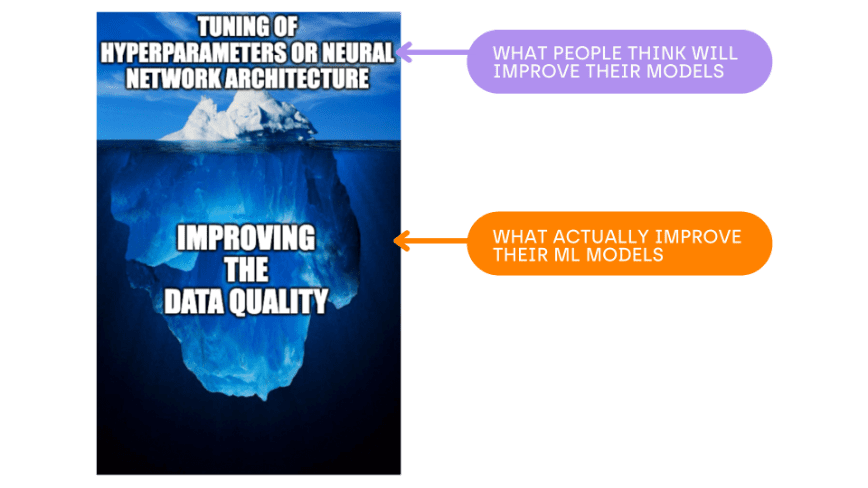
As the co-founder and CTO of an IDE platform for data-centric AI (Kili Technology), I see too many machine learning models failing to deliver. Sadly, it’s often due to a lack of focus on data quality.
Quick Catch-up
10 years ago, during the model-centric AI era, AI peeps like us struggled with the model. We lacked infrastructure, tools, toolkits, or frameworks to help us create and train ML models.
Today, life-saving packages such as Tensorflow and PyTorch exist. We now have to focus on data, from its finding and sorting to its annotation.
But it’s worth it. On many occasions, improving the data quality will have a more significant impact on its performance than any tuning of hyperparameters or neural network architecture.
You only need 2 things in data-centric AI:
- Quality data, which consists of clean and diverse data
- Sufficient volume of training data.
Bigger is Not Always Better
Big volumes of data are the key to many deep learning successes. But big volumes of data come with challenges:
- it is cumbersome and expensive in terms of hardware and human computing resources;
- it poses problems: bias, technical debt and compatibility with the new foundation model paradigm.
Model bias
If you focus on labeling productivity and apply pre-annotation to documents too early, it encourages annotators to include errors from your model in the data.
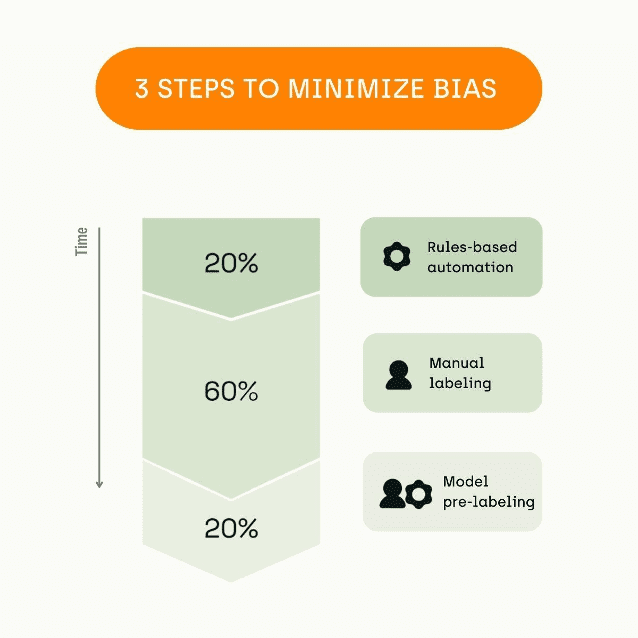
If you want to minimize bias, there’s no free lunch. Here’s how to proceed:
- Start with rules-based automation if you have some a priori knowledge of the task. For instance, regular expressions and dictionaries are useful for NLP.
- Then go manual labeling. This is where you actually create value for your model because you annotate the hard part made of non-trivial examples and edge cases. Quality management is vital for this phase as it requires a lot of synchronization across the labelers to be consistent.
- Finally, model pre-labeling to go from a good to a great dataset. It should only be used at the end; otherwise, you will create biases.
