Back To Basics, Part Dos: Gradient Descent
Explore the inner workings of the powerful optimization algorithm.
Welcome to the second part of our Back To Basics series. In the first part, we covered how to use Linear Regression and Cost Function to find the best-fitting line for our house prices data. However, we also saw that testing multiple intercept values can be tedious and inefficient. In this second part, we’ll delve deeper into Gradient Descent, a powerful technique that can help us find the perfect intercept and optimize our model. We’ll explore the math behind it and see how it can be applied to our linear regression problem.
Gradient descent is a powerful optimization algorithm that aims to quickly and efficiently find the minimum point of a curve. The best way to visualize this process is to imagine you are standing at the top of a hill, with a treasure chest filled with gold waiting for you in the valley.
However, the exact location of the valley is unknown because it’s super dark out and you can’t see anything. Moreover, you want to reach the valley before anyone else does (because you want all of the treasure for yourself duh). Gradient descent helps you navigate the terrain and reach this optimal point efficiently and quickly. At each point it’ll tell you how many steps to take and in what direction you need to take them.
Similarly, gradient descent can be applied to our linear regression problem by using the steps laid out by the algorithm. To visualize the process of finding the minimum, let’s plot the MSE curve. We already know that the equation of the curve is:
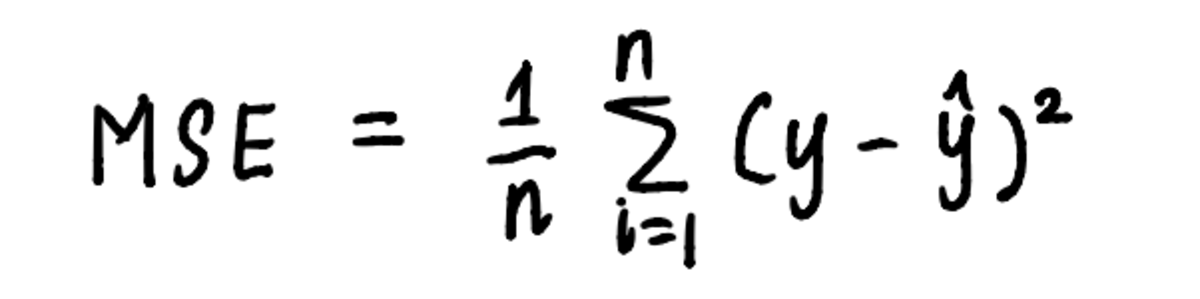
the equation of the curve is the equation used to calculate the MSE
And from the previous article, we know that the equation of MSE in our problem is:

If we zoom out we can see that an MSE curve (which resembles our valley) can be found by substituting a bunch of intercept values in the above equation. So let’s plug in 10,000 values of the intercept, to get a curve that looks like this:
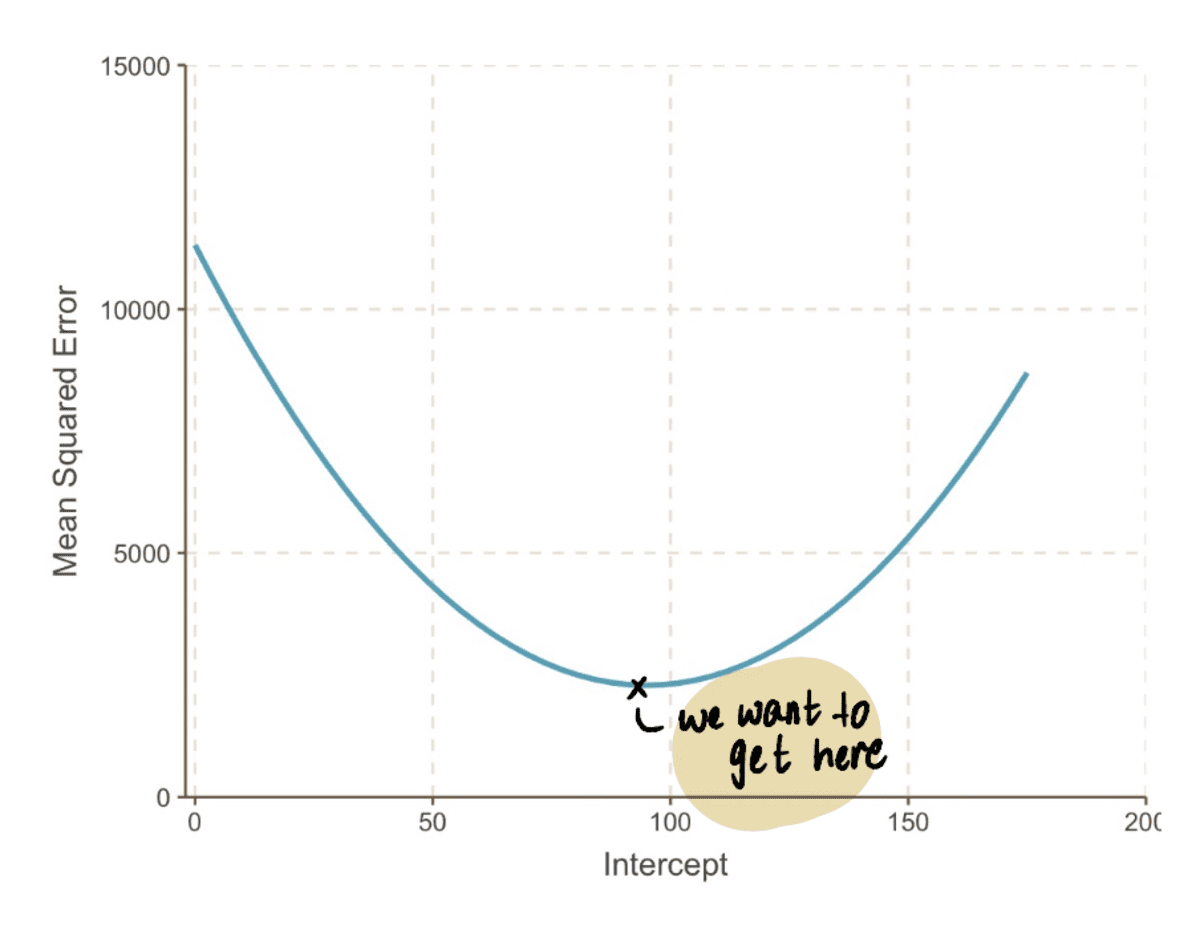
in reality, we won’t know what the MSE curve looks like
The goal is to reach the bottom of this MSE curve, which we can do by following these steps:
Step 1: Start with a random initial guess for the intercept value
In this case, let’s assume our initial guess for the intercept value is 0.
Step 2: Calculate the gradient of the MSE curve at this point
The gradient of a curve at a point is represented by the tangent line (a fancy way of saying that the line touches the curve only at that point) at that point. For example, at Point A, the gradient of the MSE curve can be represented by the red tangent line, when the intercept is equal to 0.
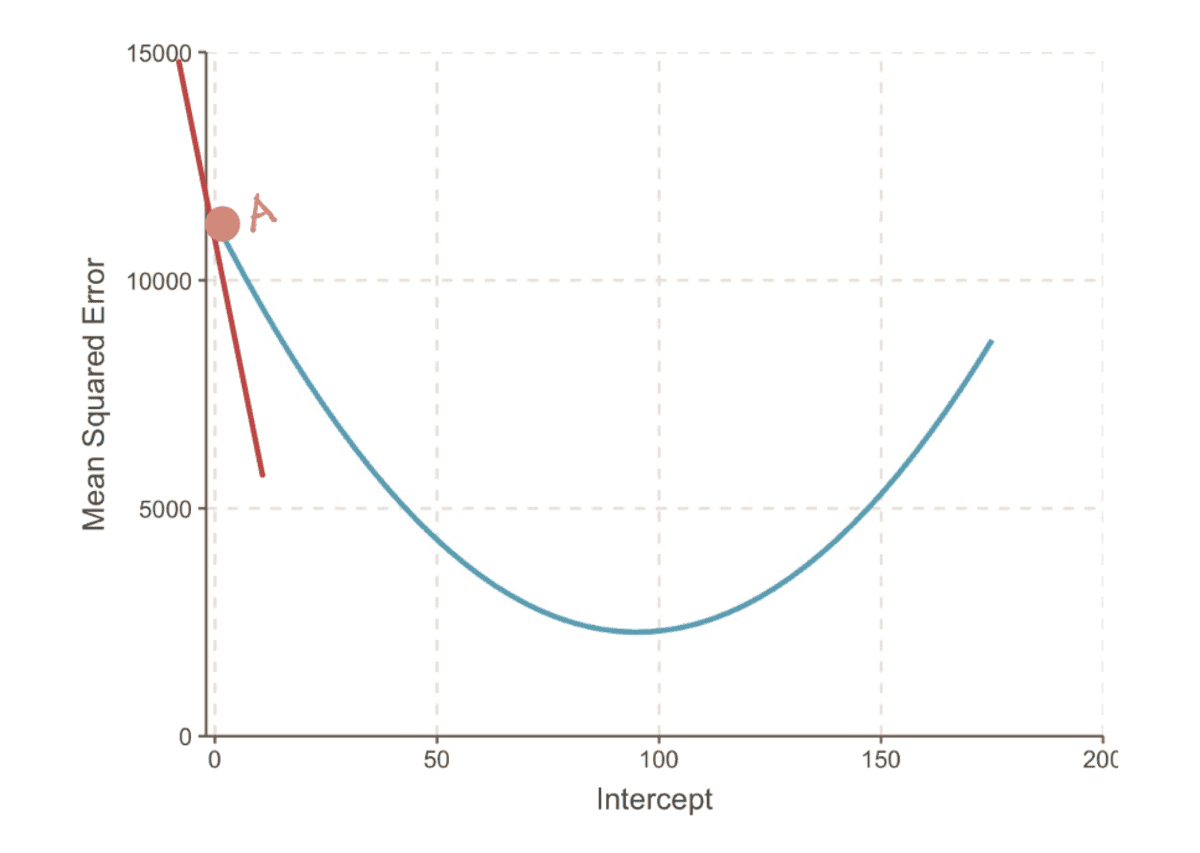
the gradient of the MSE curve when intercept = 0
In order to determine the value of the gradient, we apply our knowledge of calculus. Specifically, the gradient is equal to the derivative of the curve with respect to the intercept at a given point. This is denoted as:
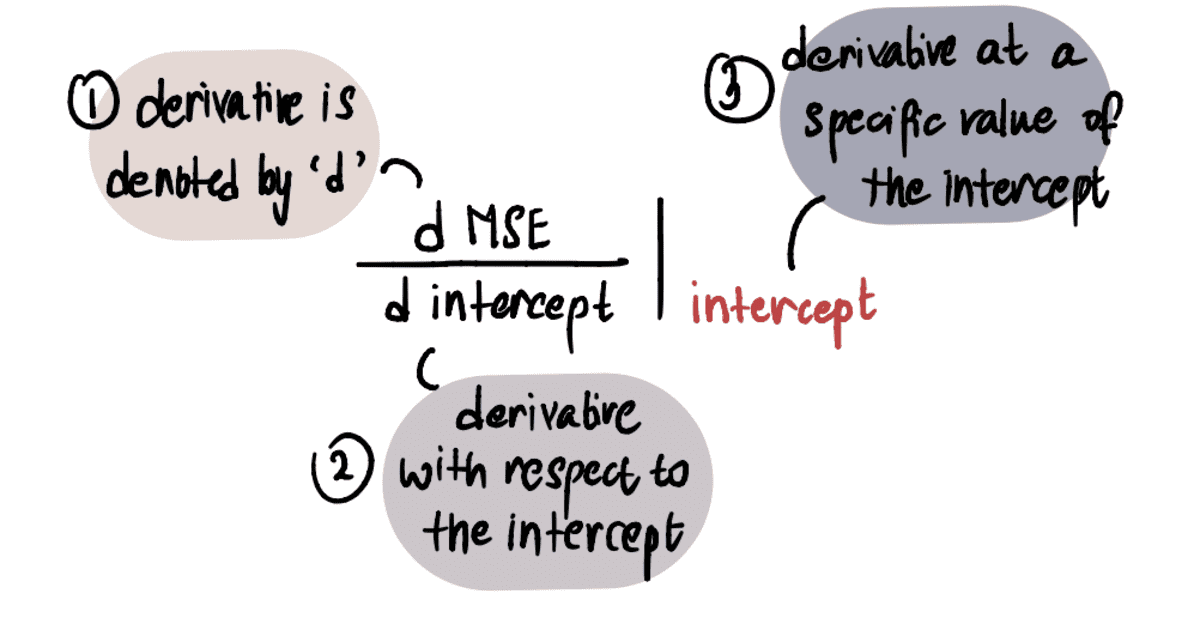
NOTE: If you’re unfamiliar with derivatives, I recommend watching this Khan Academy video if interested. Otherwise you can glance over the next part and still be able to follow the rest of the article.
