Using Ensembles in Kaggle Data Science Competitions- Part 3
Earlier, we showed how to create stacked ensembles with stacked generalization and out-of-fold predictions. Now we'll learn how to implement various stacking techniques.
By Henk van Veen
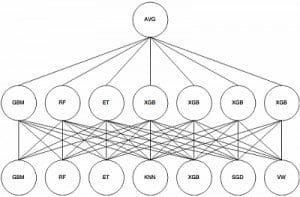 Stacking with logistic regression:
Stacking with logistic regression:
Stacking with logistic regression is one of the more basic and traditional ways of stacking. You can create predictions for the test set in one go, or take an average of the out-of-fold predictors. Either works well.
Though taking the average is a clean and accurate way to do this, you might want to consider one go as that slightly lowers both model and coding complexity.
Kaggle use: “Papirusy z Edhellond”:
The author uses blend.py to compete in this classification competition. By stacking 8 base models (diverse ET’s, RF’s and GBM’s) with Logistic Regression he is able to score 0.99409 accuracy, good for first place.
Kaggle use: KDD-cup 2014:
Here the author again used blend.py to improve a model. The model before stacking scored ~0.605 AUC, and with stacking this improved to ~0.625.
Stacking with non-linear algorithms:
Popular non-linear algorithms for stacking are GBM, KNN, NN, RF and ET. You can note a couple of interesting points here:
Kaggle use: TUT Headpose Estimation Challenge:
The TUT Headpose Estimation challenge can be treated as a multi-class multi-label classification challenge. For every label a separate ensemble model was trained. The key point is that stacking the predicted class probabilities with an extremely randomized trees model improved the scores. The author stacked generalization with standard models and was able to reduce the error by around 30%.
Feature weighted linear stacking:
Feature-weighted linear stacking stacks engineered meta-features together with model predictions. Linear algorithms are used to keep the resulting model fast and simple to inspect.
Quadratic linear stacking of models:
The author framed the name – Quadratic linear stacking of models. It works similar to feature-weighted linear stacking, but creates combinations of model predictions. This technique improved the author's score in many competitions, most noticeably on the Modeling Women’s Healthcare Decision competition on DrivenData.
Stacking classifiers with regressors and vice versa:
By stacking you can use classifiers for regression problems and vice versa. Even though regression is usually not the best classifier. But it is a bit tricky.
Stacking unsupervised learned features:
You can also stack with unsupervised learning techniques as well. A sensible popular technique is the K-Means Clustering. An interested recent addition is to use t-SNE:
Online Stacking:
A good example of online (or semi-) stacking is with ad click prediction. Models trained on recent data perform better here.
Everything is a hyper-parameter:
When doing stacking/blending/meta-modeling, think of every action as a hyper-parameter for the stacker model.
So this makes the below simply extra parameters to be tuned to improve the ensemble performance.
Model Selection:
You can further optimize scores by combining multiple ensembled models.
Automation:
Adding many base models along with multiple stacked ensembles can only get you so far in a competition. For the rest, you might consider the below for automating:
Kaggle use: Otto product classification:
Using the automated stacker in this competition, the author got to top 10% score without any tuning or manual model selection. Here's his approach:
Why create these Frankenstein ensembles?
You may wonder why this exercise in futility: stacking and combining 1000s of models and computational hours is insanity right? Well… yes. But these monster ensembles still have their uses:
See also Using Ensembles in Kaggle Data Science Competitions- Part 1
Using Ensembles in Kaggle Data Science Competitions- Part 2 of this article.
Original post: Kaggle Ensembling Guide by Henk van Veen.
Related:
The natural world is complex, so it figures that ensembling different models can capture more of this complexity- Ben Hamner

Backward propagation of networked models
Stacking with logistic regression is one of the more basic and traditional ways of stacking. You can create predictions for the test set in one go, or take an average of the out-of-fold predictors. Either works well.
Though taking the average is a clean and accurate way to do this, you might want to consider one go as that slightly lowers both model and coding complexity.
Kaggle use: “Papirusy z Edhellond”:
The author uses blend.py to compete in this classification competition. By stacking 8 base models (diverse ET’s, RF’s and GBM’s) with Logistic Regression he is able to score 0.99409 accuracy, good for first place.
Kaggle use: KDD-cup 2014:
Here the author again used blend.py to improve a model. The model before stacking scored ~0.605 AUC, and with stacking this improved to ~0.625.
Stacking with non-linear algorithms:
Popular non-linear algorithms for stacking are GBM, KNN, NN, RF and ET. You can note a couple of interesting points here:
- Non-linear stacking with the original features on multiclass problems gives surprising gains.
- Non-linear algorithms find useful interactions between the original features and the meta-model features.