Technical debt
In software development, doubling the amount of code means doubling many things:
- the number of behaviors our system creates
- the number of unit tests required.
For AI, code = data. Doubling the amount of data means doubling:
- the number of behaviors our ML system creates
- the number of ML unit tests required
- the technical debt otherwise.
Not compatible with foundation models
Today, we have giant foundation models (GPT-3, BERT, or DALL-E 2) that have been pre-trained on all text or images on the Internet; they understand language rules. Since your model needs a huge generalization capability, it needs very little data. As a result, every data will have a stronger impact. Thus instead of annotating a large volume of data with potential errors, you need to annotate less and be more precise about the examples you feed your model, as bad data can easily influence them.
Why is Getting Quality Data Challenging?
To reduce the amount of data needed by our ML models, we must improve its quality. However, it is challenging since we’ve to address these 2 points simultaneously:
- data representativeness (Is the data unbiased? Does the data cover the edge cases?)
- labeling consistency (do the labelers annotate the same way? Have they understood the task?).
Datasets are not easy to debug. It is not always easy to give a yes or no answer. For instance, in an image classification task, is an image of a house's window an image of a house?
The answer will depend on the context, on the task, on the usage, etc. This is true for non-expert tasks. This is also true for expert tasks.
For instance:
- Rheumatoid arthritis and malaria have been treated with chloroquine for decades. -> treats the relation between chloroquine and malaria.
- Among 56 subjects reporting to a clinic with symptoms of malaria, 53 (95%) had ordinarily effective levels of chloroquine in blood. -> DOES NOT treat the relation between chloroquine and malaria.
How to Manage Quality at Scale
At Kili Technology, we’re committed to sharing best practices with our users willing to manage quality and scale.
Label consistency
Here are some tips:
- Iterate in small steps on the annotation. Here’s the specific process for building quality datasets.
Just so you know: each iteration should last 3 days tops. - The engineer responsible for building the model annotates 50 to 100 examples by hand, giving you an idea of the different classes that exist.
- Write solid definitions and concepts of classes you aim for your model to identify. This should include instructions on how to handle specific edge cases.
- Iteratively get larger batches of documents annotated (100 or 200 at a time) by external partners or others within the company.
- Iterate to debug at any step: instructions, ontology, consensus coverage.
- Use a tool design to avoid wrong annotation gesture by design.
- Prevent bad annotations. For instance, in relation extraction, prohibit relationships in the UX that don't make sense.
- Minimize the number and complexity of annotation actions. For example, on some tasks, it is better to draw the object first and then select the class, and on other tasks, the opposite is true.
- Train your people: labeling needs proper training to get labelers to ramp up fast.
- Detect possible errors.
- Implement rule-based quality checks from the beginning of the project. e.g., isn't the number of annotated vertebrae greater than the number of human vertebrae?
- Use a model to compute the likelihood of your labels and prioritize the review at the end of your project.
- Use metrics, such as the consensus at asset and annotators levels to debug your labeling process and prioritize your review.
- Set a pyramidal review system with layers: pre-annotation models, then labelers, then reviewers, and ML engineers.

Data representativeness
Two important points here:
- Have unbiased data.
- Have sufficiently rich data.
Our world is full of biases that need to be removed from the models. For example, if I use the embeddings of GPT-2 to build a sentiment analysis model on financial news, the names of the companies alone are already tinged with a sentiment: Volkswagen is negative because of the scandal of the last few years, over-represented in the GPT-2 training data. To correct this, here are some ideas:
- replace sensitive named entities (companies) with placeholders before training a language model;
- generate counterfactual data to balance the feelings related to company names;
- orthogonalize the embedding space to remove the bias effect.
Our world is full of edge cases. For example, a chair flying on the highway in self-driving cars images. To build a diversified dataset, you can reuse the boosting method, well known in ML, to the data. From a reservoir of data candidates:
- Train an initial model and predict on the validation set.
- Use another pre-trained model to extract embeddings.
- For each misclassified validation image, retrieve the nearest neighbors using the embeddings. Add these nearest neighbor images to the training set.
- Retrain the model with the added images and predict on the validation set.
- Repeat until you are good.
Conclusion
Until now, the ML community has focused on data quantity. Now, we need quality. There are many other tips to get this quality at scale.
P.S. Tweet me your feedback!
Edouard d'Archimbaud (@edarchimbaud) is a ML engineer, CTO and cofounder of Kili, a leading training data platform for enterprise AI. He is passionate about Data-centric AI, the new paradigm for successful AI.