We calculate the derivative of the MSE curve as follows:
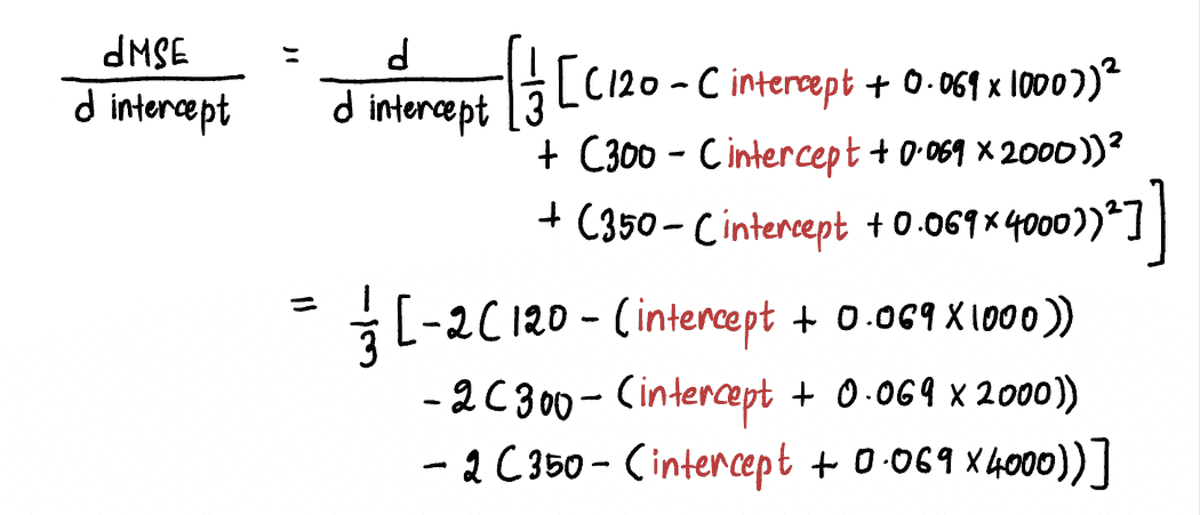
Now to find the gradient at point A, we substitute the value of the intercept at point A in the above equation. Since intercept = 0, the derivative at point A is:
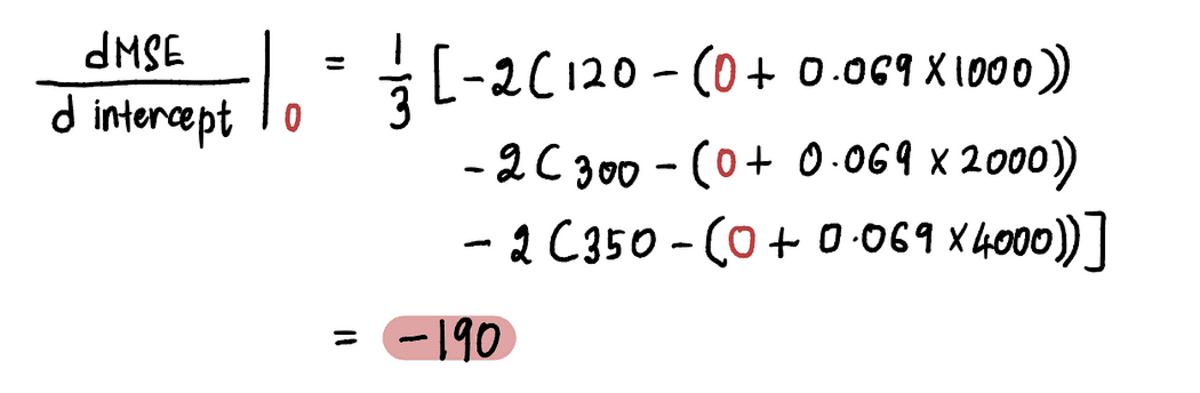
So when the intercept = 0, the gradient = -190
NOTE: As we approach the optimal value, the gradient values approach zero. At the optimal value, the gradient is equal to zero. Conversely, the farther away we are from the optimal value, the larger the gradient becomes.
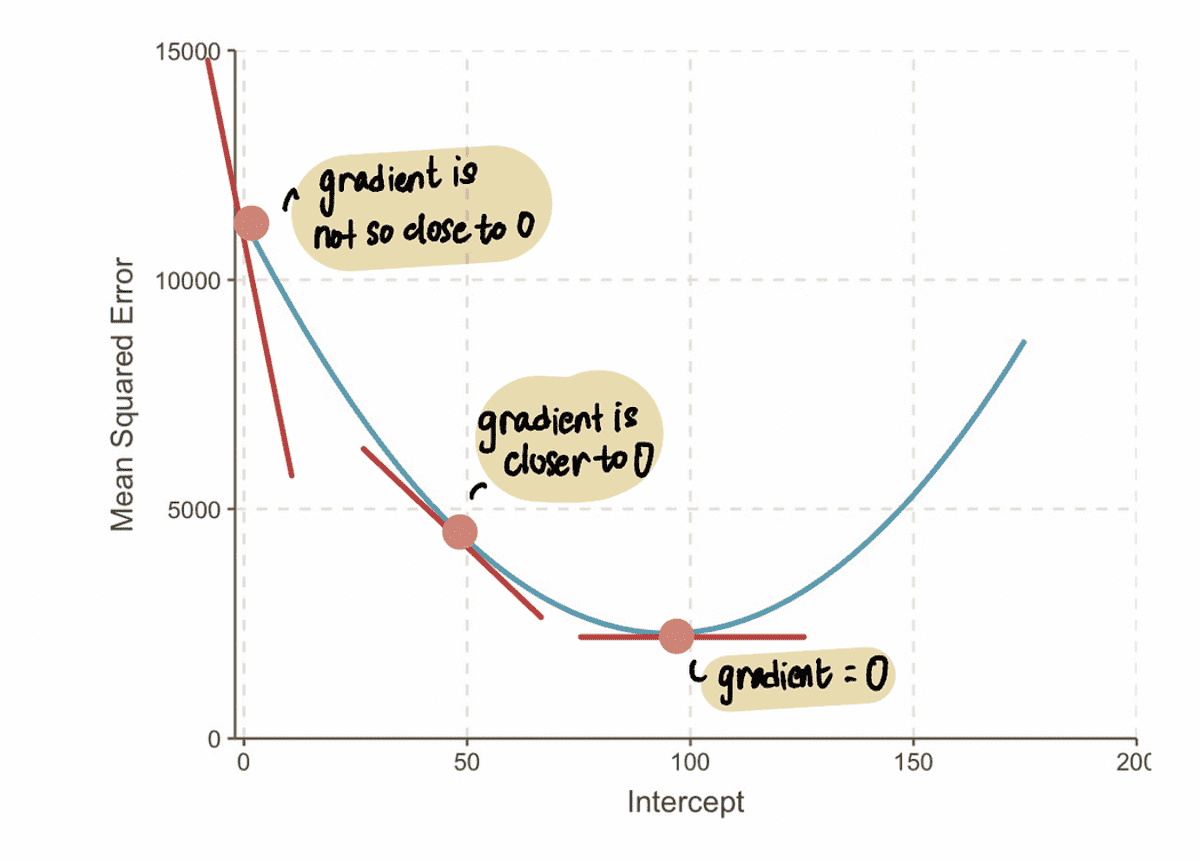
From this, we can infer that the step size should be related to the gradient, since it tells us if we should take a baby step or a big step. This means that when the gradient of the curve is close to 0, then we should take baby steps because we are close to the optimal value. And if the gradient is bigger, we should take bigger steps to get to the optimal value faster.
NOTE: However, if we take a super huge step, then we could make a big jump and miss the optimal point. So we need to be careful.
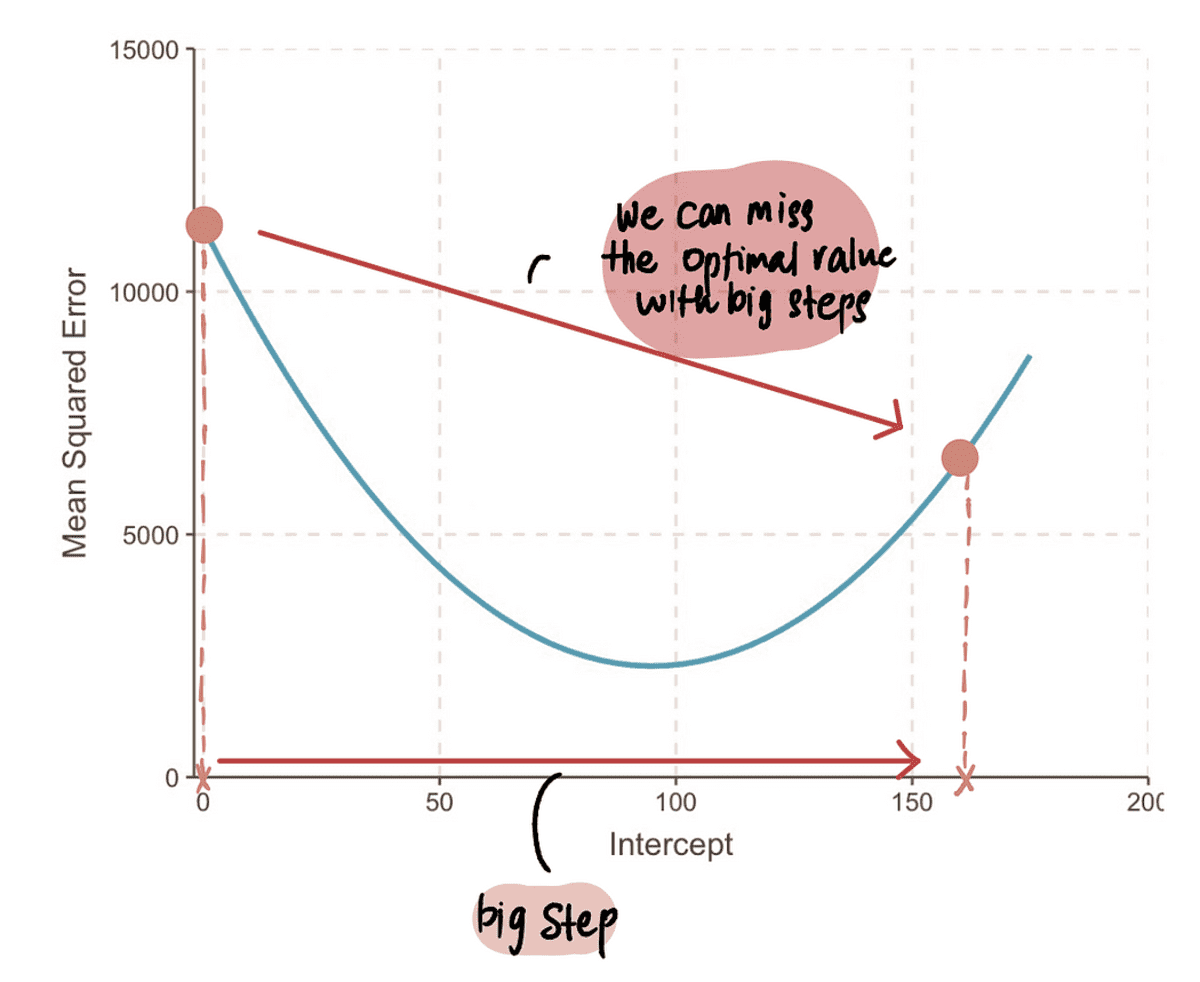
Step 3: Calculate the Step Size using the gradient and the Learning Rate and update the intercept value
Since we see that the Step Size and gradient are proportional to each other, the Step Size is determined by multiplying the gradient by a pre-determined constant value called the Learning Rate:

The Learning Rate controls the magnitude of the Step Size and ensures that the step taken is not too large or too small.
