The 5 Best Vector Databases You Must Try in 2024
The top vector databases are known for their versatility, performance, scalability, consistency, and efficient algorithms in storing, indexing, and querying vector embeddings for AI applications.
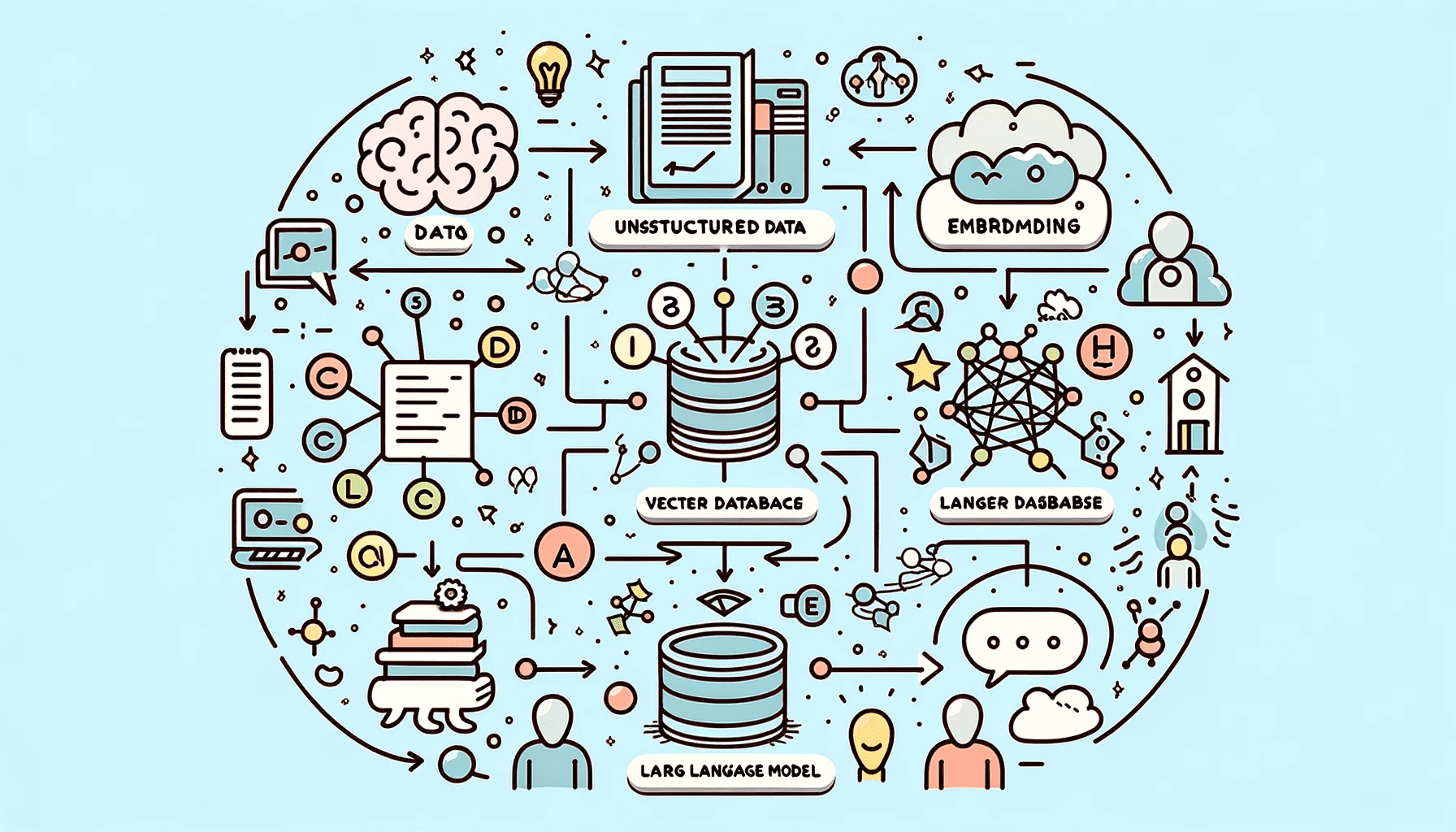
Image generated with DALL-E 3
Introduction
A vector database is a specialized type of database that is designed to store and index vector embeddings for efficient retrieval and similarity search. It is used in various applications that involve large language models, generative AI, and semantic search. Vector embeddings are mathematical representations of data that capture semantic information and allow for understanding patterns, relationships, and underlying structures.
