 5 Machine Learning Projects You Can No Longer Overlook, January
5 Machine Learning Projects You Can No Longer Overlook, January
 5 Machine Learning Projects You Can No Longer Overlook, January
5 Machine Learning Projects You Can No Longer Overlook, January
There are a lot of popular machine learning projects out there, but many more that are not. Which of these are actively developed and worth checking out? Here is an offering of 5 such projects, the most recent in an ongoing series.
Previous instalments of "5 Machine Learning Projects You Can No Longer Overlook" brought to light a number of lesser-known machine learning projects, and included both general purpose and specialized machine learning libraries and deep learning libraries, along with auxiliary support, data cleaning, and automation tools. After a hiatus, we thought the idea deserved another follow-up.
This post will showcase 5 machine learning projects that you may not yet have heard of, including those from across a number of different ecosystems and programming languages. You may find that, even if you have no requirement for any of these particular tools, inspecting their broad implementation details or their specific code may help in generating some ideas of your own. Like the previous iteration, there is no formal criteria for inclusion beyond projects that have caught my eye over time spent online, and the projects have Github repositories. Subjective, to be sure.
Without further ado, here they are: yet another 5 machine learning projects you should consider having a look at. They are presented in no particular order, but are numbered for convenience, and because numbering things brings me an inner peace that I still don't fully understand.
Hyperopt-sklearn is Hyperopt-based model selection for machine learning algorithms in the scikit-learn project. Directly from the project's documentation:
Finding the right classifier to use for your data can be hard. Once you have chosen a classifier, tuning all of the parameters to get the best results is tedious and time consuming. Even after all of your hard work, you may have chosen the wrong classifier to begin with. Hyperopt-sklearn provides a solution to this problem.
Hyperopt-sklearn uses a variety of search algorithms, can search all (supported) classifiers or only within the parameter space of a given classifier, and supports a number of preprocessing steps such as PCA, TfidfVectorizer, Normalzier, and OneHotEncoder.
Does it work?
The table below shows the F1 scores obtained by classifiers run with scikit-learn's default parameters and with hyperopt-sklearn's optimized parameters on the 20 newsgroups dataset. The results from hyperopt-sklearn were obtained from a single run with 25 evaluations.
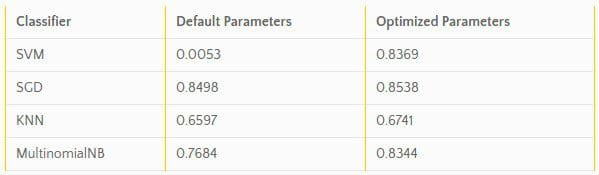
Hyperopt-sklearn rquires very little additional code to get working, and has some handy quick start code to get going with.
2. Dlib
Dlib is a general purpose toolkit for making machine learning and data analysis applications in C++. As in, it's written in C++. But fret not; it also has a Python API.
From the official website:
Dlib is a modern C++ toolkit containing machine learning algorithms and tools for creating complex software in C++ to solve real world problems. It is used in both industry and academia in a wide range of domains including robotics, embedded devices, mobile phones, and large high performance computing environments.
The documentation is up to par, the API is well explained, and the project comes with a concise introduction. A blog is also active, overviewing some interesting projects using the library. Dlib is not new either; it has been under development since 2002.
Given its wide array of available algorithms, I would be quite interested in seeing a side by side comparison of execution times with scikit-learn. Anyone? Anyone?
3. NN++
Staying with C++ for a moment, NN++ is a tiny and easy to use neural net implementation for said language. No installation is necessary; just download and #include.
From its repo:
A short, self-contained, and easy-to-use neural net implementation for C++. It includes the neural net implementation and a Matrix class for basic linear algebra operations. This project is mostly for learning purposes, but preliminary testing results over the MNIST dataset show some promise.
Its documentation is sparse, but it does take some extra care to explain the accompanying Matrix class usage. A few snippets of code explain setting up and querying a neural net. The code is minimal, and so those looking to understand either simple neural networks under the hood or make a move from another language directly to implementing nets in C++, this project is a good place to look.
4. LightGBM
LightGBM is a Microsoft gradient boosted tree algorithm implementation. From the repo:
A fast, distributed, high performance gradient boosting (GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks. It is under the umbrella of the DMTK(http://github.com/microsoft/dmtk) project of Microsoft.
Written in C++ and Python, LightGBM has a quick start guide, a parallel learning guide, and a quality overview of its features.
But how does it perform?
Experiments on public datasets show that LightGBM can outperform other existing boosting framework on both efficiency and accuracy, with significant lower memory consumption. What's more, the experiments show that LightGBM can achieve a linear speed-up by using multiple machines for training in specific settings.
LightGBM, like the rest of the Microsoft Distributed Machine Learning Toolkit, has a number of features that make it seemingly worth checking out.
The projects thus far have been general purpose machine learning toolkits, or implementations of specific algorithms. This project is a bit different, and plays a supportive role for machine learning tasks.
Sklearn-pandas an actively-developed module which "provides a bridge between Scikit-Learn's machine learning methods and pandas-style Data Frames."
More from the repo:
In particular, it provides:
- A way to map DataFrame columns to transformations, which are later recombined into features.
- A compatibility shim for old scikit-learn versions to cross-validate a pipeline that takes a pandas DataFrame as input. This is only needed for scikit-learn<0.16.0 (see #11 for details). It is deprecated and will likely be dropped in skearn-pandas==2.0.
The real use here is mapping columns to transformations. Here is a snippet from the Gitub repo to demonstrate:
array([[ 1. , 0. , 0. , 0.21],
[ 0. , 1. , 0. , 1.88],
[ 0. , 1. , 0. , -0.63],
[ 0. , 0. , 1. , -0.63],
[ 1. , 0. , 0. , -1.46],
[ 0. , 1. , 0. , -0.63],
[ 1. , 0. , 0. , 1.04],
[ 0. , 0. , 1. , 0.21]])
Note that the first three columns are the output of the LabelBinarizer (corresponding to _cat_, _dog_, and _fish_ respectively) and the fourth column is the standardized value for the number of children. In general, the columns are ordered according to the order given when the DataFrameMapper is constructed.
Hopefully you have found something of interest in these projects. Happy machine learning!
Related: