Python Data Science with Pandas vs Spark DataFrame: Key Differences
A post describing the key differences between Pandas and Spark's DataFrame format, including specifics on important regular processing features, with code samples.
By Christophe Bourguignat.
Editor's note: click images of code to enlarge.
With 1.4 version improvements, Spark DataFrames could become the new Pandas, making ancestral RDDs look like Bytecode.
I use heavily Pandas (and Scikit-learn) for Kaggle competitions. Nobody won a Kaggle challenge with Spark yet, but I’m convinced it will happen. That’s why it’s time to prepare the future, and start using it. Spark DataFrames are available in the pyspark.sql package (strange, and historical name: it’s no more only about SQL!).
I’m not a Spark specialist at all, but here are a few things I noticed when I had a first try. On my GitHub, you can find the IPython Notebook companion of this post.
Reading
With Pandas, you easily read CSV files with read_csv().
Out of the box, Spark DataFrame supports reading data from popular professional formats, like JSON files, Parquet files, Hive table — be it from local file systems, distributed file systems (HDFS), cloud storage (S3), or external relational database systems.

But CSV is not supported natively by Spark. You have to use a separate library: spark-csv.
Counting
sparkDF.count() and pandasDF.count() are not the exactly the same.
The first one returns the number of rows, and the second one returns the number of non NA/null observations for each column.
Not that Spark doesn’t support .shape yet — very often used in Pandas.
Viewing
In Pandas, to have a tabular view of the content of a DataFrame, you typically use pandasDF.head(5), or pandasDF.tail(5). In IPython Notebooks, it displays a nice array with continuous borders.
In Spark, you have sparkDF.head(5), but it has an ugly output. You should prefer sparkDF.show(5). Note that you cannot view the last lines (.tail() does no exist yet, because long to do in distributed environment).
Inferring Types
With Pandas, you rarely have to bother with types: they are inferred for you.
With Spark DataFrames loaded from CSV files, default types are assumed to be “strings”.
EDIT: in spark-csv, there is a ‘inferSchema’ option (disabled by default), but I didn’t manage to make it work. It doesn’t seem to be functional in the 1.1.0 version.
To change types with Spark, you can use the .cast() method, or equivalently .astype(), which is an alias gently created for those like me coming from the Pandas world ;). Note that you must create a new column, and drop the old one (some improvements exist to allow “in place”-like changes, but it is not yet available with the Python API).

Describing
In Pandas and Spark, .describe() generate various summary statistics. They give slightly different results for two reasons:
Wrangling
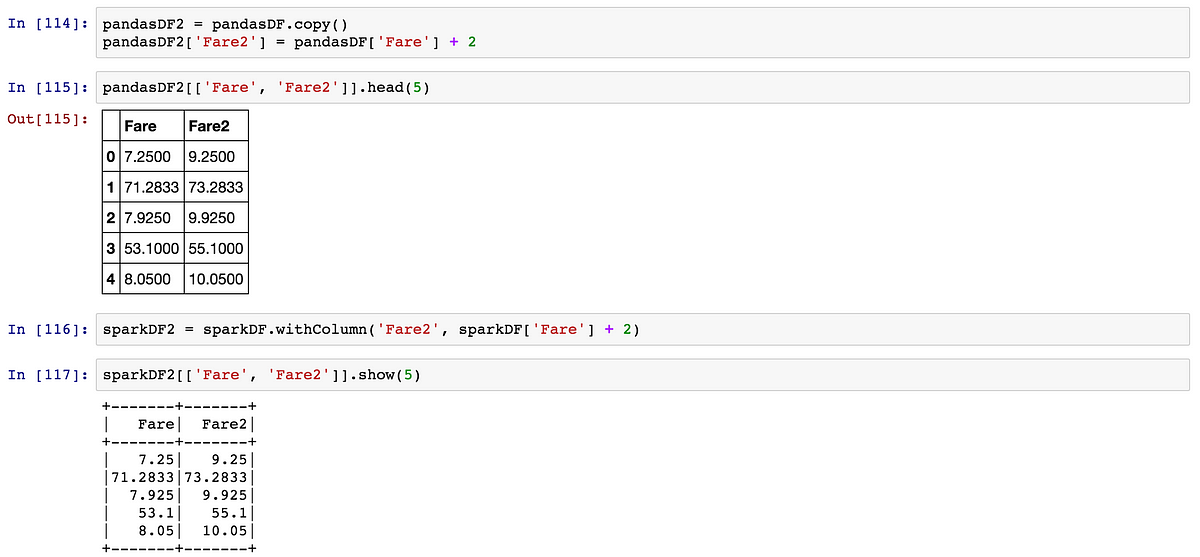
In Machine Learning, it is usual to create new columns resulting from a calculus on already existing columns (features engineering).
