ReAct, Reasoning and Acting augments LLMs with Tools!
Blending reasoning with action, AI takes a bold new step toward replicating human intelligence.
Introduction
Short for Reasoning and Acting, this paper introduces a new concept that improves the performance of LLMs and also provides us with more explainability and interpretability.
The goal of AGI could be one of the most important goals for human civilization to achieve. Imagine creating artificial intelligence that could generalize to many problems. There are many interpretations of what an AGI is, and when do we say that we have achieved it?
The most promising method for AGI in the last decades was the reinforcement learning path, more specifically what DeepMind was able to achieve hard tasks, AlphaGo, AlphaStar and so many breakthroughs…
However, ReAct outperforms imitation and reinforcement learning methods by an absolute success rate of 34% and 10% respectively, while being prompted with only one or two in-context examples.
With this kind of result (of course, provided there is no data leakage and we can trust the evaluation methods provided in the paper), we can no longer ignore LLMs’ potential to reason and divide complex tasks into logical steps.
The Motivation Behind The Paper
This paper starts with the idea that LLMs so far are impressive in language understanding, they have been used to generate CoT (Chain of thought) to solve some problems, and they were also used for acting and plan generation.
Although these two have been studied separately, the paper aims to combine both reasoning and acting in an interleaved manner to enhance LLM's performance.
The reason behind this idea is that if you think about how you, as a human, behave in order to execute some task.
The first step is that you’ll use “inner Speech” or you’ll write down or communicate with yourself somehow, saying “How do I execute task X? to do task X I need to first do step 1 and then do step2 and so on”
More concretely, if you were to cook up a dish in the kitchen, you could ReAct something like this:
“Now that everything is cut, I should heat up the pot of water”), to handle exceptions or adjust the plan according to the situation (“I don’t have salt, so let me use soy sauce and pepper instead”), and to realize when external information is needed (“how do I prepare dough? Let me search on the Internet”).
You can also act (open a cookbook to read the recipe, open the fridge, check ingredients) to support the reasoning and answer questions (“What dish can I make right now?”).
This combination of both reasoning and acting is what makes humans learn and achieve tasks even under previously unseen circumstances or when faced with information uncertainties.
Reasoning Only Approach
Previous works demonstrated the capabilities of LLMs to reason, for example, Chain of Thought Prompting demonstrated that the model could come up with plans to answer questions in arithmetic, common sense, and symbolic reasoning.
However, the model here is still a “static black box” because it uses its internal language representation to answer these questions, and this representation may not always be accurate or up-to-date which leads to fact hallucination (coming with facts from its own imagination) or error propagation (one error in the chain of thoughts propagates to a wrong answer).
Without the ability to take some sort of action and update its knowledge, the model is limited.
Acting Only Approach
There have also been studies that employed LLMs to do actions based on language, these studies usually take in multimodal inputs (audio, text, and images), convert them to text, use the model to generate in-domain actions, and then use a controller to do these actions.
Without the ability to plan some steps and reason about what to do, the model will simply output the wrong actions.
Combining both into ReAct
The proposal of this paper is to combine both methods mentioned above. ReAct prompts LLMs to generate both verbal reasoning traces and actions pertaining to a task in an interleaved manner, which allows the model to perform dynamic reasoning to create, maintain, and adjust high-level plans for acting (reason to act), while also interacting with external environments (e.g., Wikipedia) to incorporate additional information into reasoning (act to reason).
This is shown in the figure below:
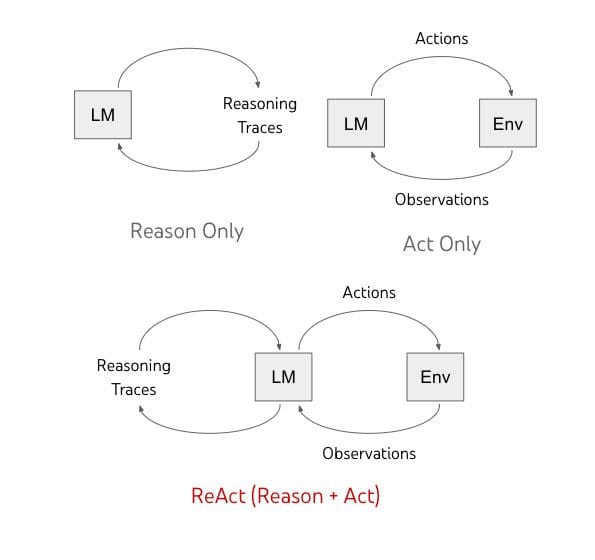
Difference between Reason, Act and ReAct (Photo taken from the paper)
The Action Space
So in order to make the reasoning prompting better, they design an action space, which means three actions that the model is allowed to use when answering questions.