In practice, the Learning Rate is usually a small positive number that is ? 0.001. But for our problem let’s set it to 0.1.
So when the intercept is 0, the Step Size = gradient x Learning Rate = -190*0.1 = -19.
Based on the Step Size we calculated above, we update the intercept (aka change our current location) using any of these equivalent formulas:

To find the new intercept in this step, we plug in the relevant values…
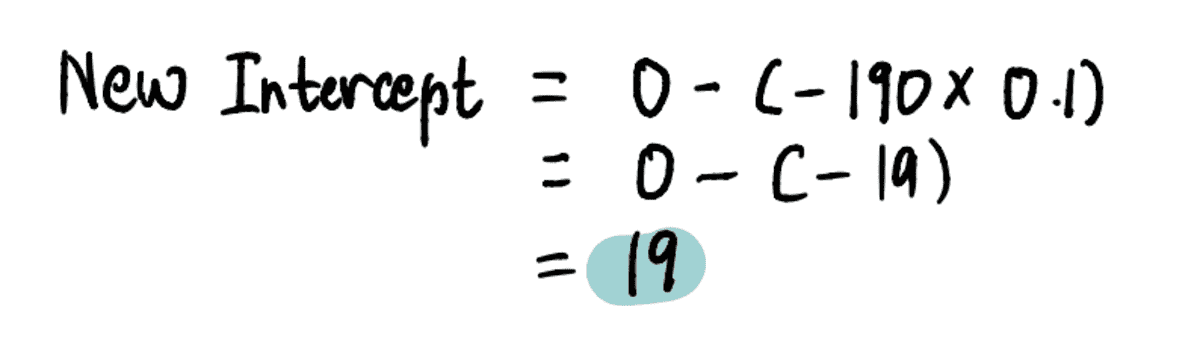
…and find that the new intercept = 19.
Now plugging this value in the MSE equation, we find that the MSE when the intercept is 19 = 8064.095. We notice that in one big step, we moved closer to our optimal value and reduced the MSE.
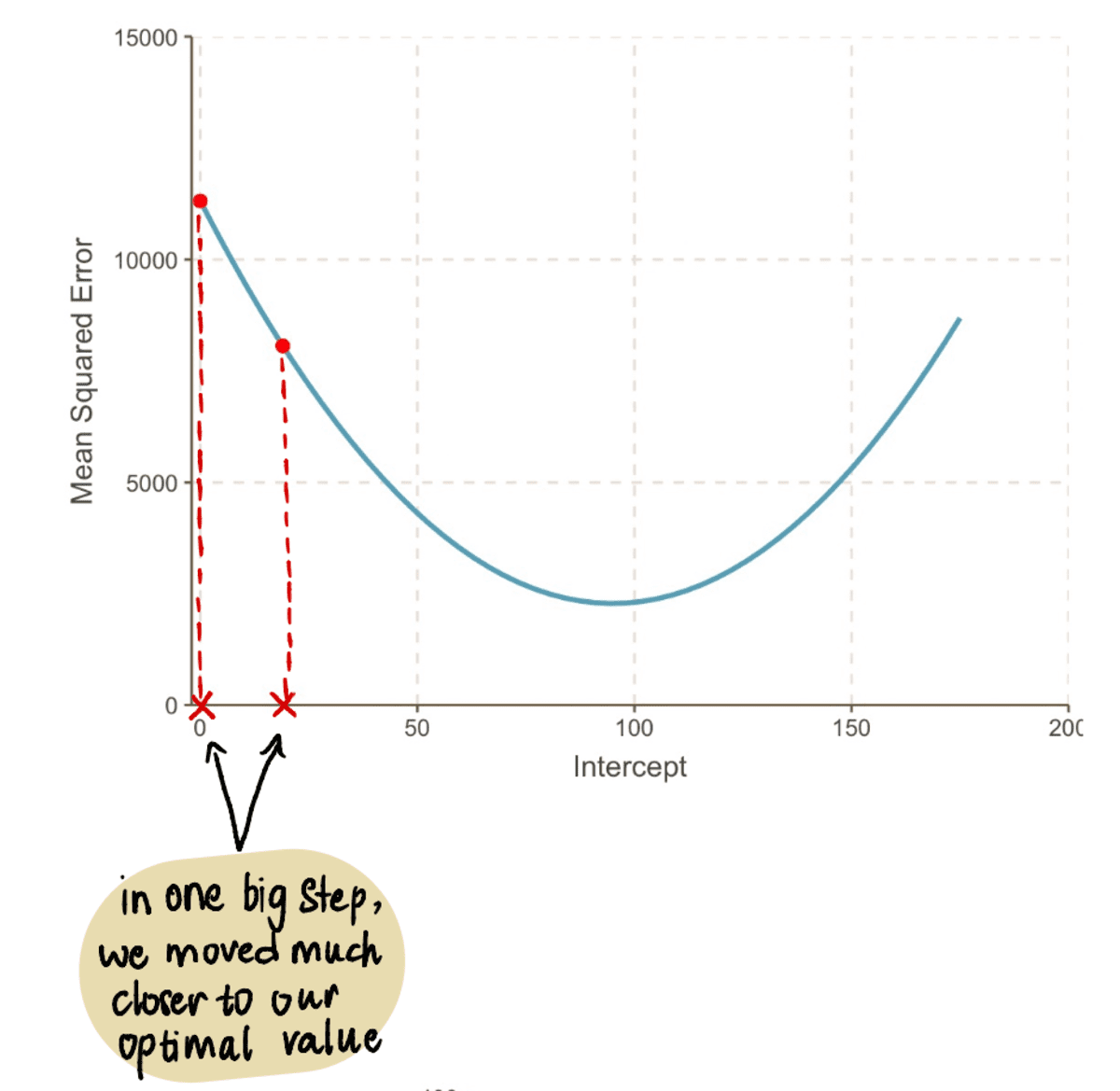
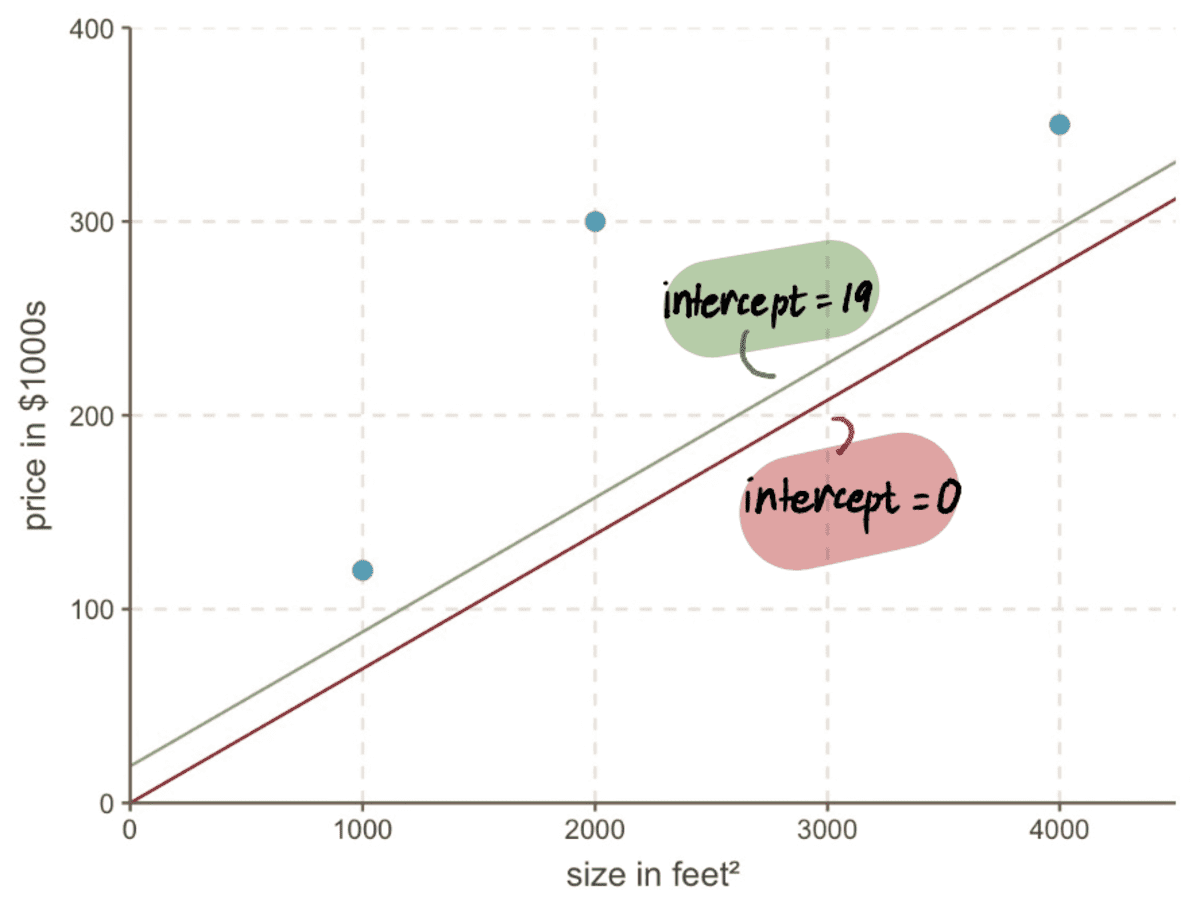
Even if we look at our graph, we see how much better our new line with intercept 19 is fitting our data than our old line with intercept 0:
Step 4: Repeat steps 2–3
We repeat Steps 2 and 3 using the updated intercept value.
