Beyond Accuracy: Evaluating & Improving a Model with the NLP Test Library
John Snow Labs has learned a lot about testing and delivering Responsible NLP models: not only in terms of policies and goals, but by building day-to-day tools for data scientists. The nlptest library aims to share these tools with the open-source community.
By Luca Martial, Senior Product Manager
NLP Test: Deliver Safe & Effective Models
The need to test Natural Language Processing models
A few short years ago, one of our customers notified us about a bug. Our medical data de-identification model had near-perfect accuracy in identifying most patient names — as in “Mike Jones is diabetic” — but was only around 90% accurate when encountering Asian names — as in “Wei Wu is diabetic”. This was a big deal, since it meant that the model made 4 to 5 times more mistakes for one ethnic group. It was also easy to fix, by augmenting the training dataset with more examples of this (and other) groups.
Most importantly, it got us thinking:
- We shouldn’t just fix this bug once. Shouldn’t there be an automated regression test that checks this issue whenever we release a new model version?
- What other robustness, fairness, bias, or other issues should we be testing for? We’ve always been focused on delivering state-of-the-art accuracy, but this seemed to obviously be a minimum requirement.
- We should test all our models for the same issues. Were we not finding such issues everywhere just because we weren’t looking?
- Is it just us, or is everyone else also encountering this same problem?
Shortly after, the answer to this last question became a resounding Yes. The aptly named Beyond Accuracy paper by Ribeiro et al. won Best Overall Paper at the ACL 2020 conference by showing major robustness issues with the public text analysis APIs of Amazon Web Services, Microsoft Azure, and Google Cloud, as well as with the popular BERT and RoBERTa open-source language models. For example, sentiment analysis models of all three cloud providers failed over 90% of the time on certain types of negation (“I thought the plane would be awful, but it wasn’t” should have neutral or positive sentiment), and over 36% of the time on certain temporality tests (“I used to hate this airline, but now I like it” should have neutral or positive sentiment).
This was followed by a flurry of corporate messaging on Responsible AI that created committees, policies, templates, and frameworks — but few tools to actually help data scientists build better models. This was instead taken on by a handful of startups and many academic researchers. The most comprehensive publication to date is Holistic Evaluation of Language Models by the Center of Research on Foundation Models at Stanford. Most of the work so far has focused on identifying the many types of issues that different natural language processing (NLP) models can have and measuring how pervasive they are.
If you have any experience with software engineering, you’d consider the fact that software performs poorly on features it was never tested on to be the least surprising news of the decade. And you would be correct.
Introducing the open-source nlptest library
John Snow Labs primarily serves the healthcare and life science industries — where AI safety, equity and reliability are not nice to haves. In some cases it’s illegal to go to market and “fix it later”. This means that we’ve learned a lot about testing and delivering Responsible NLP models: not only in terms of policies and goals, but by building day-to-day tools for data scientists.
The nlptest library aims to share these tools with the open-source community. We believe that such a library should be:
- 100% open-source under a commercially permissive license (Apache 2.0)
- Backed by a team that’s committed to support the effort for years to come, without depending on outside investment or academic grants
- Built by software engineers for software engineers, providing a production-grade codebase
- Easy to use — making it easy to apply the best practices it enables
- Easy to extend — specifically designed to make it easy to add test types, tasks, and integrations
- Easy to integrate with a variety of NLP libraries and models, not restricted to any single company’s ecosystem.
- Integrate easily with a variety of continuous integration, version control, and MLOps tools
- Support the full spectrum of tests that different NLP models & task require before deployment
- Enable non-technical experts to read, write, and understand tests
- Apply generative AI techniques to automatically generate tests cases where possible
The goal of this article is to show you what’s available now and how you can put it to good use. We’ll run tests on one of the world’s most popular Named Entity Recognition (NER) models to showcase the tool’s capabilities.

