Using Ensembles in Kaggle Data Science Competitions – Part 2
Aspiring to be a Top Kaggler? Learn more methods like Stacking & Blending. In the previous post we discussed about ensembling models by ways of weighing, averaging and ranks. There is much more to explore in Part-2!
By Henk van Veen
Stacked Generalization & Blending
Averaging prediction files is nice and easy, but it’s not the only method that the top Kagglers Repetition code are using. The serious gains start with stacking and blending. Hold on to your top-hats and petticoats: Here be dragons. With 7 heads. Standing on top of 30 other dragons.
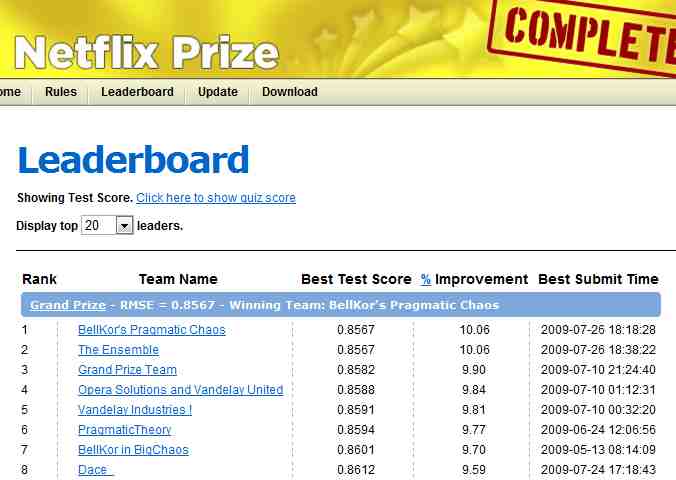
Netflix
Netflix organized and popularized the first data science competitions. Competitors in the movie recommendation challenge really pushed the state of the art on ensemble creation, perhaps so much so that Netflix decided not to implement the winning solution in production. That one was simply too complex.
Nevertheless, a number of papers and novel methods resulted from this challenge:
All are interesting, accessible and relevant reads when you want to improve your Kaggle game.
Stacked generalization
Stacked generalization was introduced by Wolpert in a 1992 paper, 2 years before the seminal Breiman paper “Bagging Predictors“. Wolpert is famous for another very popular machine learning theorem:
“There is no free lunch in search and optimization“.
The basic idea behind stacked generalization is to use a pool of base classifiers, then using another classifier to combine their predictions, with the aim of reducing the generalization error.
Let’s say you want to do 2-fold stacking:
Blending is a word introduced by the Netflix winners. It is very close to stacked generalization, but a bit simpler and less risk of an information leak. Some researchers use “stacked ensembling” and “blending” interchangeably.
With blending, instead of creating out-of-fold predictions for the train set, you create a small holdout set of say 10% of the train set. The stacker model then trains on this holdout set only.
Blending has a few benefits:
However, The cons are:
As for performance, both techniques are able to give similar results, and it seems to be a matter of preference and skill which you prefer. The author prefers stacking.
If you can not choose, you can always do both. Create stacked ensembles with stacked generalization and out-of-fold predictions. Then use a holdout set to further combine these models at a third stage which we will explore next.
Using Ensembles in Kaggle Data Science Competitions – Part 1
Using Ensembles in Kaggle Data Science Competitions – Part 3
How are you planning to implement what you learned? Share your thoughts!
Original: Kaggle Ensembling Guide by Henk van Veen.
Related:
Stacked Generalization & Blending
Averaging prediction files is nice and easy, but it’s not the only method that the top Kagglers Repetition code are using. The serious gains start with stacking and blending. Hold on to your top-hats and petticoats: Here be dragons. With 7 heads. Standing on top of 30 other dragons.
Netflix
Blending hundreds of predictive models to finally cross the finish line.
Netflix organized and popularized the first data science competitions. Competitors in the movie recommendation challenge really pushed the state of the art on ensemble creation, perhaps so much so that Netflix decided not to implement the winning solution in production. That one was simply too complex.
Nevertheless, a number of papers and novel methods resulted from this challenge:
- Feature-Weighted Linear Stacking
- Combining Predictions for Accurate Recommender Systems
- The BigChaos Solution to the Netflix Prize
All are interesting, accessible and relevant reads when you want to improve your Kaggle game.
Stacked generalization
Stacked generalization was introduced by Wolpert in a 1992 paper, 2 years before the seminal Breiman paper “Bagging Predictors“. Wolpert is famous for another very popular machine learning theorem:
The basic idea behind stacked generalization is to use a pool of base classifiers, then using another classifier to combine their predictions, with the aim of reducing the generalization error.
Let’s say you want to do 2-fold stacking:
- Split the train set in 2 parts: train_a and train_b
- Fit a first-stage model on train_a and create predictions for train_b
- Fit the same model on train_b and create predictions for train_a
- Finally fit the model on the entire train set and create predictions for the test set.
- Now train a second-stage stacker model on the probabilities from the first-stage model(s).
A stacker model gets more information on the problem space by using the first-stage predictions as features, than if it was trained in isolation.
BlendingBlending is a word introduced by the Netflix winners. It is very close to stacked generalization, but a bit simpler and less risk of an information leak. Some researchers use “stacked ensembling” and “blending” interchangeably.
With blending, instead of creating out-of-fold predictions for the train set, you create a small holdout set of say 10% of the train set. The stacker model then trains on this holdout set only.
Blending has a few benefits:
- It is simpler than stacking.
- It wards against an information leak: The generalizers and stackers use different data.
- You do not need to share a seed for stratified folds with your teammates. Anyone can throw models in the ‘blender’ and the blender decides if it wants to keep that model or not.
However, The cons are:
- You use less data overall
- The final model may overfit to the holdout set.
- Your CV is more solid with stacking (calculated over more folds) than using a single small holdout set.
As for performance, both techniques are able to give similar results, and it seems to be a matter of preference and skill which you prefer. The author prefers stacking.
If you can not choose, you can always do both. Create stacked ensembles with stacked generalization and out-of-fold predictions. Then use a holdout set to further combine these models at a third stage which we will explore next.
Using Ensembles in Kaggle Data Science Competitions – Part 1
Using Ensembles in Kaggle Data Science Competitions – Part 3
How are you planning to implement what you learned? Share your thoughts!
Original: Kaggle Ensembling Guide by Henk van Veen.
Related:
- How to Lead a Data Science Contest without Reading the Data
- Top 20 R Machine Learning and Data Science packages
- Netflix: Director – Product Analytics, Data Science and Engineering