For example, since the new intercept value in this iteration is 19, following Step 2, we will calculate the gradient at this new point:
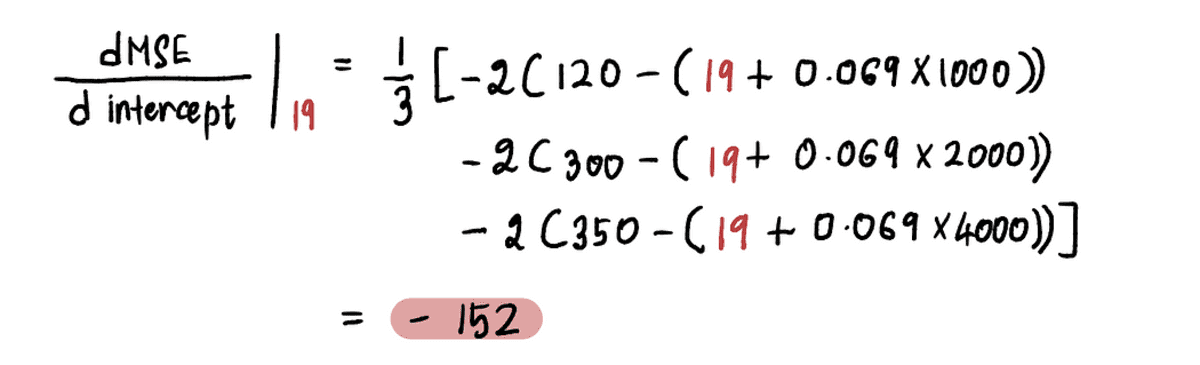
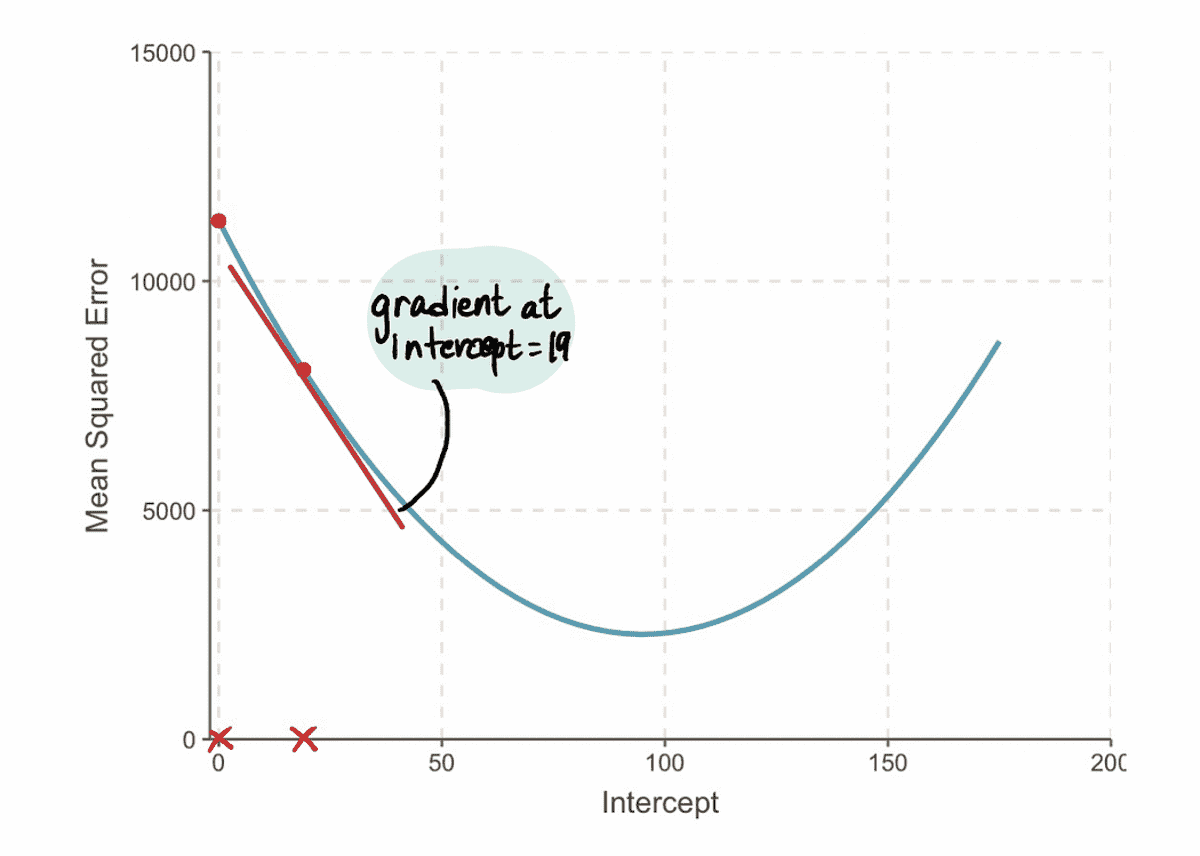
And we find that the gradient of the MSE curve at the intercept value of 19 is -152 (as represented by the red tangent line in the illustration below).
Next, in accordance with Step 3, let’s calculate the Step Size:
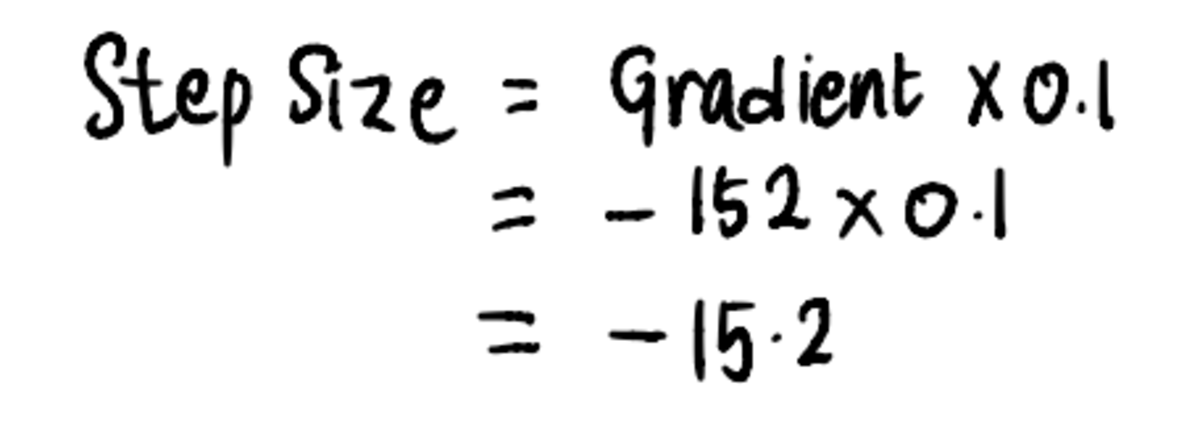
And subsequently, update the intercept value:
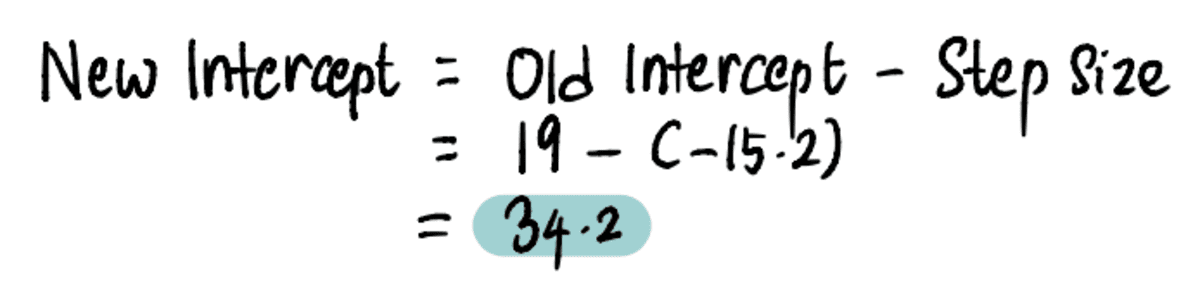
Now we can compare the line with the previous intercept of 19 to the new line with the new intercept 34.2…
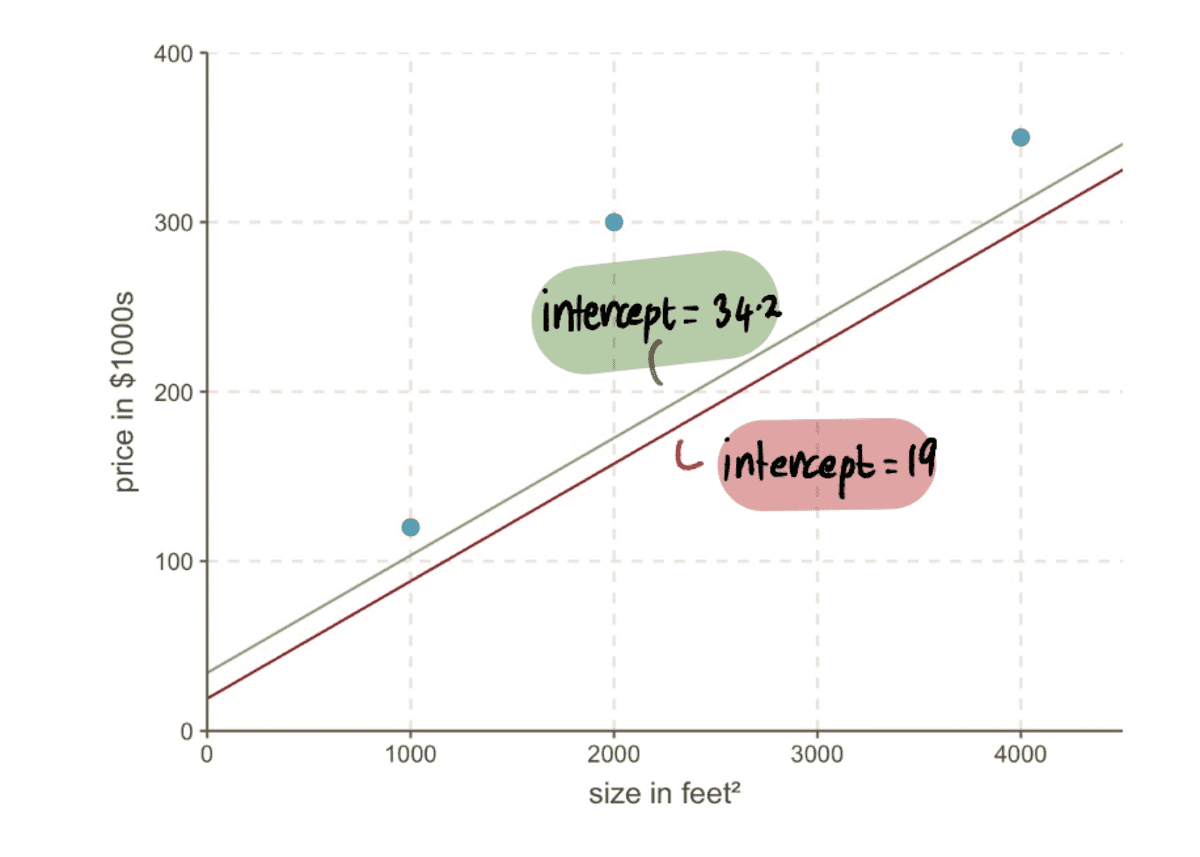
…and we can see that the new line fits the data better.
