What are Vector Databases and Why Are They Important for LLMs?
Large language models (LLMs) currently have the AI world in a chokehold. It is essential to understand why vector databases are important to LLMs.

Image by Editor
As you’re scanning through your timeline on Twitter, LinkedIn or news feeds - you’re probably seeing something about chatbots, LLMs, and GPT. A lot of people are speaking about LLMs, as new ones are getting released every week.
As we currently live amid the AI revolution, it is important to understand that a lot of these new applications rely on vector embedding. So let’s learn more about vector databases and why they are important to LLMs.
What is a Vector Database?
Let’s first define vector embedding. Vector embedding is a type of data representation that carries semantic information that helps AI systems get a better understanding of the data as well as being able to maintain long-term memory. With anything new you’re trying to learn, the important elements are understanding the topic and remembering it.
Embeddings are generated by AI models, such as LLMs which contain a large number of features that makes their representation difficult to manage. Embedding represents the different dimensions of the data, to help AI models understand different relationships, patterns, and hidden structures.
Vector embedding using traditional scalar-based databases is a challenge, as it cannot handle or keep up with the scale and complexity of the data. With all the complexity that comes with vector embedding, you can imagine the specialized database it requires. This is where vector databases come into play.
Vector databases offer optimized storage and query capabilities for the unique structure of vector embeddings. They provide easy search, high performance, scalability, and data retrieval all by comparing values and finding similarities between one another.
That sounds great, right? There’s a solution to dealing with the complex structure of vector embeddings. Yes, but no. Vector databases are very difficult to implement.
Until now, vector databases were only used by tech giants that had the capabilities to not only develop them but also be able to manage them. Vector databases are expensive, therefore ensuring that they are properly calibrated is important to provide high performance.
How do Vector Databases work?
So now we know a little bit about vector embeddings and databases, let’s go into how it works.
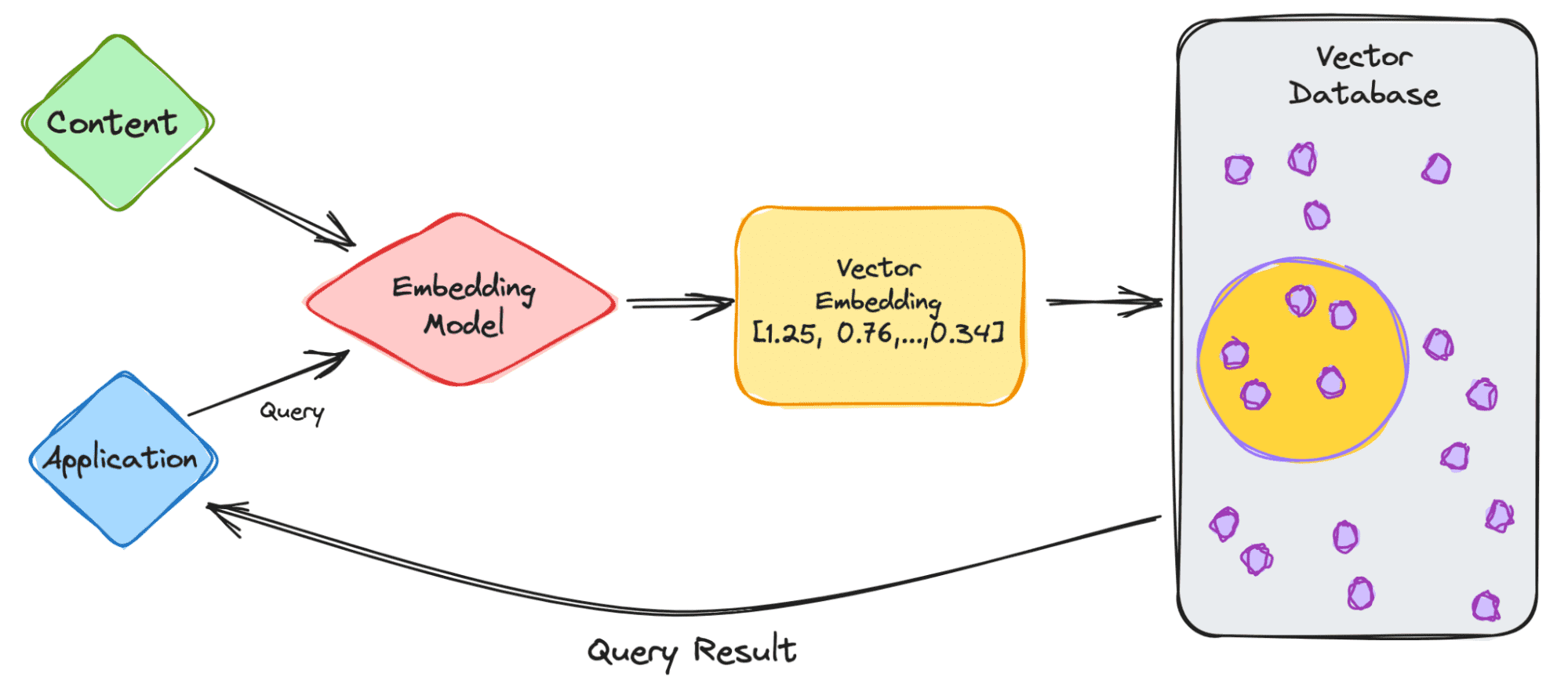
Image by Author
Let’s start with a simple example of dealing with an LLM such as ChatGPT. The model has large volumes of data with a lot of content, and they provide us with the ChatGPT application.
