Understanding Machine Learning Algorithms: An In-Depth Overview
Understanding Machine Learning: Exposing the Tasks, Algorithms, and Selecting the Best Model.

Image by Author
Machine Learning. Quite an impressive block of words, am I right? Since AI and its tools, like ChatGPT, and Bard, booming right now, it is time to go deeper and learn the fundamentals.
These fundamental concepts might not enlighten you at once, yet if you are interested in the concepts, you will have further links to go even deeper.
Machine Learning’s strength comes from its complex algorithms, which are stated at the core of every Machine learning project. Sometimes these algorithms even draw inspiration from human cognition, like speech recognition or face recognition.
In this article, we will go through an explanation of the machine learning classes first, like supervised, unsupervised, and reinforcement learning.
Then, we will go into the tasks handled by Machine Learning, names are Classification, Regression, and Clustering.
After that, we will deeply discover Decision trees, Support Vector Machines, and K-Nearest Neighbours, and Linear Regression, visually, and definitions.
But of course, how can you choose the best algorithm, that will be aligned with your needs? Of course, understanding concepts like “understanding data” or “defining your problem” will guide you through tackling possible challenges and roadblocks in your project.
Let’s start the journey of Machine Learning!
Categories of Machine Learning
When we are exploring Machine Learning, we can see there are three major categories that shape its framework.
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning.
In supervised learning, the label, that you want to predict is in the dataset.
In this scenario, the algorithm acts like a careful learner, associating features with corresponding outputs. After the learning phase is over, it can project the output for the new data, and test data. Consider scenarios like tagging spam emails or predicting house prices.
Imagine studying without a mentor next; it must be daunting. Unsupervised learning methods particularly do this, making predictions without labels.
They bravely go into the unknown, discovering hidden patterns and structures in unlabeled data, similar to explorers discovering lost artifacts.
Understanding genetic structure in biology and client segmentation in marketing is unsupervised learning examples.
Finally, we reach Reinforcement Learning, where the algorithm learns by making mistakes, much like a little puppy. Imagine teaching a pet: Misbehavior is discouraged, while good behavior is rewarded.
Similar to this, the algorithm takes actions, experiences rewards or penalties, and eventually figures out how to optimize. This strategy is frequently used in industries like robotics and video games.
Types of Machine Learning
Here we will divide Machine algorithms into three subsections. These subsections are Classification, Regression, and Clustering.
Classification
As the name shows, classification focuses on the process of grouping or categorizing items. Think of yourself as a botanist assigned with classifying plants into benign or dangerous categories based on a variety of features. It's similar to sorting sweets into different jars based on their colors.
Regression
Regression is the next step; think of it as an attempt to predict numerical variables.
The goal in this situation is to predict a certain variable, such as the cost of a property in considering its features (number of rooms, location, etc.).
It is similar to figuring out a fruit's large quantities using its dimensions because there are no clearly defined categories but rather a continuous range.
Clustering
We now reach Clustering, which is comparable to organizing disorganized clothing. Even if you lack preset categories (or labels), you still put related objects together.
Imagine an algorithm that, with no prior knowledge of the subjects involved, classifies news stories based on those themes. Clustering is obvious there!
Let's analyze some popular algorithms that do these jobs because there is still much more to explore!
Popular Machine Learning Algorithms
Here, we will go deeper into popular Machine Learning algorithms, like Decision Trees, Support Vector Machines, K-Nearest Neighbors, and Linear Regression.