In Pandas, you can use the ‘[ ]’ operator. In Spark you can’t — DataFrames are immutable. You should use .withColumn().
Concluding
Spark and Pandas DataFrames are very similar. Still, Pandas API remains more convenient and powerful - but the gap is shrinking quickly.
Despite its intrinsic design constraints (immutability, distributed computation, lazy evaluation, ...), Spark wants to mimic Pandas as much as possible (up to the method names). My guess is that this goal will be achieved soon.
And with Spark.ml, mimicking scikit-learn, Spark may become the perfect one-stop-shop tool for industrialized Data Science.
Thanks to Olivier Girardot for helping to improve this post.
EDIT 1: Olivier just released a new post giving more insights: From Pandas To Apache Spark Dataframes
EDIT 2: Here is another post on the same topic: Pandarize Your Spark Dataframes
Bio: Christophe Bourguignat is a data fan, Kaggle master, blogger, and AXA Data Innovation Lab alumni.
Original. Reposted with permission.
Related:
Editor's note: click images of code to enlarge.
With 1.4 version improvements, Spark DataFrames could become the new Pandas, making ancestral RDDs look like Bytecode.
I use heavily Pandas (and Scikit-learn) for Kaggle competitions. Nobody won a Kaggle challenge with Spark yet, but I’m convinced it will happen. That’s why it’s time to prepare the future, and start using it. Spark DataFrames are available in the pyspark.sql package (strange, and historical name: it’s no more only about SQL!).
I’m not a Spark specialist at all, but here are a few things I noticed when I had a first try. On my GitHub, you can find the IPython Notebook companion of this post.
Reading
With Pandas, you easily read CSV files with read_csv().
Out of the box, Spark DataFrame supports reading data from popular professional formats, like JSON files, Parquet files, Hive table — be it from local file systems, distributed file systems (HDFS), cloud storage (S3), or external relational database systems.

But CSV is not supported natively by Spark. You have to use a separate library: spark-csv.
pandasDF = pd.read_csv('train.csv') sparkDF = sqlContext.read.format('com.databricks.spark.csv').options(header='true').load('train.csv)
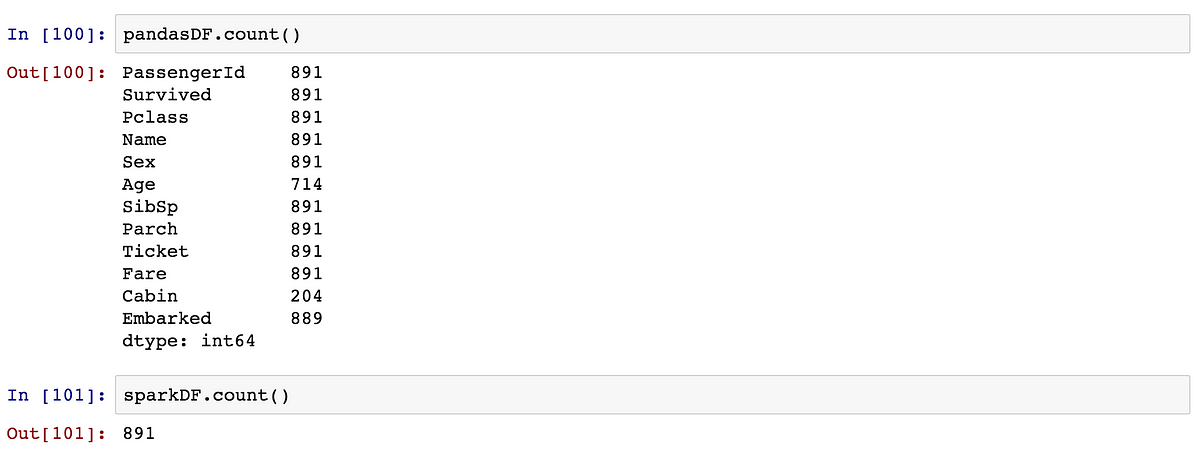
Counting
sparkDF.count() and pandasDF.count() are not the exactly the same.
The first one returns the number of rows, and the second one returns the number of non NA/null observations for each column.
Not that Spark doesn’t support .shape yet — very often used in Pandas.