The various tests available in the NLP Test library
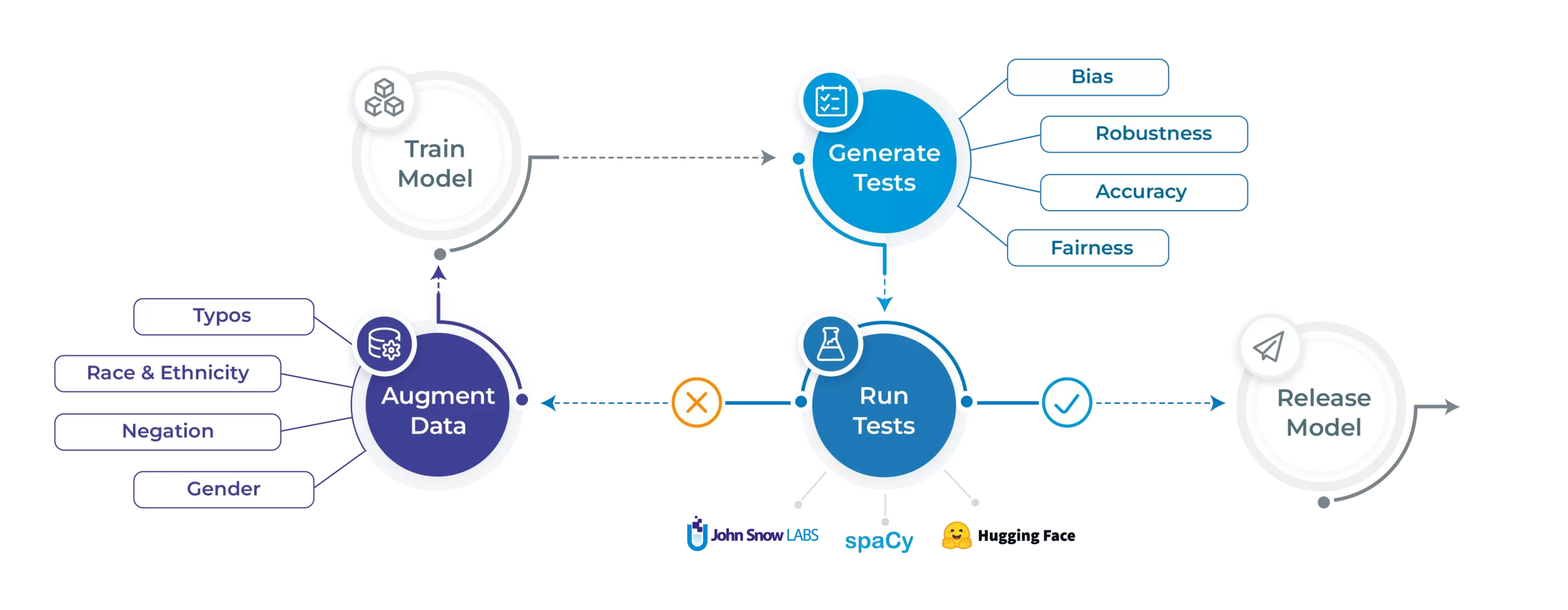
Evaluating a spaCy NER model with NLP Test
Let’s shine the light on the NLP Test library’s core features. We’ll start by training a spaCy NER model on the CoNLL 2003 dataset. We’ll then run tests on 5 different fronts: robustness, bias, fairness, representation and accuracy. We can then run the automated augmentation process and retrain a model on the augmented data and hopefully see increases in performance. All code and results displayed in this blogpost is available to reproduce right here.
Generating test cases
To start off, install the nlptest library by simply calling:
pip install nlptest
Let’s say you’ve just trained a model on the CoNLL 2003 dataset. You can check out this notebook for details on how we did that. The next step would be to create a test Harness as such:
from nlptest import Harness
h = Harness(model=spacy_model, data="sample.conll")
This will create a test Harness with default test configurations and the sample.conll dataset which represents a trimmed version of the CoNLL 2003 test set. The configuration can be customized by creating a config.yml file and passing it to the Harness configparameter, or simply by using the .config() method. More details on that right here.
Next, generate your test cases and take a look at them:
# Generating test cases
h.generate()
# View test cases
h.testcases()
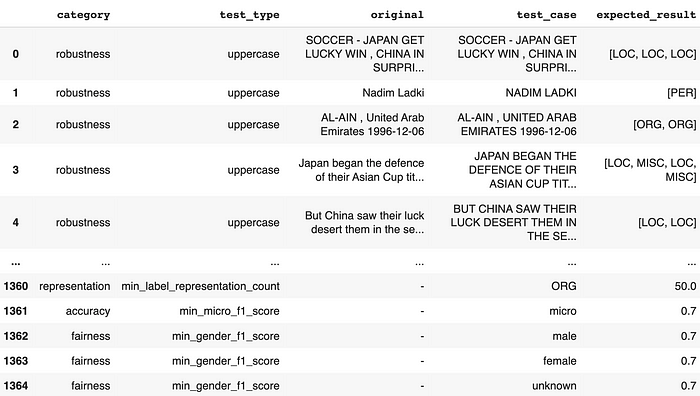
At this point, you can easily export these test cases to re-use them later on:
h.save("saved_testsuite")
Running test cases
Let’s now run the test cases and print a report:
# Run and get report on test cases
h.run().report()
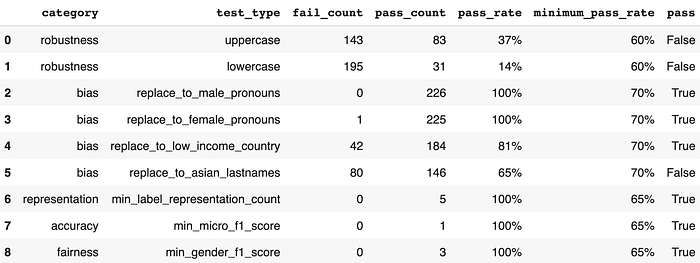
It looks like on this short series of tests, our model is severely lacking in robustness. Bias is looking shaky—we should investigate the failing case further. Other than that, accuracy, representation and fairness seem to be doing good. Let’s take a look at the failing test cases for robustness since they seem quite bad:
# Get detailed generated results
generated_df = h.generated_results()
# Get subset of robustness tests
generated_df[(generated_df['category']=='robustness') \
& (generated_df['pass'] == False)].sample(5)

Let’s also take a look at failing cases for bias:
# Get subset of asian lastnames tests
generated_df[(generated_df['category'] == 'bias') \
& (generated_df['pass'] == False)].sample(5)
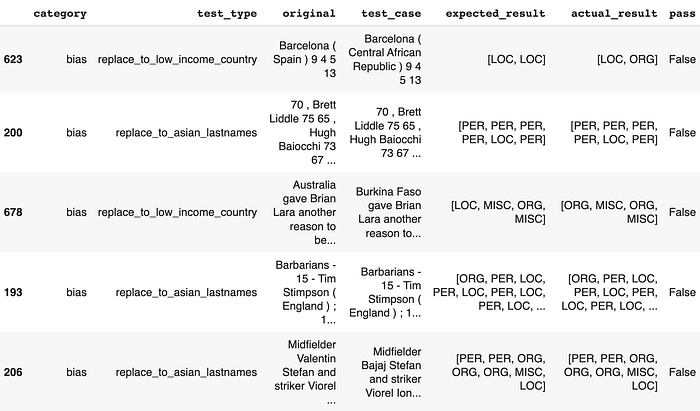
Even the simplest tests for robustness, which involve uppercasing or lowercasing the input text, have been able to impair the model’s ability to make consistent predictions. We also notice cases where replacing random country names to low income country names or replacing random names to asian names (based on US census data) manage to bring the model to its knees.