Overall, the MSE is getting smaller…
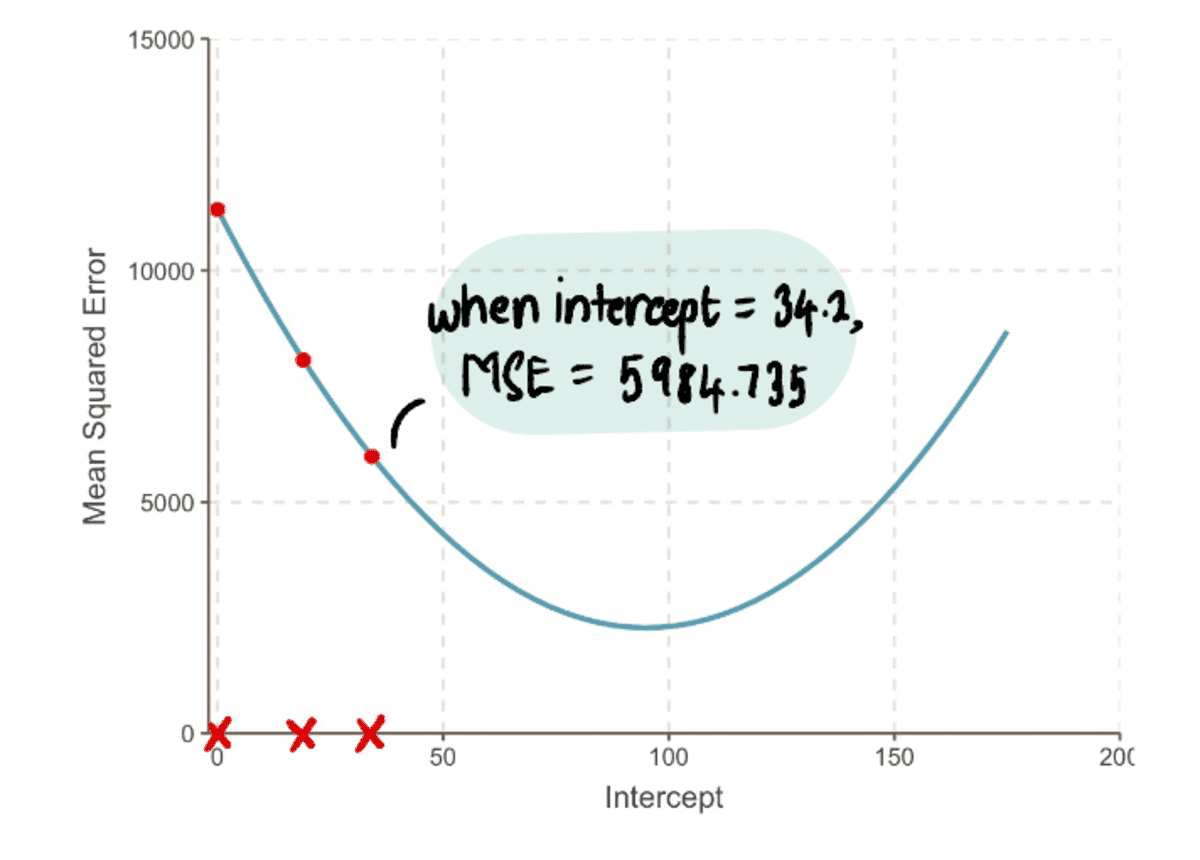
…and our Step Sizes are getting smaller:
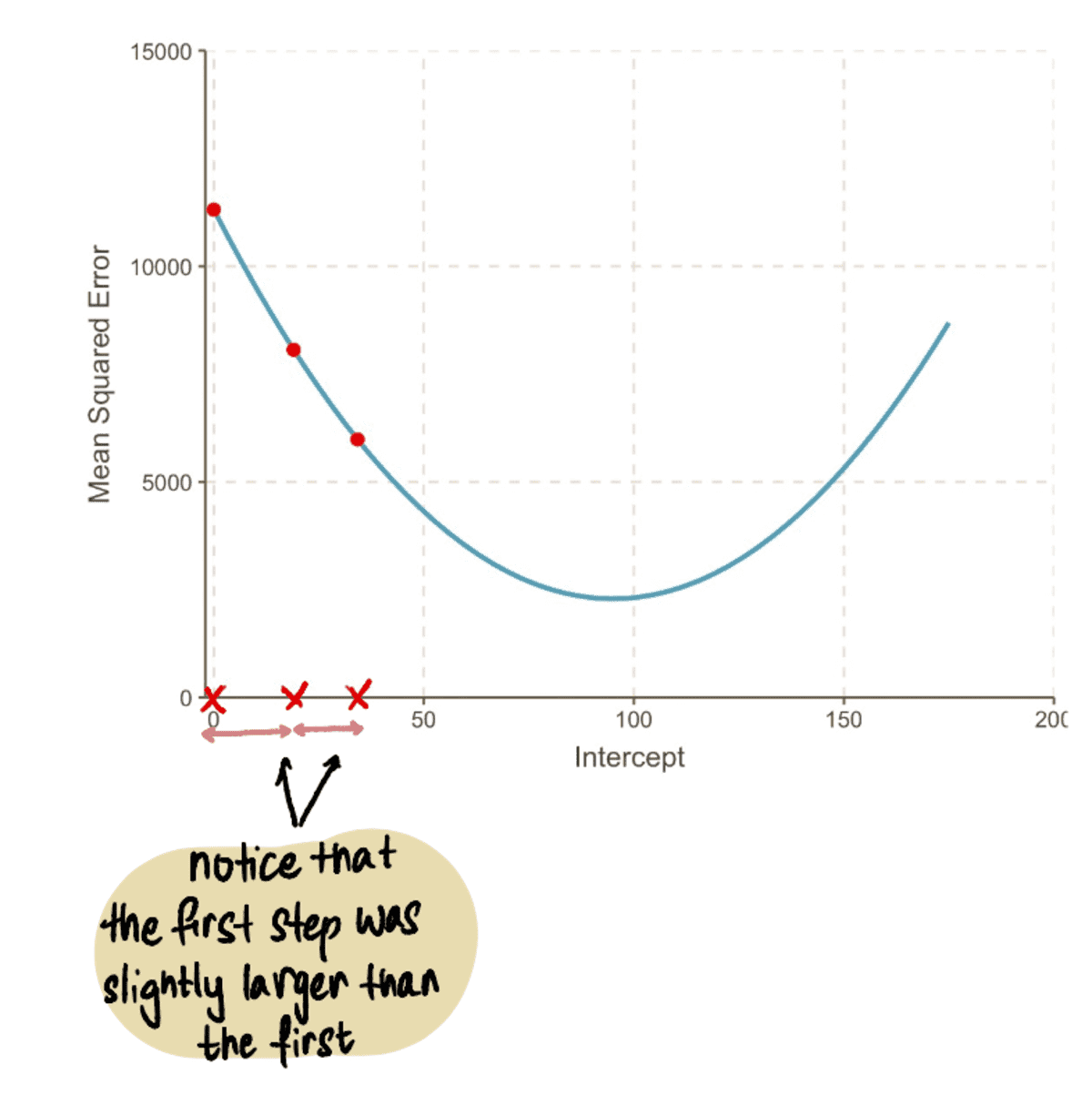
We repeat this process iteratively until we converge toward the optimal solution:
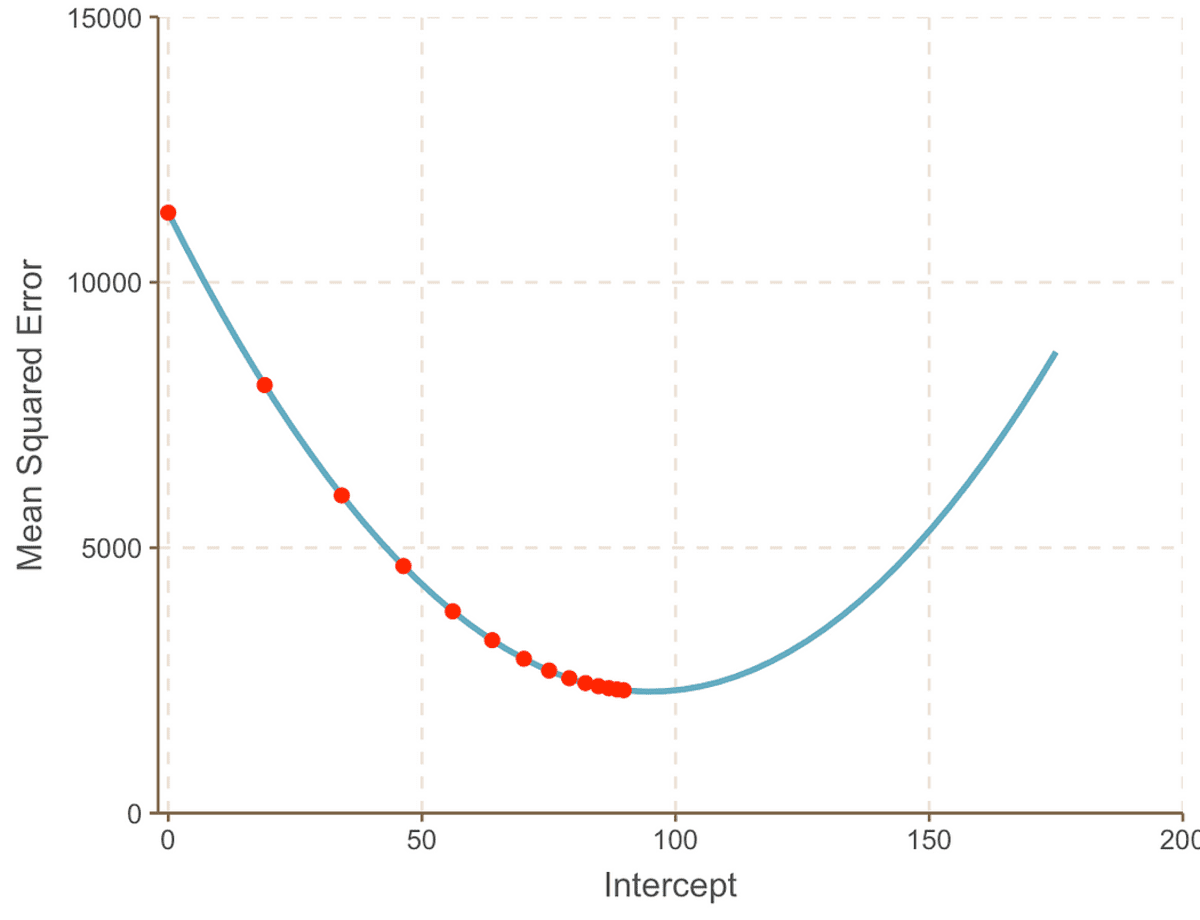
As we progress toward the minimum point of the curve, we observe that the Step Size becomes increasingly smaller. After 13 steps, the gradient descent algorithm estimates the intercept value to be 95. If we had a crystal ball, this would be confirmed as the minimum point of the MSE curve. And it is clear to see how this method is more efficient compared to the brute force approach that we saw in the previous article.