Vector databases have become increasingly important in the field of AI applications, as they excel at handling high-dimensional data and facilitating complex similarity searches.
In this blog, we will explore the top five vector databases that you must try in 2024. These databases have been selected based on their scalability, versatility, and performance in handling vector data.
Image by Author
1. Qdrant
Qdrant is a open source vector similarity search engine and vector database that provides a production-ready service with a convenient API. You can store, search, and manage vector embeddings. Qdrant is tailored to support extended filtering, which makes it useful for a wide variety of applications that involve neural network or semantic-based matching, faceted search, and more. As it is written in the reliable and fast programming language Rust, Qdrant can handle high user loads efficiently.
By using Qdrant, you can build full applications with embedding encoders for tasks like matching, searching, recommending, and beyond. It is also available as Qdrant Cloud, a fully managed version including a free tier, providing an easy way for users to leverage its vector search abilities in their projects.
2. Pinecone
Pinecone is a managed vector database that has been specifically designed to tackle the challenges associated with high-dimensional data. With advanced indexing and search capabilities, Pinecone enables data engineers and data scientists to build and deploy large-scale machine learning applications that can efficiently process and analyze high-dimensional data.
Key features of Pinecone include a fully managed service that is highly scalable, enabling real-time data ingestion and low-latency search. Pinecone also provides integration with LangChain to enable natural language processing applications. With its specialized focus on high-dimensional data, Pinecone provides an optimized platform for deploying impactful machine learning projects.
3. Weaviate
Weaviate is an open-source vector database that allows you to store data objects and vector embeddings from your favorite ML models, scaling seamlessly into billions of data objects. With Weaviate, you get speed - it can quickly search ten nearest neighbors from millions of objects in just a few milliseconds. There is flexibility to vectorize data during import or upload your own vectors, leveraging modules that integrate with platforms like OpenAI, Cohere, HuggingFace, and more.
Weaviate focuses on scalability, replication, and security for production readiness, from prototypes to large-scale deployment. Beyond fast vector searches, Weaviate also offers recommendations, summarizations, and neural search framework integrations. It provides a flexible and scalable vector database for a variety of use cases.
4. Milvus
Milvus is a powerful open-source vector database for AI applications and similarity search. It makes unstructured data search more accessible and provides a consistent user experience regardless of deployment environment.
Milvus 2.0 is a cloud-native vector database with storage and computation separated by design, using stateless components for enhanced elasticity and flexibility. Released under Apache License 2.0, Milvus offers millisecond search on trillion vector datasets, simplified unstructured data management through rich APIs and consistent experience across environments, and embedded real-time search in applications. It is highly scalable and elastic, supporting component-level scaling on demand.
Milvus pairs scalar filtering with vector similarity for a hybrid search solution. With community support and over 1,000 enterprise users, Milvus provides a reliable, flexible, and scalable open-source vector database for a variety of use cases.
5. faiss
Faiss is an open-source library for efficient similarity search and clustering of dense vectors, capable of searching massive vector sets exceeding RAM capacity. It contains several methods for similarity search based on vector comparisons using L2 distances, dot products, and cosine similarity. Some methods like binary vector quantization enable compressed vector representations for scalability, while others like HNSW and NSG use indexing for accelerated search.
Faiss is primarily coded in C++ but integrates fully with Python/NumPy. Key algorithms are available for GPU execution, accepting input from CPU or GPU memory. The GPU implementation enables drop-in replacement of CPU indexes for faster results, automatically handling CPU-GPU copies. Developed by Meta's Fundamental AI Research group, Faiss provides an open-source toolkit empowering swift search and clustering within large vector datasets, on both CPU and GPU infrastructure.
Conclusion
Vector databases are quickly becoming an essential component of modern AI applications. As we have explored in this blog post, there are several compelling options to consider when selecting a vector database in 2024. Qdrant offers versatile open-source capabilities, Pinecone provides a managed service designed for high-dimensional data, Weaviate focuses on scalability and flexibility, Milvus delivers consistent experiences across environments, and faiss enables efficient similarity search through optimized algorithms.
Each database has its own strengths and benefits depending on your use case and infrastructure. As AI models and semantic search continue to advance, having the right vector database to store, index, and query vector embeddings will be key. You can learn more about vector databases by reading What are Vector Databases and Why Are They Important for LLMs?
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in technology management and a bachelor's degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.