Kaggle use: TUT Headpose Estimation Challenge:
The TUT Headpose Estimation challenge can be treated as a multi-class multi-label classification challenge. For every label a separate ensemble model was trained. The key point is that stacking the predicted class probabilities with an extremely randomized trees model improved the scores. The author stacked generalization with standard models and was able to reduce the error by around 30%.
Feature weighted linear stacking:
Feature-weighted linear stacking stacks engineered meta-features together with model predictions. Linear algorithms are used to keep the resulting model fast and simple to inspect.
Quadratic linear stacking of models:
The author framed the name – Quadratic linear stacking of models. It works similar to feature-weighted linear stacking, but creates combinations of model predictions. This technique improved the author's score in many competitions, most noticeably on the Modeling Women’s Healthcare Decision competition on DrivenData.
Stacking classifiers with regressors and vice versa:
By stacking you can use classifiers for regression problems and vice versa. Even though regression is usually not the best classifier. But it is a bit tricky.
- You use binning first and turn a regression problem into a multiclass classification problem.
- The predicted probabilities for these classes can help a stacking regressor make better predictions.
Stacking unsupervised learned features:
You can also stack with unsupervised learning techniques as well. A sensible popular technique is the K-Means Clustering. An interested recent addition is to use t-SNE:
- Reduce the dataset to 2 or 3 dimensions.
- stack this with a non-linear stacker.
- Use a holdout set for stacking/blending (safe choice).
Online Stacking:
A good example of online (or semi-) stacking is with ad click prediction. Models trained on recent data perform better here.
- So when a dataset has a temporal effect, you could use Vowpal Wabbit to train on the entire dataset.
- Combine it with a more complex and powerful tool like XGBoost to train on the last day of data.
- Finally stack the XGBoost predictions together with the samples and let Vowpal Wabbit do what it does best - optimizing loss functions.
Everything is a hyper-parameter:
When doing stacking/blending/meta-modeling, think of every action as a hyper-parameter for the stacker model.
So this makes the below simply extra parameters to be tuned to improve the ensemble performance.
- Not scaling the data
- Standard-Scaling the data
- Minmax scaling the data
Model Selection:
You can further optimize scores by combining multiple ensembled models.
- Use averaging, voting or rank averaging on manually-selected well-performing ensembles.
- Start with a base ensemble of 3 or so good models. Add a model when it increases the train set score the most. By allowing put-back of models, a single model may be picked multiple times (weighing).
- Use of genetic algorithms (from Genetic Model Selection) and CV-scores as the fitness function.
- The author uses a fully random method: Create a 100 or so ensembles from randomly selected ensembles (without placeback). Then pick the highest scoring model.
Automation:
Adding many base models along with multiple stacked ensembles can only get you so far in a competition. For the rest, you might consider the below for automating:
- Models visualized as a network can be trained used back-propagation
- Consider CV-scores and their standard deviation (smaller the better).
- There is scope to optimizing complexity/memory usage and running times.
- Also look at making the script prefer uncorrelated model predictions when creating ensembles.
- Consider parallelizing and distributing your automation to improve speed.
Kaggle use: Otto product classification:
Using the automated stacker in this competition, the author got to top 10% score without any tuning or manual model selection. Here's his approach:
- For base models is to generate random algorithms with pure random parameters and train.
- Wrappers can be written to make classifiers like VW, Sofia-ML, RGF, MLP and XGBoost play nicely with the Scikit-learn API.
- For stackers let the script use SVM, random forests, extremely randomized trees, GBM and XGBoost with random parameters and a random subset of base models.
- Finally average the created stackers when their fold-predictions on the train set produces a lower loss.
Why create these Frankenstein ensembles?
You may wonder why this exercise in futility: stacking and combining 1000s of models and computational hours is insanity right? Well… yes. But these monster ensembles still have their uses:
- You can win Kaggle competitions.
- You can beat most state-of-the-art academic benchmarks with a single approach.
- It is possible to transfer knowledge from the ensemble back to a simpler shallow model (Hinton’s Dark Knowledge, Caruana’s Model Compression )
- A good thing about ensembling is that loss of one model is not fatal for creating good predictions.
- Automated large ensembles don't require much tuning or selection.
- A 1% increase in accuracy may push an investment fund from making a loss, into making a little less loss. More seriously: Improving healthcare screening methods helps save lives.
See also Using Ensembles in Kaggle Data Science Competitions- Part 1
Using Ensembles in Kaggle Data Science Competitions- Part 2 of this article.
Original post: Kaggle Ensembling Guide by Henk van Veen.
Related:
- Identity Fraud and Analytics – An Overview
- Cloud Machine Learning Wars: Amazon vs IBM Watson vs Microsoft Azure
- 3 Ways to Test the Accuracy of Your Predictive Models