Now that we have the optimal value of our intercept, the linear regression model is:

And the linear regression line looks like this:
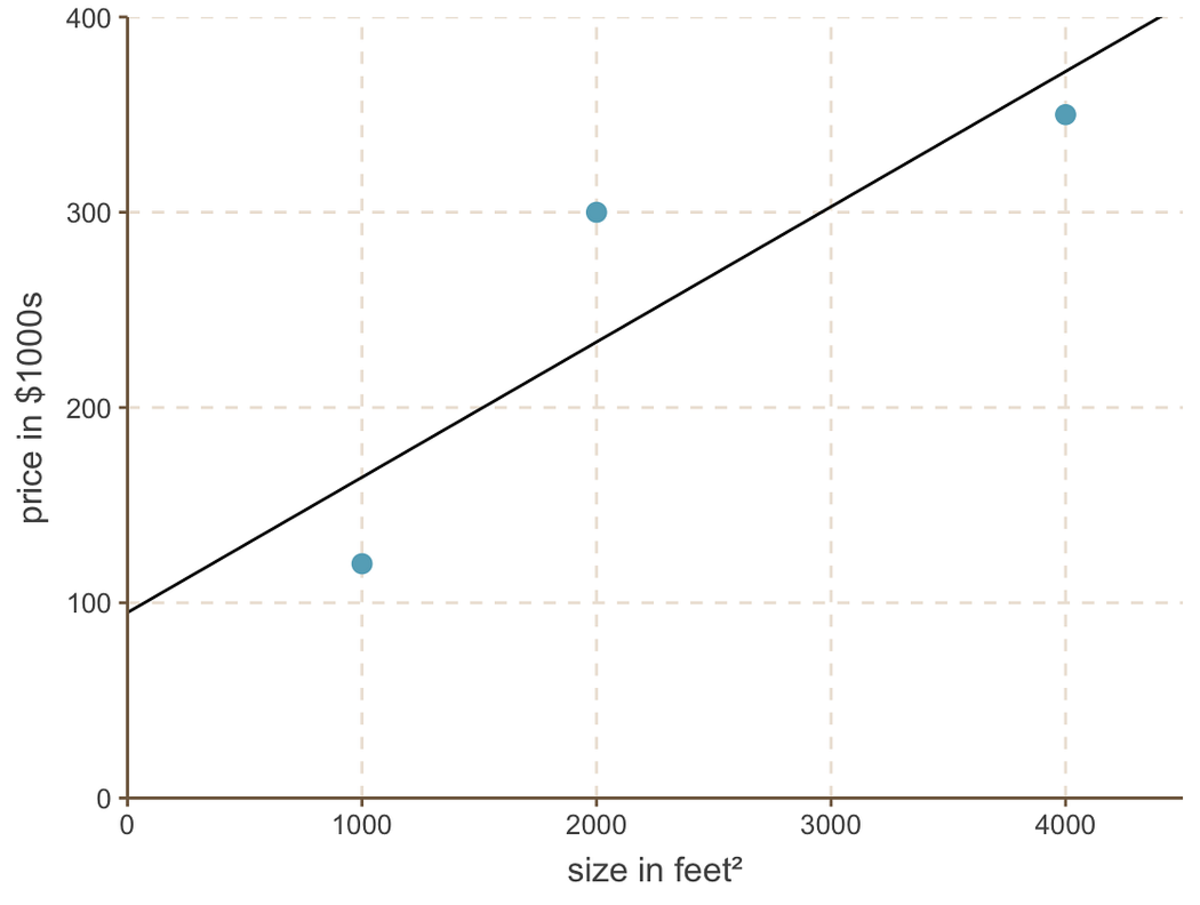
best fitting line with intercept = 95 and slope = 0.069
Finally, going back to our friend Mark’s question — What value should he sell his 2400 feet² house for?

Plug in the house size of 2400 feet² into the above equation…
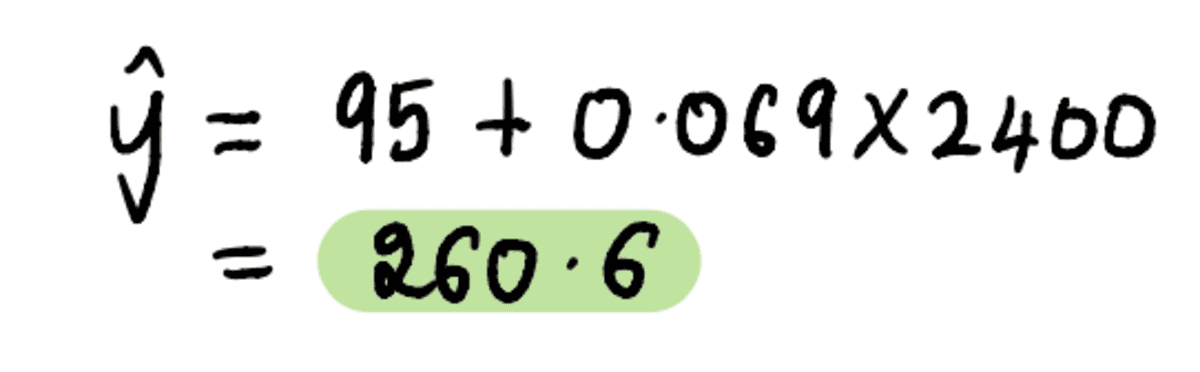
…and voila. We can tell our unnecessarily worried friend Mark that based on the 3 houses in his neighborhood, he should look to sell his house for around $260,600.
Now that we have a solid understanding of the concepts, let’s do a quick Q&A sesh answering any lingering questions.
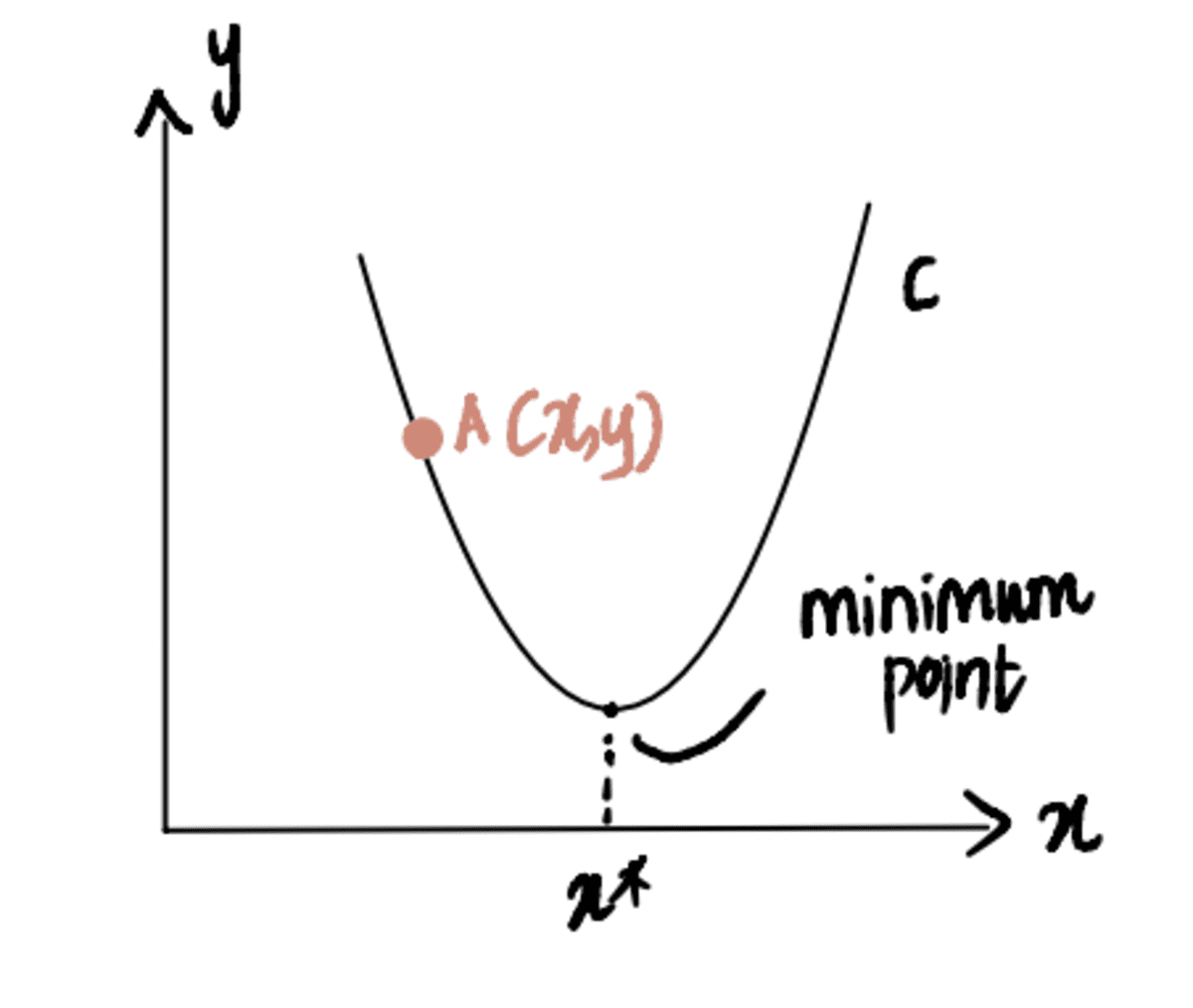
Why does finding the gradient actually work?
To illustrate this, consider a scenario where we are attempting to reach the minimum point of curve C, denoted as x*. And we are currently at point A at x, located to the left of x*:
If we take the derivative of the curve at point A with respect to x, represented as dC(x)/dx, we obtain a negative value (this means the gradient is sloping downwards). We also observe that we need to move to the right to reach x*. Thus, we need to increase x to arrive at the minimum x*.
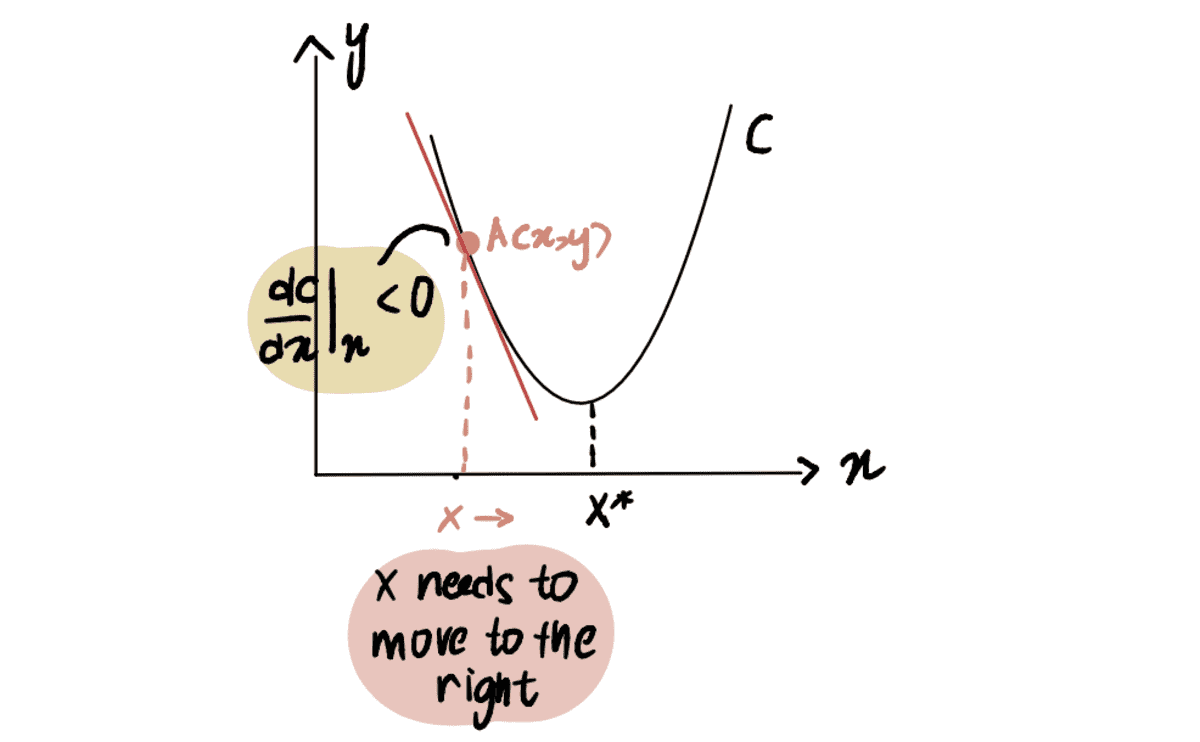
the red line, or the gradient, is sloping downwards => a negative Gradient
Since dC(x)/dx is negative, x-??*dC(x)/dx will be larger than x, thus moving towards x*.
