Evaluating HTAP Databases for Machine Learning Applications
Businesses are producing a greater number of intelligent applications; which traditional databases are unable to support. A new class of databases, Hybrid Transactional and Analytical Processing (HTAP) databases, offers a variety of capabilities with specific strengths and weaknesses to consider. This article aims to give application developers and data scientists a better understanding of the HTAP database ecosystem so they can make the right choice for their intelligent application.
By Monte Zweben, CEO Splice Machine.
HTAP is a term coined by The Gartner Group to describe a class of database systems that are Hybrid Transactional and Analytical Processing Systems. These systems exhibit the transactional capabilities of operational databases such as Oracle, SQL Server, DB2, MySQL, and Postgres as well as the capabilities of analytical systems such as Teradata, Netezza, and Vertica.
The power of HTAP is to serve a new class of applications that are intelligent – applications that analyze real-time data to provide the most timely insights possible. Previous generations of databases could not service such applications because the data had to move from operational systems to analytical systems via an ETL (Extraction, Transformation, and Load) process that typically takes many hours. It could even take s days before an analytical system would be able to process the data. This inherent lag caused by ETL required companies, governments, and academic researchers to look through the rear-view mirror of their operation instead of looking forward through the windshield.
HTAP enables new technical capabilities such as machine learning, real-time operational reporting and dashboarding, and reactive systems. These capabilities serve as the foundation for a new class of intelligent applications. These applications are always-on, reacting to data streaming in, and adaptively improving as they see more data. When applications are always-on it means that they run continuously, unlike traditional data science where you first prepare data and analyze, and then report. By reacting, we mean that the application monitors its inputs, which may stream in or be batch ingested, and when certain data patterns emerge, the application takes action. For example, healthcare applications that can surveil Electronic Medical Records (EMR) and alert clinicians of dangerous conditions for patients in hospitals are good examples of always-on, reactive systems. Supply-chain systems, fraud detection, cybersecurity, and marketing applications have similar properties. With the more improved foundation that HTAP provides, these applications can now improve automatically over time with more data. By integrating machine learning models with HTAP, applications can become adaptive.
However, HTAP systems are not all the same. They excel at different workloads because of how they were built. The following systems are sometimes classified as HTAP systems:
- SAP HANA
- Oracle Exadata
- MemSQL
- Splice Machine
- Apache Hive
- Apache HAWQ
- Apache Trafodion
- Apache Kudu combined with Apache Impala
HTAP databases can be broken down against the following architectural dimensions:
- Bias – Can the system power OLTP workloads? Can it power OLAP workloads? Can it power both simultaneously?
- Storage Model – How is data stored? Columnar or row-based? On-disk or in-memory?
- Scaling Architecture – Is it scale-out or scale-up?
- Open Source – Is it an open-source solution?
- DBaaS – Is it available as a service?

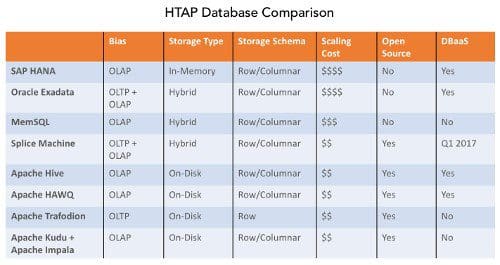
SAP HANA primarily focuses on OLAP, which is used for analytical workloads. It is ACID compliant and handles transactional updates, but these are not optimized for large-scale real-time OLTP workloads and is not typically used to power real-time, concurrent applications. HANA is primarily an in-memory system requiring the entire data set to be in memory. This system uses a hybrid representation where data is inserted in tuples (row-based) and then converted to columnar. You can bypass tuple-based insertion as well and go directly columnar. HANA is strictly a scale-up engineered solution with excellent performance but at a very high cost. This system is not open source but is available as a service through SAP.