Understanding Classification Metrics: Your Guide to Assessing Model Accuracy
Navigating the Maze of Accuracy, Precision, and Recall in Machine Learning.

Image by Author
Motivation
Evaluation metrics are like the measuring tools we use to understand how well a machine learning model is doing its job. They help us compare different models and figure out which one works best for a particular task. In the world of classification problems, there are some commonly used metrics to see how good a model is, and it's essential to know which metric is right for our specific problem. When we grasp the details of each metric, it becomes easier to decide which one matches the needs of our task.
In this article, we will explore the basic evaluation metrics used in classification tasks and examine situations where one metric might be more relevant than others.
Basic Terminology
Before we dive deep into evaluation metrics, it is critical to understand the basic terminology associated with a classification problem.
Ground Truth Labels: These refer to the actual labels corresponding to each example in our dataset. These are the basis of all evaluation and predictions are compared to these values.
Predicted Labels: These are the class labels predicted using the machine learning model for each example in our dataset. We compare such predictions to the ground truth labels using various evaluation metrics to calculate if the model could learn the representations in our data.
Now, let us only consider a binary classification problem for an easier understanding. With only two different classes in our dataset, comparing ground truth labels with predicted labels can result in one of the following four outcomes, as illustrated in the diagram.

Image by Author: Using 1 to denote a positive label and 0 for a negative label, the predictions can fall into one of the four categories.
True Positives: The model predicts a positive class label when the ground truth is also positive. This is the required behaviour as the model can successfully predict a positive label.
False Positives: The model predicts a positive class label when the ground truth label is negative. The model falsely identifies a data sample as positive.
False Negatives: The model predicts a negative class label for a positive example. The model falsely identifies a data sample as negative.
True Negatives: The required behavior as well. The model correctly identifies a negative sample, predicting 0 for a data sample having a ground truth label of 0.
Now, we can build upon these terms to understand how common evaluation metrics work.
Accuracy
This is the most simple yet intuitive way of assessing a model’s performance for classification problems. It measures the proportion of total labels that the model correctly predicted.
Therefore, accuracy can be computed as follows:
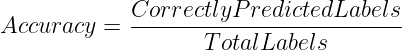
or
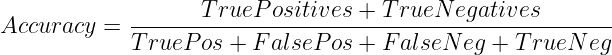
When to Use
- Initial Model Assessment
Given its simplicity, accuracy is a widely used metric. It provides a good starting point for verifying if the model can learn well before we use metrics specific to our problem domain.
- Balanced Datasets
Accuracy is only suitable for balanced datasets where all class labels are in similar proportions. If that is not the case, and one class label significantly outnumbers the others, the model may still achieve high accuracy by always predicting the majority class. The accuracy metric equally penalizes the wrong predictions for each class, making it unsuitable for imbalanced datasets.
- When Misclassification costs are equal
Accuracy is suitable for cases where False Positives or False Negatives are equally bad. For example, for a sentiment analysis problem, it is equally bad if we classify a negative text as positive or a positive text as negative. For such scenarios, accuracy is a good metric.
Precision
Precision focuses on ensuring we get all positive predictions correct. It measures what fraction of the positive predictions were actually positive.
Mathematically, it is represented as
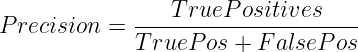
When to Use
- High Cost of False Positives
Consider a scenario where we are training a model to detect cancer. It will be more important for us that we do not misclassify a patient who does not have cancer i.e. False Positive. We want to be confident when we make a positive prediction as wrongly classifying a person as cancer-positive can lead to unnecessary stress and expenses. Therefore, we highly value that we predict a positive label only when the actual label is positive.
- Quality over Quantity
Consider another scenario where we are building a search engine matching user queries to a dataset. In such cases, we value that the search results match closely to the user query. We do not want to return any document irrelevant to the user, i.e. False Positive. Therefore, we only predict positive for documents that match closely to the user query. We value quality over quantity as we prefer a small number of closely related results instead of a high number of results that may or may not be relevant for the user. For such scenarios, we want high precision.
Recall
Recall, also known as Sensitivity, measures how well a model can remember the positive labels in the dataset. It measures what fraction of the positive labels in our dataset the model predicts as positive.
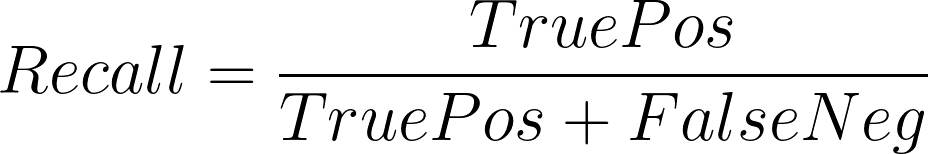
A higher recall means the model is better at remembering what data samples have positive labels.
When to Use
- High Cost of False Negatives
We use Recall when missing a positive label can have severe consequences. Consider a scenario where we are using a Machine Learning model to detect credit card fraud. In such cases, early detection of issues is essential. We do not want to miss a fraudulent transaction as it can increase losses. Hence, we value Recall over Precision, where misclassification of a transaction as deceitful may be easy to verify and we can afford a few false positives over false negatives.
F1-Score
It is the harmonic mean of Precision and Recall. It penalizes models that have a significant imbalance between either metric.
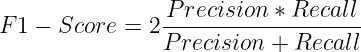
It is widely used in scenarios where both precision and recall are important and allows for achieving a balance between both.
When to Use
- Imbalanced Datasets
Unlike accuracy, the F1-Score is suitable for assessing imbalanced datasets as we are evaluating performance based on the model’s ability to recall the minority class while maintaining a high precision overall.
- Precision-Recall Trade-off
Both metrics are opposite to each other. Empirically, improving one can often lead to degradation in the other. F1-Score aids in balancing both metrics and is useful in scenarios where both Recall and Precision are equally critical. Taking both metrics into account for calculation, the F1-Score is a widely used metric for evaluating classification models.
Key Takeaways
We've learned that different evaluation metrics have specific jobs. Knowing these metrics helps us choose the right one for our task. In real life, it's not just about having good models; it's about having models that fit our business needs perfectly. So, picking the right metric is like choosing the right tool to make sure our model does well where it matters most.
Still confused about which metric to use? Starting with accuracy is a good initial step. It provides a basic understanding of your model's performance. From there, you can tailor your evaluation based on your specific requirements. Alternatively, consider the F1-Score, which serves as a versatile metric, striking a balance between precision and recall, making it suitable for various scenarios. It can be your go-to tool for comprehensive classification evaluation.
Muhammad Arham is a Deep Learning Engineer working in Computer Vision and Natural Language Processing. He has worked on the deployment and optimizations of several generative AI applications that reached the global top charts at Vyro.AI. He is interested in building and optimizing machine learning models for intelligent systems and believes in continual improvement.