Data Science Basics: Data Mining vs. Statistics
As a beginner I was confused at the relationship between data mining and statistics. This is my attempt to help straighten out this connection for others who may now be in my old shoes.

When I was first exposed to data mining and machine learning, I'll admit it: I thought it was magic. Make significant predictions with accuracy? Sorcery! Curiosity, however, quickly leads you to discover that everything is above board, and sound scientific and statistical methods bear the responsibility.
But this ends up leading to more questions in the short term. Machine learning. Data mining. Statistics. Data science. The concepts and terminology are overlapping and seemingly repetitive at times. While there are numerous attempts at clarifying much of this (permanently unsettled) uncertainty, this post will tackle the relationship between data mining and statistics.
Statistics is the analysis, interpretation and presentation of numeric facts or data. The field of statistics employs numerous statistical methods for accomplishing these goals.
Data mining is a multi-disciplinary field, the origins of which grew out of database technology, machine learning, artificial intelligence and statistics, among other fields. Data mining is the process of extracting hidden and previously unknown patterns from raw data, with the intent of turning these vast amounts of data into useful information.
Data mining is a multi-faceted process. It is true that statistical elements are utilized in the functions of data mining, including classification, clustering, regression and association. However, data mining encompasses a variety of tasks that are not statistical in nature. For example, data preparation, inspection and cleaning are of central importance in data mining, and are processes that when combined can account for more than 60% of all data mining time spent. Clearly, data preparation, in its most basic form, has little to do with statistics. However, and to complicate things, statistical analysis can be a useful tool for the data preparation process as well.
In this sense, we can say that data mining encompasses, among other strategies and responsibilities, statistics and statistical analysis elements. Other comparisons suggest that statistics and data mining lie on a shared continuum and that there is no clear separation between the two, but rather a blurred overlay. In either case, classical statistics and data mining clearly have much in common, while data mining involves practices well beyond simply those statistical in nature.
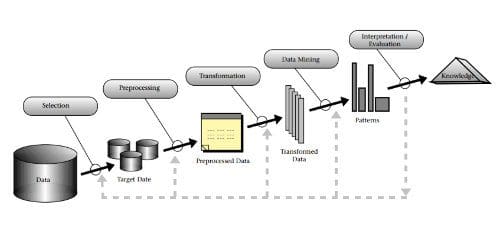
Consider the KDD Process. Though its intent is to describe an entire process for mining data, it contains a single step actually named "data mining" as well. Let's not let this confuse us; in the context of our above discussion, data mining, as we have described it, would refer to the entire process, while the single step called "data mining" would be the application of statistical methods used in the mining of data.
Confused yet?
It's an unfortunate situation. See, the KDD Process was actually intended to describe a Knowledge Discovery in Databases process, which kind of eventually became data mining, which kind of eventually became data science. Kind of.
So, looking at this again, we can, perhaps more logically, say that the KDD Process, when viewed as a mechanism for describing data science, contains a single step ("data mining") which employs statistical methods for the discovery of previously unknown patterns, the only part of the entire process which has any significant focus on statistics. The rest of process describes the remainder of data science, or what used to be more commonly referred to as data mining. This is a bit of a mess, granted, and it's rough around the edges, but it's an earnest attempt to help sort out the original comparison by way of relevant diagram. I'm sure some people will be upset with me...
Can we (possibly clarify and) summarize this nicely? KDnuggets' Gregory Piatetsky-Shapiro says this of the connection between the data mining and statistics, reinforcing the above:
Statistics is at the core of data mining - helping to distinguish between random noise and significant findings, and providing a theory for estimating probabilities of predictions, etc.
However Data Mining is more than Statistics. DM covers the entire process of data analysis, including data cleaning and preparation and visualization of the results, and how to produce predictions in real-time, etc.
Confused? Interested? For more of a discussion on data science processes, including KDD, read this. If you are interested in trying to better understand the differences between a subset of terminology involved in the data science puzzle, read this.
Related:
- Big Data, Bible Codes, and Bonferroni
- Understanding the Bias-Variance Tradeoff: An Overview
- The (Not So) New Data Scientist Venn Diagram