A. Decision Tree
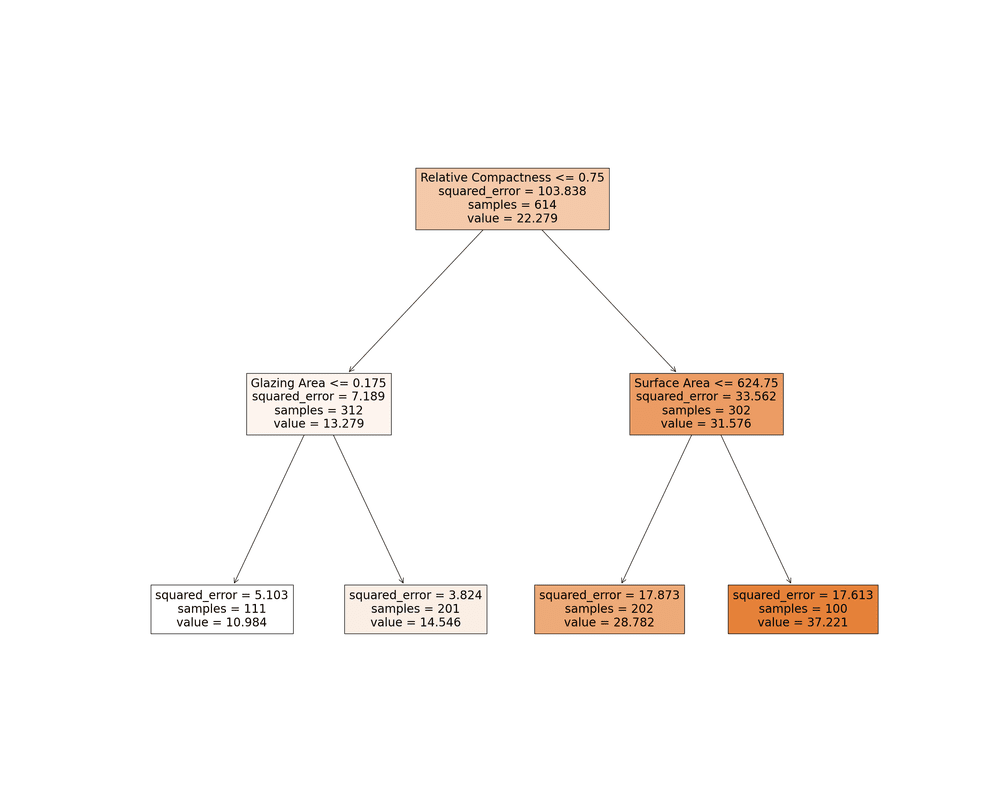
Image by Author
Think about planning an outdoor event and having to decide whether to go forward or call it off dependent on the weather. A Decision Tree may be used to represent this decision-making process.
A Decision Tree method in the field of machine learning (ML) asks a series of binary questions about the data (for example, "Is it precipitating?") until it comes to a decision (continue the collection or stop it). This method is very useful when we need to understand the reasoning behind a prediction.
If you want to learn more about decision trees, you can read Decision Tree and Randon Forest Algorithm (basically decision tree on steroids).
B. Support Vector Machines (SVM)
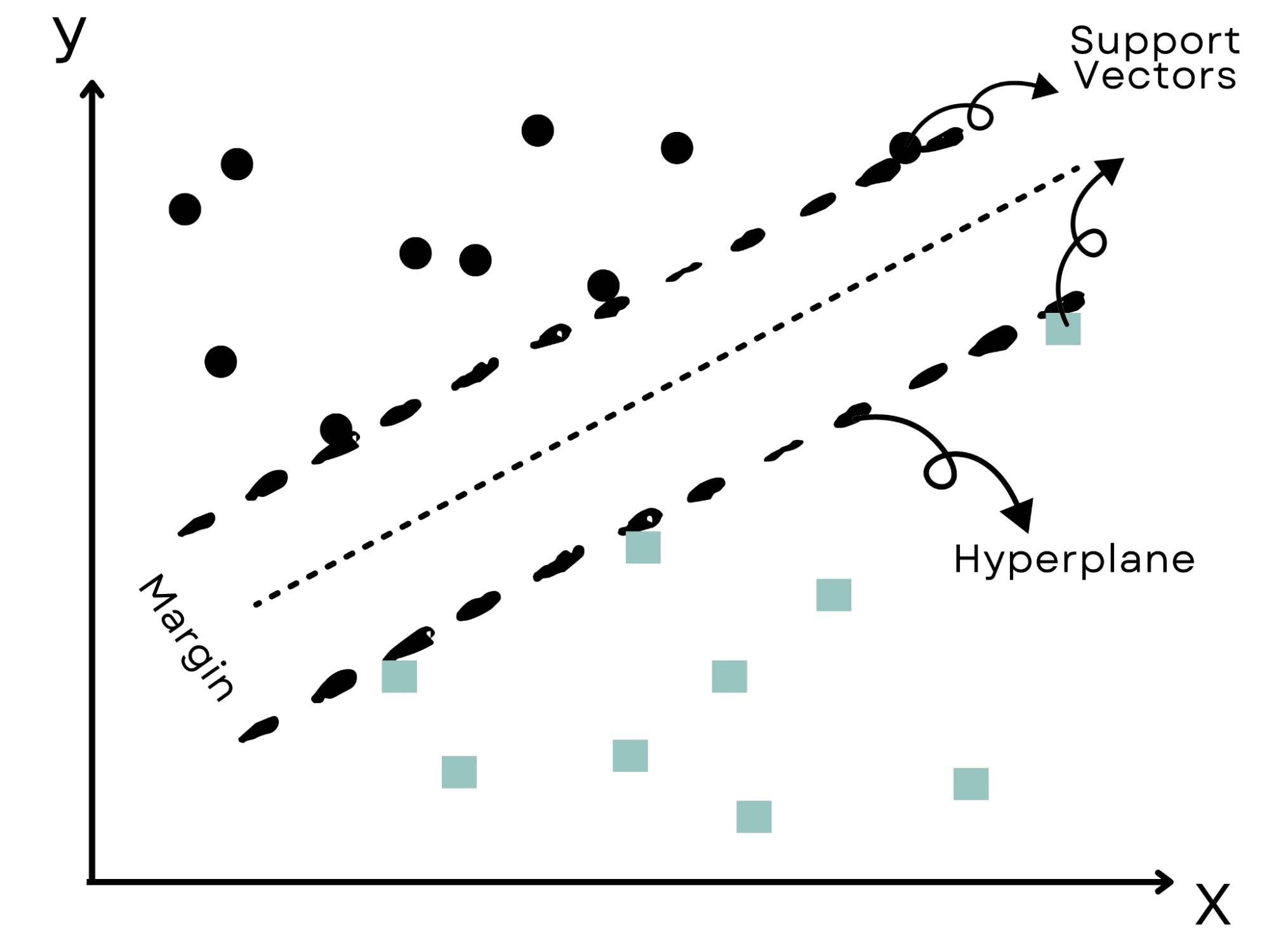
Image by Author
Imagine a scenario similar to the Wild West where the aim is to divide two rival groups.
To avoid any conflicts, we would choose the biggest practical border; this is exactly what Support Vector Machines (SVM) do.
They identify the most effective 'hyperplane' or border that divides data into clusters while keeping the greatest distance from the nearest data points.
Here, you can find more information about SVM.
C. K-Nearest Neighbors (KNN)
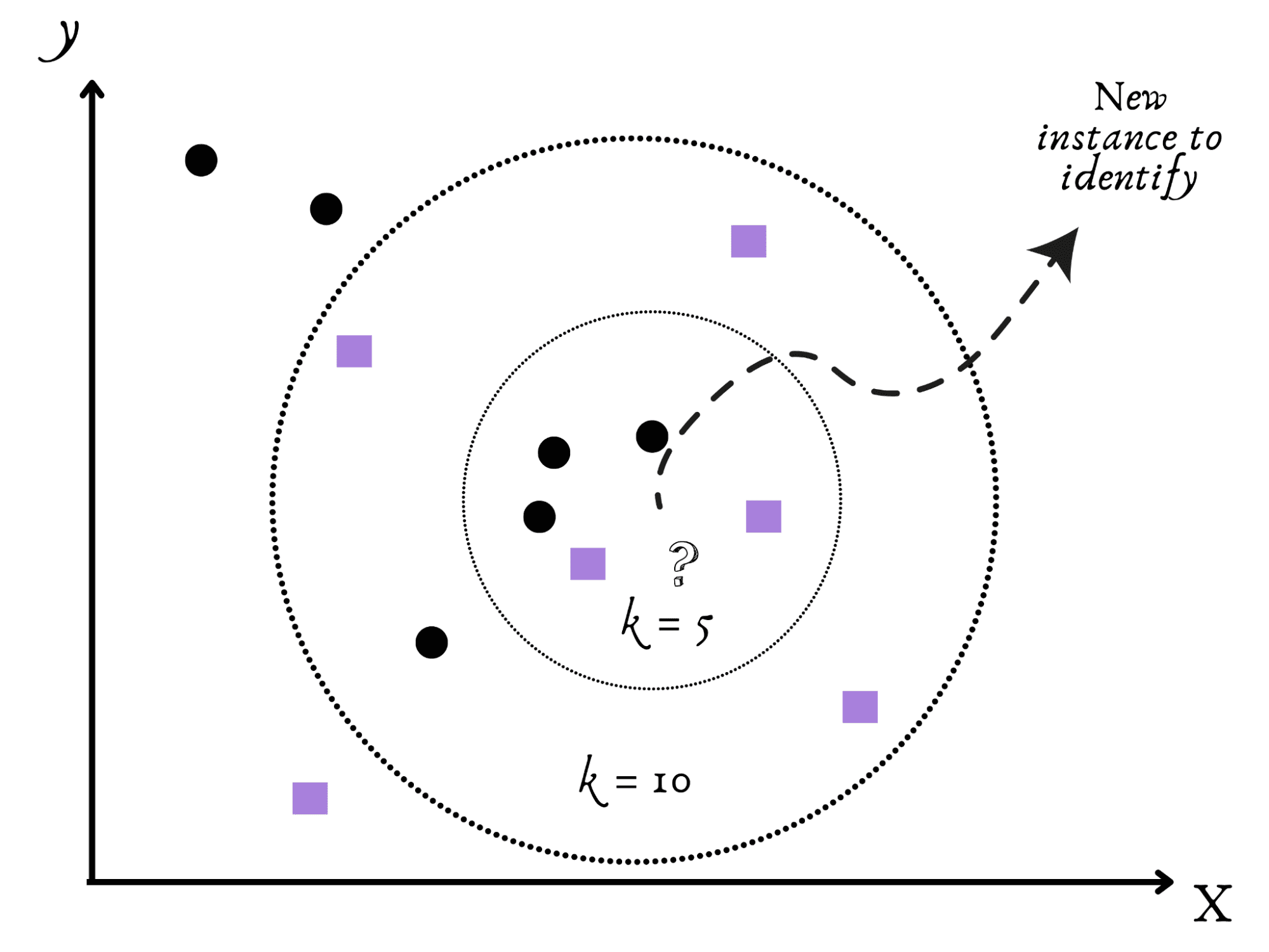
Image by Author
The K-Nearest Neighbors (KNN), a friendly and social algorithm, comes next.