So let’s go through the steps.
- As the user, you will input your query into the application.
- Your query is then inserted into the embedding model which creates vector embeddings based on the content we want to index.
- The vector embedding then moves into the vector database, regarding the content that the embedding was made from.
- The vector database produces an output and sends it back to the user as a query result.
When the user continues to make queries, it will go through the same embedding model to create embeddings to query that database for similar vector embeddings. The similarities between the vector embeddings are based on the original content, in which the embedding was created.
Want to know more about how it works in the vector database? Let’s learn more.
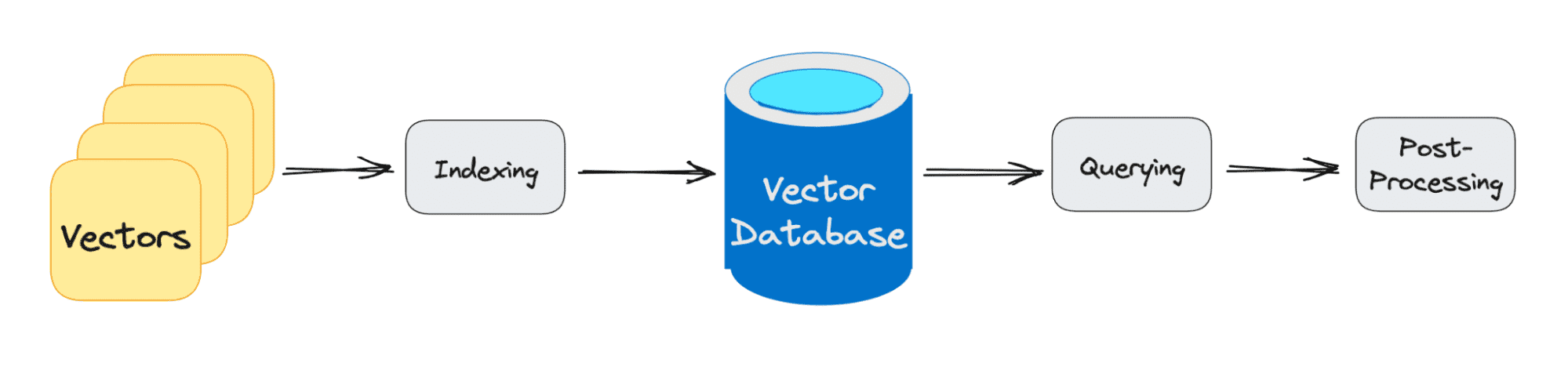
Image by Author
Traditional databases work with storing strings, numbers, etc in rows and columns. When querying from traditional databases, we are querying for rows that match our query. However, vector databases work with vectors rather than strings, etc. Vector databases also apply a similarity metric which is used to help find a vector most similar to the query.
A vector database is made up of different algorithms which all aid in the Approximate Nearest Neighbor (ANN) search. This is done via hashing, graph-based search, or quantization which are assembled into a pipeline to retrieve neighbors of a queried vector.
The results are based on how close or approximate it is to the query, therefore the main elements that are considered are accuracy and speed. If the query output is slow, the more accurate the result.
The three main stages that a vector database query goes through are:
1. Indexing
As explained in the example above, once the vector embedding moves into the vector database, it then uses a variety of algorithms to map the vector embedding to data structures for faster searching.
2. Querying
Once it has gone through its search, the vector database compares the queried vector to indexed vectors, applying the similarity metric to find the nearest neighbor.
3. Post Processing
Depending on the vector database you use, the vector database will post-process the final nearest neighbor to produce a final output to the query. As well as possibly re-ranking the nearest neighbors for future reference.
Wrapping it up
As we continue to see AI grow and new systems getting released every week, the growth in vector databases is playing a big role. Vector databases have allowed companies to interact more effectively with accurate similarity searches, providing better and faster outputs for users.
So next time you’re putting in a query in ChatGPT or Google Bard, think about the process it goes through to output a result for your query.
Nisha Arya is a Data Scientist, Freelance Technical Writer and Community Manager at KDnuggets. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.