Similarly, if we are at point A located to the right of the minimum point x*, then we get a positive gradient (gradient is sloping upwards), dC(x)/dx.
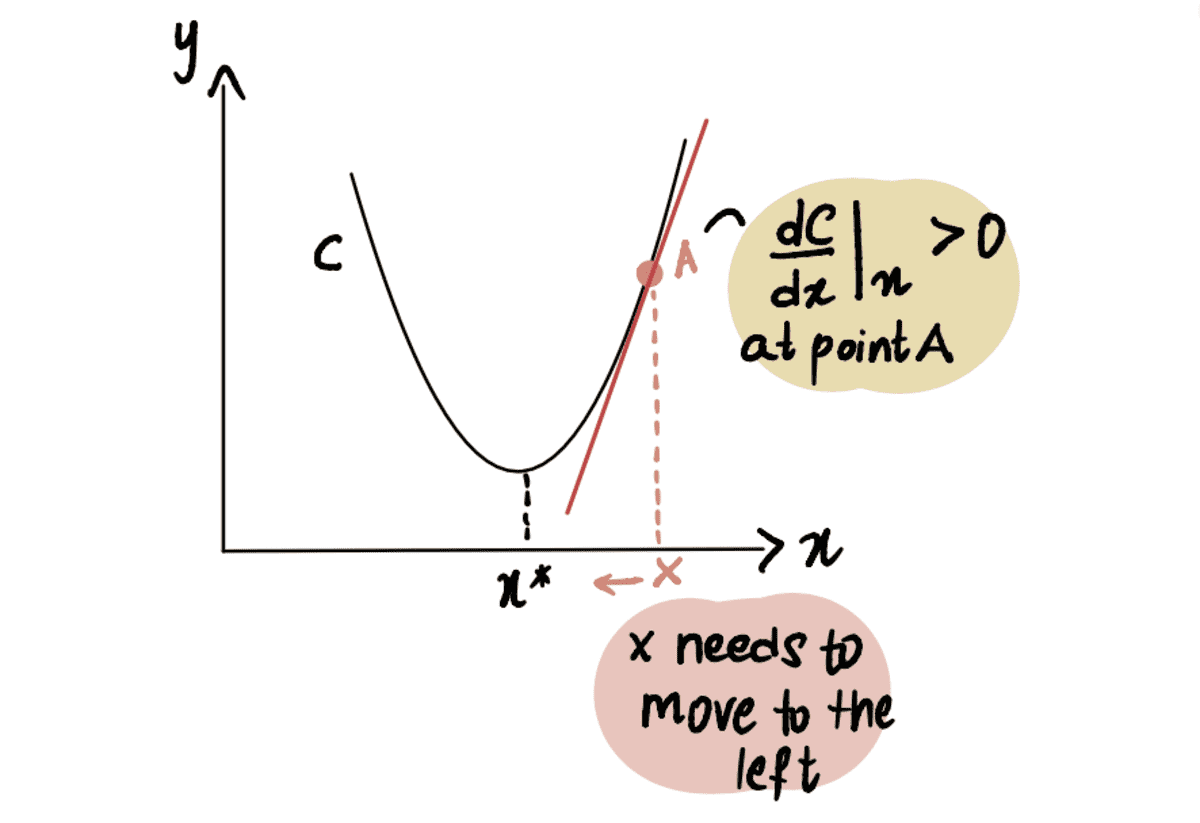
the red line, or the Gradient, is sloping upwards => a positive Gradient
So x-??*dC(x)/dx will be less than x, thus moving towards x*.
How does gradient decent know when to stop taking steps?
Gradient descent stops when the Step Size is very close to 0. As previously discussed, at the minimum point the gradient is 0 and as we approach the minimum, the gradient approaches 0. Therefore, when the gradient at a point is close to 0 or in the vicinity of the minimum point, the Step Size will also be close to 0, indicating that the algorithm has reached the optimal solution.
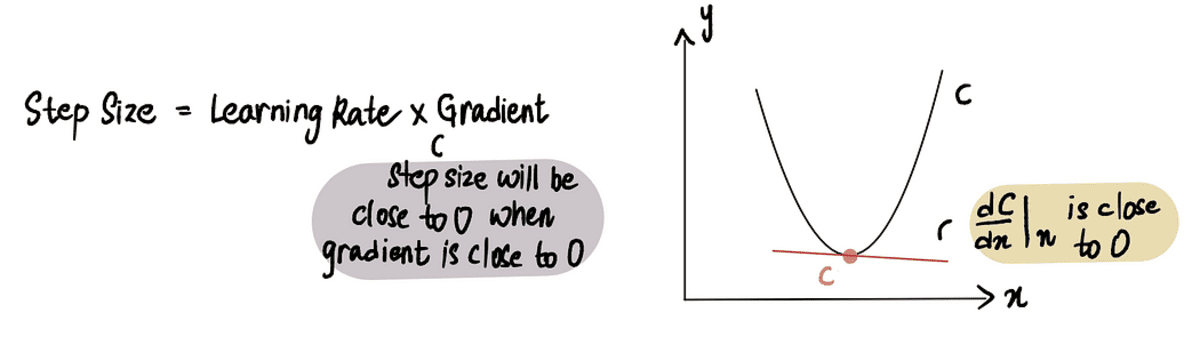
when we are close to the minimum point, the gradient is close to 0, and subsequently Step Size is close to 0
In practice the Minimum Step Size = 0.001 or smaller
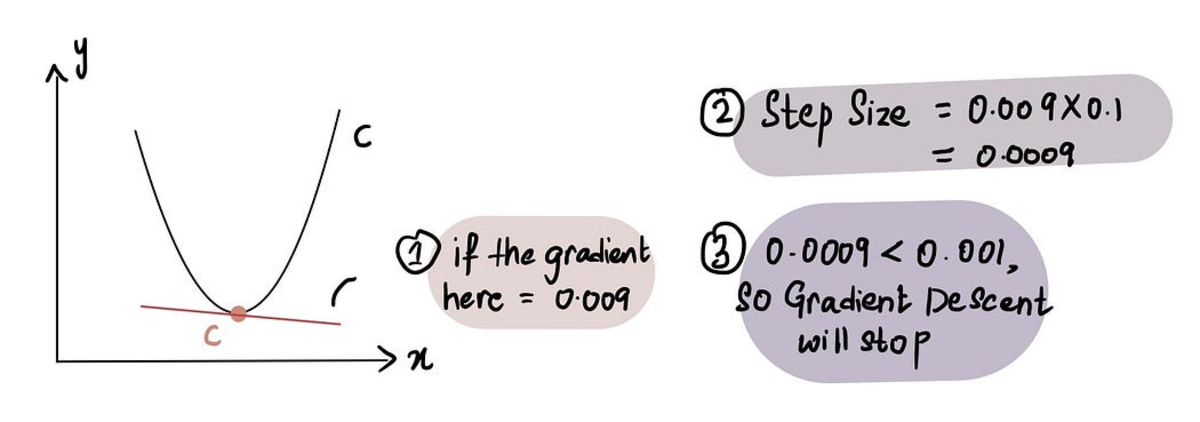
That being said, gradient descent also includes a limit on the number of steps it will take before giving up called the Maximum Number of Steps.
In practice, the Maximum Number of Steps = 1000 or greater
So even if the Step Size is larger than the Minimum Step Size, if there have been more than the Maximum Number of Steps, gradient descent will stop.
What if the minimum point is more challenging to identify?
Until now, we have been working with a curve where it’s easy to identify the minimum point (these kinds of curves are called convex). But what if we have a curve that’s not as pretty (technically aka non-convex) and looks like this:
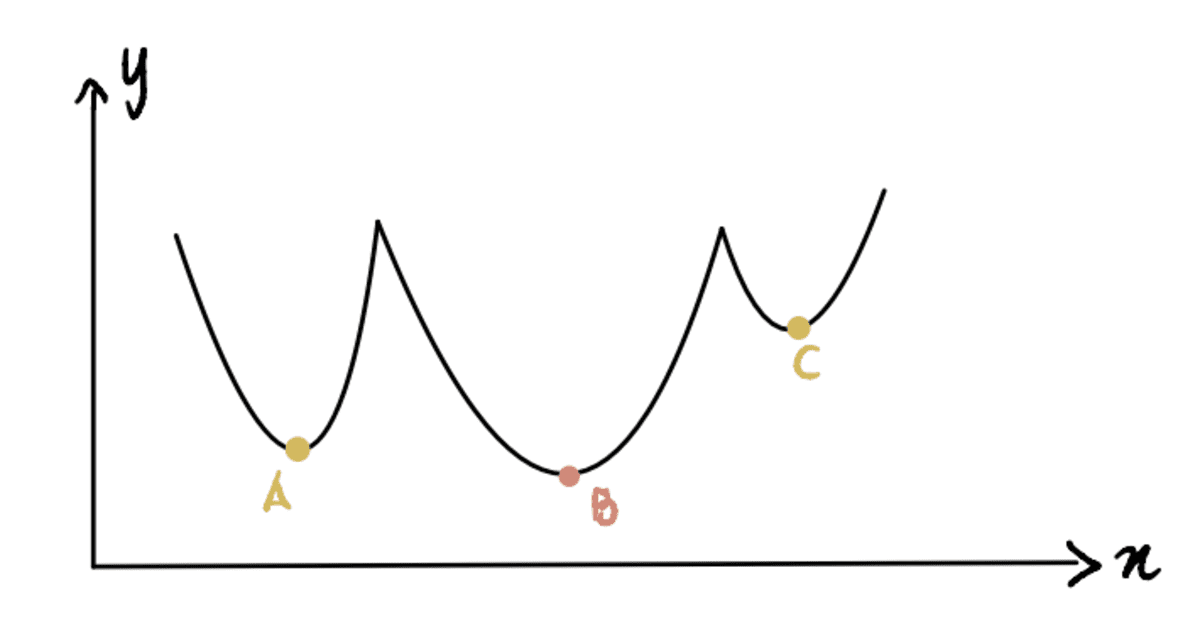
Here, we can see that Point B is the global minimum (actual minimum), and Points A and C are local minimums (points that can be confused for the global minimum but aren’t). So if a function has multiple local minimums and a global minimum, it is not guaranteed that gradient descent will find the global minimum. Moreover, which local minimum it finds will depend on the position of the initial guess (as seen in Step 1 of gradient descent).