This is done through a Wikipedia API that provides the following:
- search[entity]: returns the first 5 sentences from the corresponding entity wiki page if it exists, or else suggests top-5 similar entities from the Wikipedia search engine
- lookup[string], which would return the next sentence in the page containing the string, simulating Ctrl+F functionality on the browser
- finish[answer], which would finish the current task with the answer
Something that is not usual here is that there are way more powerful information retrieval tools than the ones mentioned above.
The goal behind this is to simulate human behavior and how a human would interact with Wikipedia and reason to find an answer.
Prompting
In addition to the provided tools, we need to properly prompt the LLM, to provide reasoning and properly chain actions.
To this end, they use a combination of thoughts that decompose a question like (“I need to search x, find y, then find z”), extract information from Wikipedia observations (“x was started in 1844”, “The paragraph does not tell x”), perform common sense (“x is not y, so z must instead be…”) or arithmetic reasoning (“1844 < 1989”), guide search reformulation (“maybe I can search/lookup x instead”), and synthesize the final answer (“…so the answer is x”)
Finally, the results look something like this:

How ReAct works and leads to better results (Photo taken from the paper)
Results
The datasets chosen for the evaluation are the following:
HotPotQA: is a question-answering dataset that requires reasoning over one or two Wikipedia pages.
FEVER: a fact verification benchmark where each claim is annotated SUPPORTS, REFUTES, or NOT ENOUGH INFO, based on whether there exists a Wikipedia passage to verify the claim.
ALFWorld: Text Based game that includes 6 types of tasks that the agent needs to perform to achieve a high-level goal.
An example would be “examine paper under desk lamp” by navigating and interacting with a simulated household via text actions (e.g. go to coffee table 1, take paper 2, use desk lamp 1)
WebShop: an online shopping website environment with 1.18M real-world products and 12k human instructions with much more variety and complexity.
It requires an agent to purchase a product based on user instructions. For example “I am looking for a nightstand with drawers. It should have a nickel finish, and be priced lower than $140”, the agent needs to achieve this through web interactions.
So the results show that ReAct always outperforms Act, which goes to show that the reasoning part is extremely important to enhance the actions.
On the other hand, ReAct outperforms CoT on Fever (60.9 vs. 56.3) and slightly lags behind CoT on HotpotQA (27.4 vs. 29.4). So for the FEVER dataset, acting to get updated knowledge is showing to give the needed boost to make the right SUPPORT or REFUTE decision.
When comparing CoT vs ReAct on HotpotQA and why the performance is comparable, these are the key observations found:
- Hallucination is a serious problem for CoT, so with no way to update its knowledge, CoT has to imagine and hallucinate things, which is a big hurdle.
- While interleaving reasoning, action, and observation steps improve ReAct’s groundedness and trustworthiness, such a structural constraint also reduces its flexibility in formulating reasoning steps. ReAct may force the LLM to do actions when just doing CoT is sometimes enough.
- For ReAct, successfully retrieving informative knowledge via search is critical. If search retrieves wrong information than automatically any reasoning based that false information is wrong, so getting the right information is crutial.

ReAct and CoT results on different datasets (Photo taken from the paper)
I hope this article helped you to understand this paper. You can check it out here https://arxiv.org/pdf/2210.03629.pdf
Implementations of ReAct exist already here and here.
Mohamed Aziz Belaweid is a Machine Learning / Data Engineer at SoundCloud. He is interested in both Research and Engineering. He like reading papers and actually bringing their innovation to life. He have worked on Language model training from scratch to specific domains. Extracting information from text using Named Entity Recognition, Multi Modal search systems, Image classification and detection. Also worked in operations side such as model deployment, reproducibility, scaling and inference.
Original. Reposted with permission.