Imagine moving to a new town and trying to figure out if it is quiet or busy.
It seems sense that your natural course of action would be to monitor your nearest neighbors to gain understanding.
Similar to this, KNN classifies fresh data according to the arguments, such as k, of its close neighbors in the data set.
Here you can know more about KNN.
D. Linear Regression
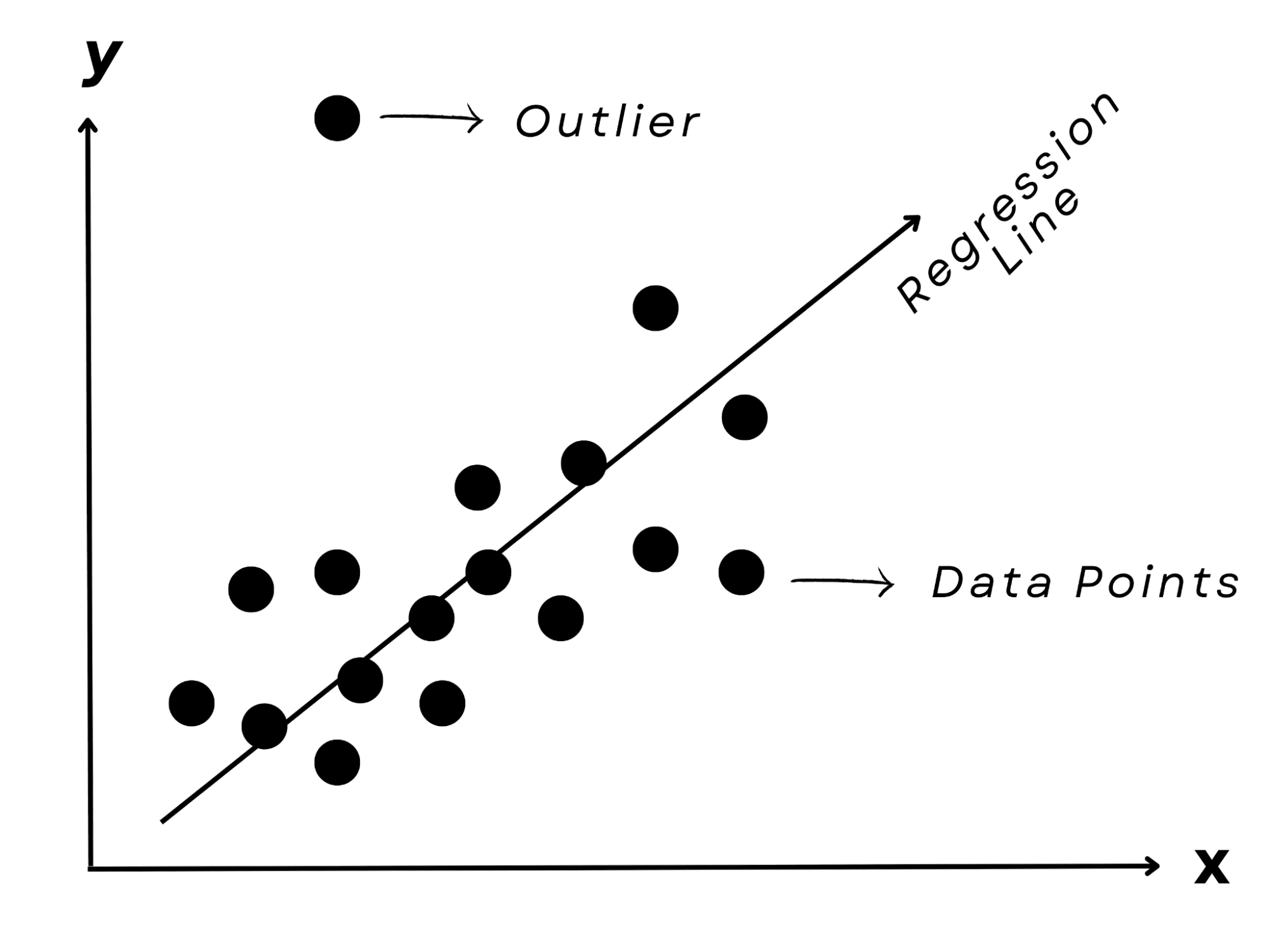
Image by Author
Lastly, imagine trying to predict a friend's exam result based on the number of hours they studied. You'd probably notice a pattern: more time spent studying usually results in better results.
A linear regression model, which, as its name indicates, represents the linear connection between the input (study hours) and the output (test score), can capture this correlation.
It is a favorite approach for predicting numerical values, such as real estate costs or stock market values.
For more about linear regression, you can read this article.
Choosing The Right Machine Learning Model
Choosing the right algorithm from all of the options at your disposal might feel like trying to find a needle in a very large haystack. But don't worry! Let's clarify this process with some important things to think about.
A. Understand Your Data
Consider your data to be a treasure map that contains clues to the best algorithm.