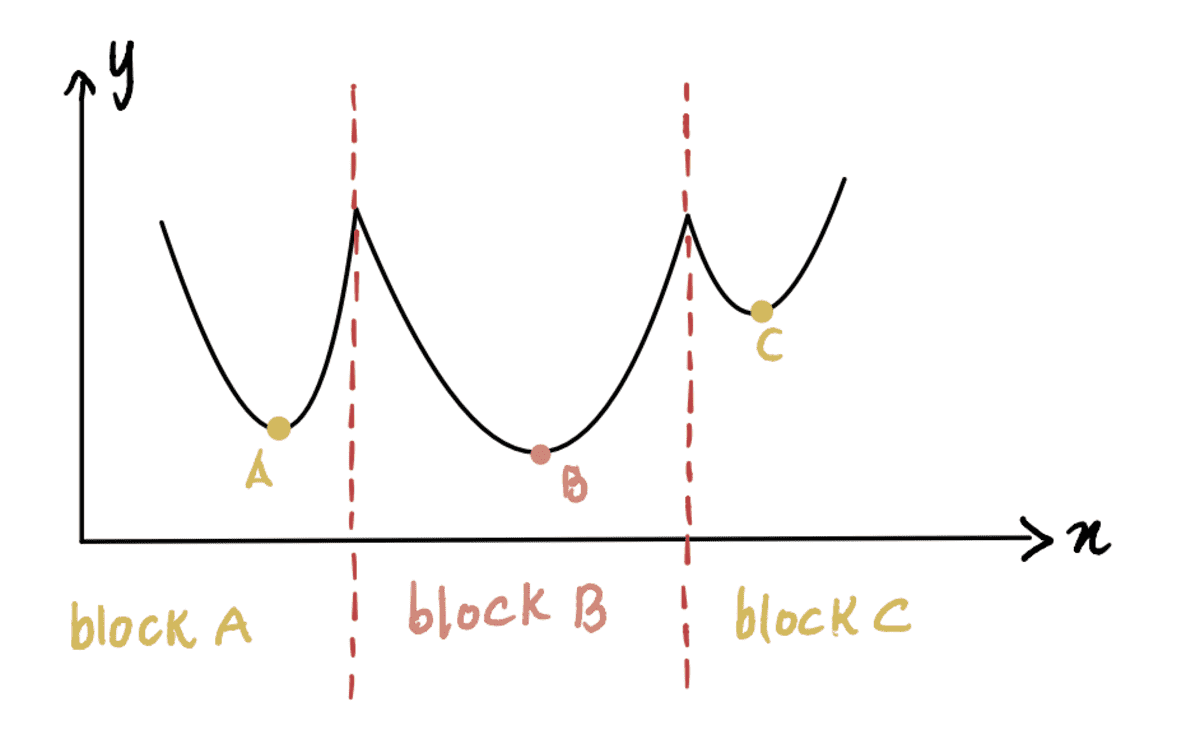
Taking this non-convex curve above as an example, if the initial guess is at Block A or Block C, gradient descent will declare that the minimum point is at local minimums A or C, respectively when in reality it’s at B. Only when the initial guess is at Block B, the algorithm will find the global minimum B.
Now the question is — how do we make a good initial guess?
Simple answer: Trial and Error. Kind of.
Not-so-simple answer: From the graph above, if our minimum guess of x was 0 since that lies in Block A, it’ll lead to the local minimum A. Thus, as you can see, 0 may not be a good initial guess in most cases. A common practice is to apply a random function based on a uniform distribution on the range of all possible values of x. Additionally, if feasible, running the algorithm with different initial guesses and comparing their results can provide insight into whether the guesses differ significantly from each other. This helps in identifying the global minimum more efficiently.
Okay, we’re almost there. Last question.
What if we are trying to find more than one optimal value?
Until now, we were focused on only finding the optimal intercept value because we magically knew the slope value of the linear regression is 0.069. But what if don’t have a crystal ball and don't know the optimal slope value? Then we need to optimize both the slope and intercept values, expressed as x? and x? respectively.
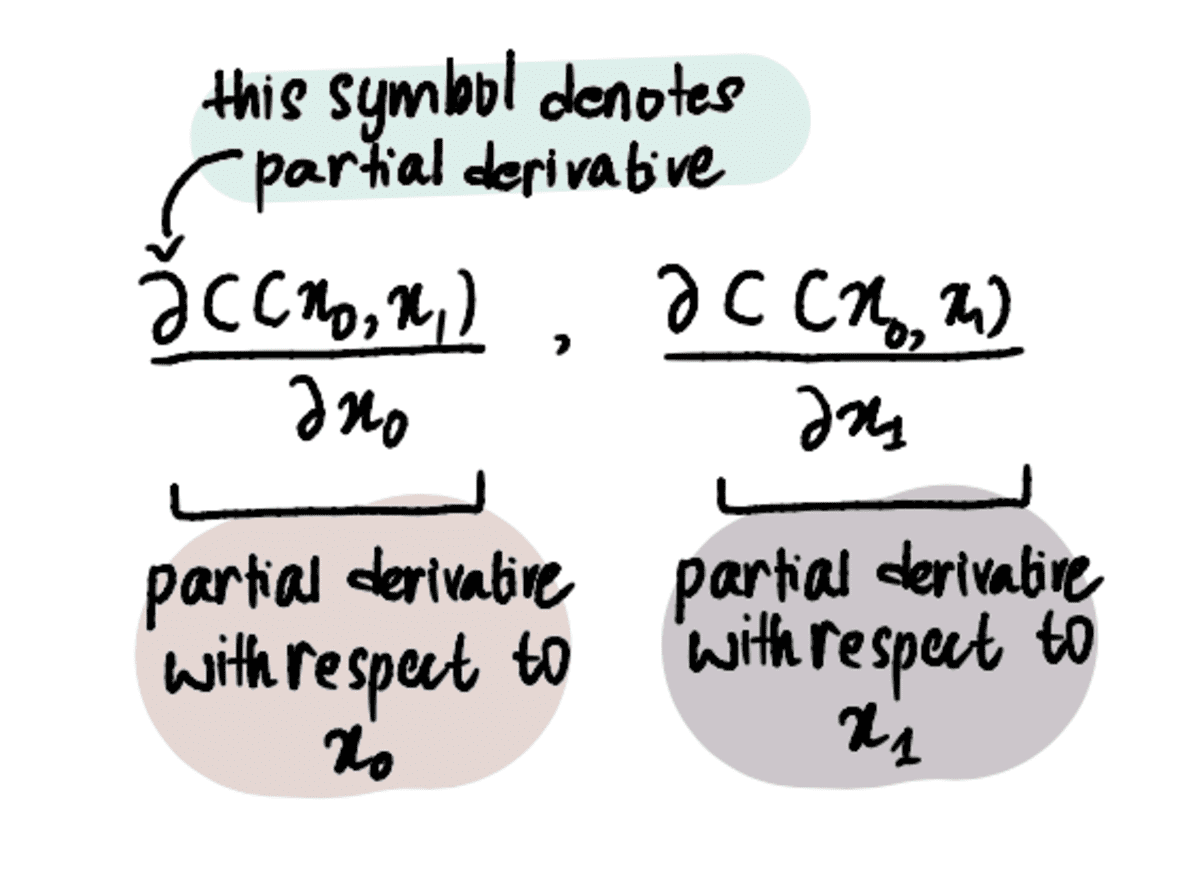
In order to do that, we must utilize partial derivatives instead of just derivatives.
NOTE: Partial derivates are calculated in the same way as reglar old derivates, but are denoted differently because we have more than one variable we are trying to optimize for. To learn more about them, read this article or watch this video.
However, the process remains relatively similar to that of optimizing a single value. The cost function (such as MSE) must still be defined and the gradient descent algorithm must be applied, but with the added step of finding partial derivatives for both x? and x?.
Step 1: Make initial guesses for x₀ and x₁
Step 2: Find the partial derivatives with respect to x₀ and x₁ at these points
Step 3: Simultaneously update x₀ and x₁ based on the partial derivatives and the Learning Rate
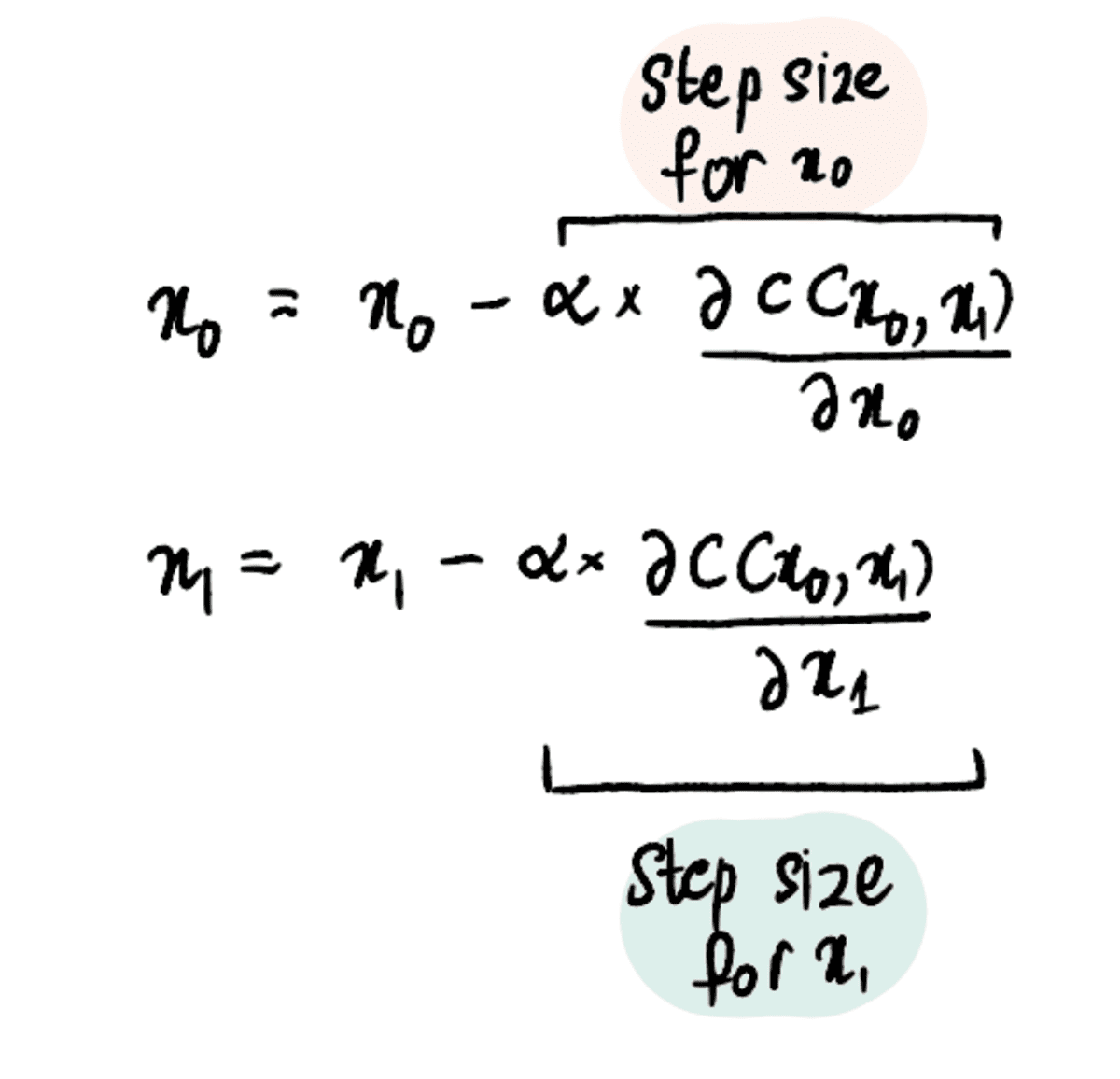
Step 4: Repeat Steps 2–3 until the Maximum Number of Steps is reached or the Step Size is less that the Minimum Step Size
And we can extrapolate these steps to 3, 4, or even 100 values to optimize for.
In conclusion, gradient descent is a powerful optimization algorithm that helps us reach the optimal value efficiently. The gradient descent algorithm can be applied to many other optimization problems, making it a fundamental tool for data scientists to have in their arsenal. Onto bigger and better algorithms now!
Shreya Rao illustrate and explain Machine Learning algorithms in layman's terms.
Original. Reposted with permission.