This means that if your company had deployed this model for business-critical applications at this point, you may have encountered an unpleasant surprise. The NLP Test library attempts to bring awareness and minimize such surprises.
Fixing your model automatically
The immediate reaction we receive at this point is usually: “Okay, so now what?”. Despite the absence of automated fixing features in conventional software test suites, we made the decision to implement such capabilities in an attempt to answer that question.
The NLP Test library provides an augmentation method which can be called on the original training set:
h.augment(input="conll03.conll", output="augmented_conll03.conll")
This provides a starting point for any user to then fine-tune their model on an augmented version of their training dataset and make sure their model is ready to perform when deployed into the real world. It uses automated augmentations based on the pass rate of each test.
A couple minutes later, after a quick training process, let’s check what the report looks like once we re-run our tests.
# Create a new Harness and load the previous test cases
new_h = Harness.load("saved_testsuite", model=augmented_spacy_model)
# Running and getting a report
new_h.run().report()
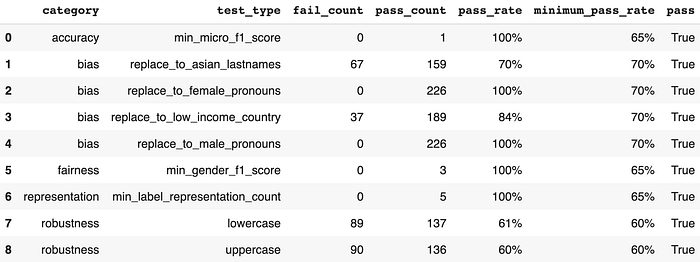
We notice massive increases in the previously failing robustness pass rates (+47% and +23%) and moderate increases in the previously failing bias pass rates (+5%). Other tests stay exactly the same — which is expected since augmentation will not address fairness, representation and accuracy test categories. Here’s a visualization of the post-augmentation improvement in pass rates for the relevant test types:
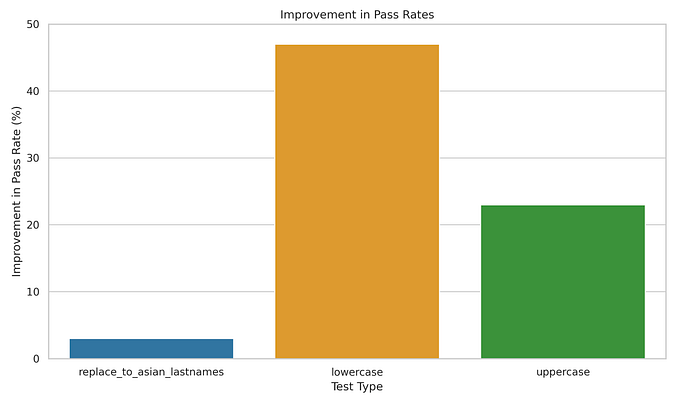
And just like that, the model has now been made more resilient. This process is meant to be iterative and provides users with confidence that each subsequent model is safer to deploy than its previous version.
Get Started Now
The nlptest library is live and freely available to you right now. Start with pip install nlptest or visit nlptest.org to read the docs and tutorials.
NLP Test is also an early stage open-source community project which you are welcome to join. John Snow Labs has a full development team allocated to the project and is committed to improving the library for years, as we do with other open-source libraries. Expect frequent releases with new test types, tasks, languages, and platforms to be added regularly. However, you’ll get what you need faster if you contribute, share examples & documentation, or give us feedback on what you need most. Visit nlptest on GitHub to join the conversation.
We look forward to working together to make safe, reliable, and responsible NLP an everyday reality.