- Do you have labels on your data? (Supervised vs Unsupervised Learning)
- How many features does it include? (Do we need dimension reduction?)
- Is it categorical or numerical? ( Classification or Regression?)
These questions' answers might point you in the right way. In contrast, unlabeled data might encourage unsupervised learning algorithms like clustering. For instance, labeled data encourages the usage of supervised learning algorithms like Decision Trees.
B. Define Your Problem
Imagine using a screwdriver to drive a nail; not very effective, is it?
The right "tool" or algorithm may be chosen by clearly defining your problem. Is your goal to identify hidden patterns (clustering), forecast a category (classification), or a metric (regression)?
There are compatible algorithms for every task type.
C. Consider Practical Aspects
An ideal algorithm may occasionally perform poorly in actual applications than it does in theory. The amount of data you have, the available computational resources, and the need for the results all play important roles.
Remember that certain algorithms, like KNN, could perform poorly with large datasets, while others, like Naive Bayes, might do well with complex data.
D. Never Underestimate Evaluation
Finally, it's crucial to evaluate and validate the performance of your model. You want to make sure the algorithm works effectively with your data, similar to trying on clothing before making a purchase.
This 'fit' may be measured using a variety of measures, such as accuracy for classification tasks or mean squared error for regression tasks.
Conclusion
Haven't we traveled quite a distance?
As with categorizing a library into different genres, we started by dividing the field of machine learning into Supervised, Unsupervised, and Reinforcement Learning. Then, in order to understand the diversity of books within these genres, we went further into the sorts of tasks like classification, regression, and clustering, that fall under these headings.
We got to know some of the ML algorithms first, which include Decision Trees, Support Vector Machines, K-Nearest Neighbors, Naive Bayes, and Linear Regression. Each of these algorithms has its own specialties and strengths.
We also realized that choosing the right algorithm is like casting the ideal actor for a part, taking into account data, the nature of the issue, real-world applications, and performance evaluation.
Every machine Learning project offers a distinct journey, just as every book gives a new narrative.
Keep in mind that learning, experimenting, and improving are more important than always doing it right the first time.
So get ready, put on your data scientist cap, and go on your very own ML adventure!
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.