Key-Value Databases, Explained
Among the four big NoSQL database types, key-value stores are probably the most popular ones due to their simplicity and fast performance. Let’s further explore how key-value stores work and what are their practical uses.
NoSQL has become increasingly important in our day-to-day lives, with some of the most popular platforms and services relying on them to deliver content to use with lightning speed. Of course, NoSQL encompasses a variety of database types, but easily the most popular is key-value store.
This type of data model is built around its extreme simplicity, which allows it to perform blisteringly fast compared to relational databases. Not only that, but because it follows the scalable NoSQL design philosophy, key-value stores allow for flexibility and easy start-up.
How Does a Key-Value Work?
Key-value stores are actually pretty straightforward. A value, which can be basically any piece of data or information, is stored with a key that identifies its location. In fact, this is a design concept that exists in pretty much every piece of programming as an array or map object. The difference here is that it’s stored persistently in a database management system.
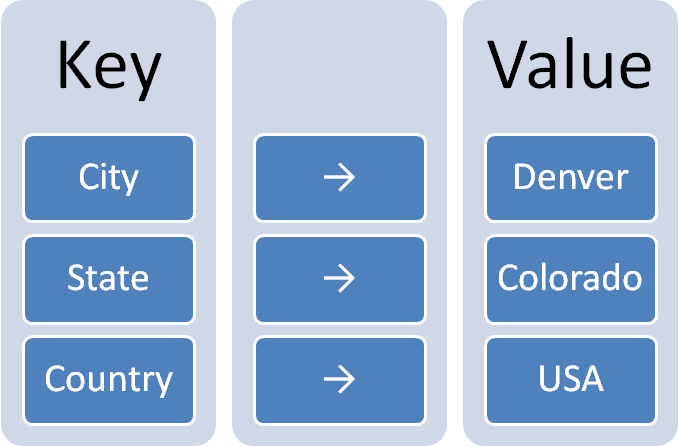
What makes key-value stores so popular is that the way information is stored is as a sort of opaque blob, rather than discrete data. As such, there’s really no need to index the database to make it perform faster. Instead, it performs faster on its own due to the way it’s structured. Similarly, it doesn’t really have a language of its own, instead relying on simple get, put and delete commands.
Of course, this comes with the downside that the information you get from a request isn’t filtered. This lack of control of the data can be problematic under certain circumstances but for the most part, it’s worth the exchange. Since key-value stores are fast and reliable, most programmers work around any filter/control issues they may come up against.
Benefits of Key-Value
As one of the more popular forms of NoSQL data models, key-value have a lot of benefits when it comes to building a database:
Scalability: One of the biggest benefits compared to a relational database is the fact that key-value stores (like NoSQL in general) are infinitely scalable in a horizontal fashion. Compared to relational databases where expansion is vertical and finite, this can be a big boon to complex and larger databases.
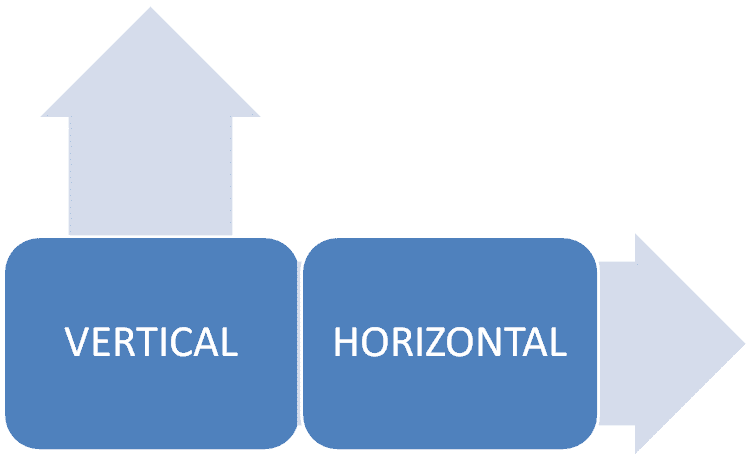
More specifically it manages this through partitioning & replication. It also minimizes ACID guarantees by going around things like low-overhead server calls.
No/Simpler Querying: Querying, in general, is really not doable with key-value stores, except in specific cases when it comes to querying keys, and even then it’s not always possible. Therefore, in cases such as sessions, user profiles, shopping carts, and so on, key-value makes it cheaper to handle since it’s just one request to read and one request to write (due to the blob-like nature of how the data is stored).
Similarly, concurrency issues are easier to handle since you only need to resolve one key.
Mobility: Since they don’t have a query language, key-value stores are easy to move from one system to another without the need for new architecture or changing the code. As such, moving from an old operating system to a new one doesn’t cause a severe disruption as it would with a relational database.
When to Use Key-Value
Traditional relational databases are not really made to handle a high volume of read/write operations, which is where key-value stores shine. Since it’s easily scalable, key-value can handle thousands upon thousands of users at any given second. Additionally, with the built-in redundancy, it can handle lost storage or data without any issues.
As such, there are a few situations where key-value shines:
- User preferences and profile stores
- Large scale session management for users
- Product recommendations (such as in eCommerce platforms)
- Customized ad delivery to users based on their data profile
- Data cache for rarely updated data
There are also a variety of other situations where key-value does well. For example, due to its scalability, it often tends to get used for big data research. Similarly, key-value works well for session management, whether it’s web-applications or even MMO games, and managing individual player’s session.
Another great use is for temporary and seasonal surges in purchasing on platforms. For example, in cases such as Christmas, thanksgiving, national holidays, and so on. Rather than investing heavily on infrastructure that will not be used year-round, the quick and easy scalability of key-value allows stores to purchase one or more temporary shards to help process these seasonal surges.
Examples of Popular Key-Value Databases
There are several different types of key-value database models to pick from, for example, some store data on an SSD, while others store on RAM. The truth is, some of the most popular and widely-used databases are key-value stores, and we rely on them on a daily basis in our day-to-day lives.
Amazon DynamoDB: Probably the most widely used key-value store database, in fact, it was the research into DynamoDB that really started making NoSQL really popular.
Aerospike: Open-source database that is optimized for in-memory storage.
Berkeley DB: Another open-source database that is a high-performance database storage library, although it’s relatively basic.
Couchbase: Interestingly allows for text searches and SQL-style querying.
Memcached: Helps speed up websites by storing cache data in RAM, plus it’s free and open-source.
Riak: Made for developing apps, it works well with other databases and apps.
Redis: A multi-purpose database that also acts as memory cache and message broker.
Conclusion
The real brilliance of a key-value store is that it’s simple. While this can be a double-edged sword, especially when it comes to more complex things such as financial transactions, its purpose-made for bridging gaps of relational databases. By using a combination of both relational and non-relational, we can make an even more efficient pipeline, whether it is for data analysis or dealing with users.
Alex Williams is a seasoned full-stack developer and the owner of Hosting Data UK. After graduating from the University of London, majoring in IT, Alex worked as a developer leading various projects for clients from all over the world for almost 10 years. Recently, Alex switched to being an independent IT consultant and started his own blog. There, he explores web development, data management, digital marketing, and solutions for online business owners just starting out.