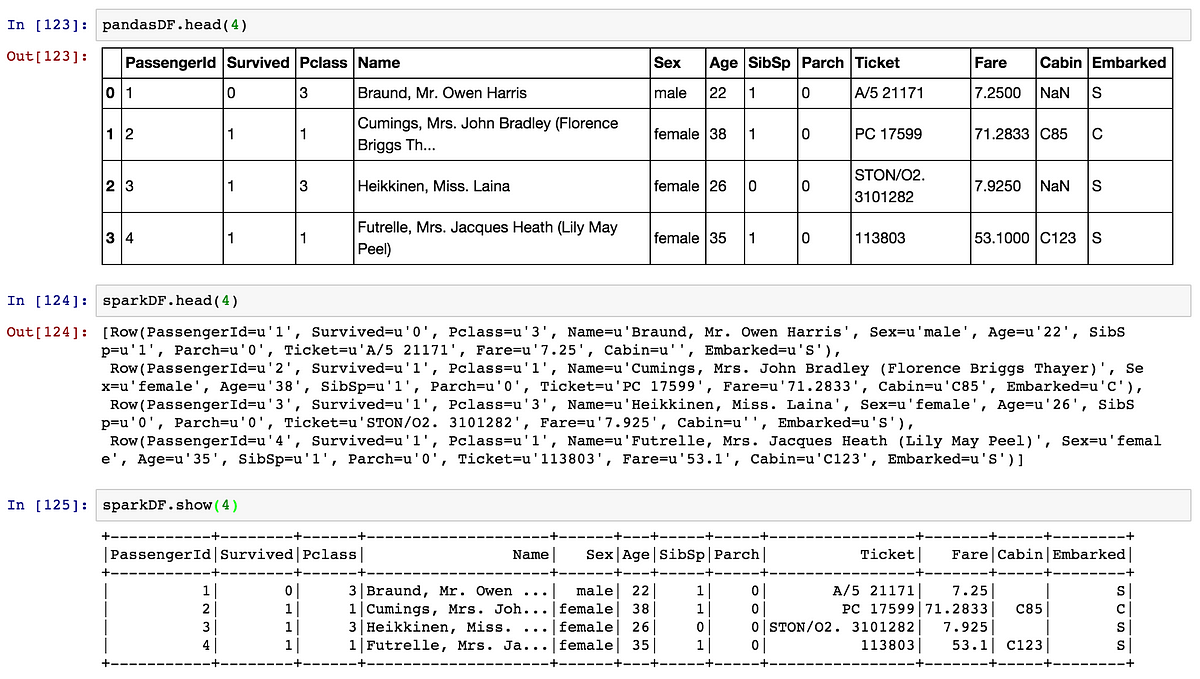
Viewing
In Pandas, to have a tabular view of the content of a DataFrame, you typically use pandasDF.head(5), or pandasDF.tail(5). In IPython Notebooks, it displays a nice array with continuous borders.
In Spark, you have sparkDF.head(5), but it has an ugly output. You should prefer sparkDF.show(5). Note that you cannot view the last lines (.tail() does no exist yet, because long to do in distributed environment).
Inferring Types
With Pandas, you rarely have to bother with types: they are inferred for you.
With Spark DataFrames loaded from CSV files, default types are assumed to be “strings”.
EDIT: in spark-csv, there is a ‘inferSchema’ option (disabled by default), but I didn’t manage to make it work. It doesn’t seem to be functional in the 1.1.0 version.
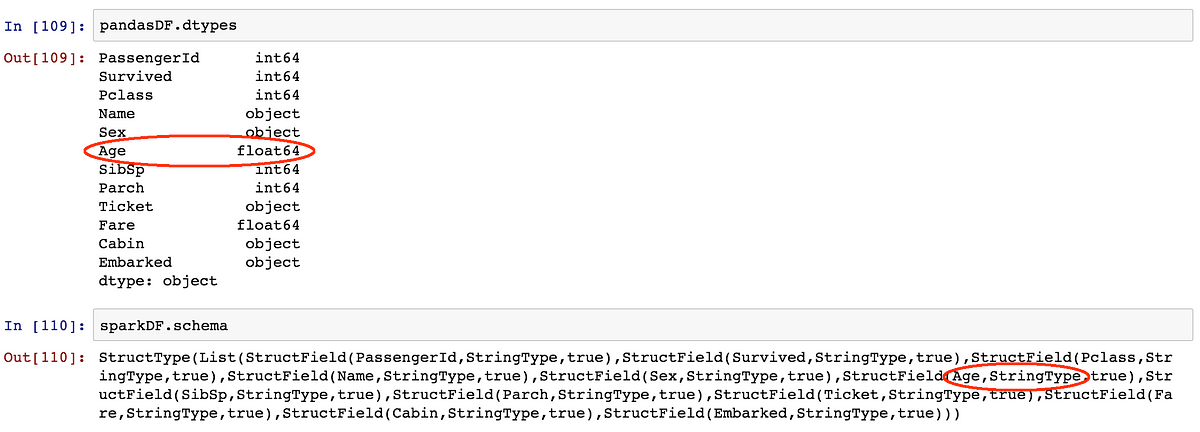
To change types with Spark, you can use the .cast() method, or equivalently .astype(), which is an alias gently created for those like me coming from the Pandas world ;). Note that you must create a new column, and drop the old one (some improvements exist to allow “in place”-like changes, but it is not yet available with the Python API).

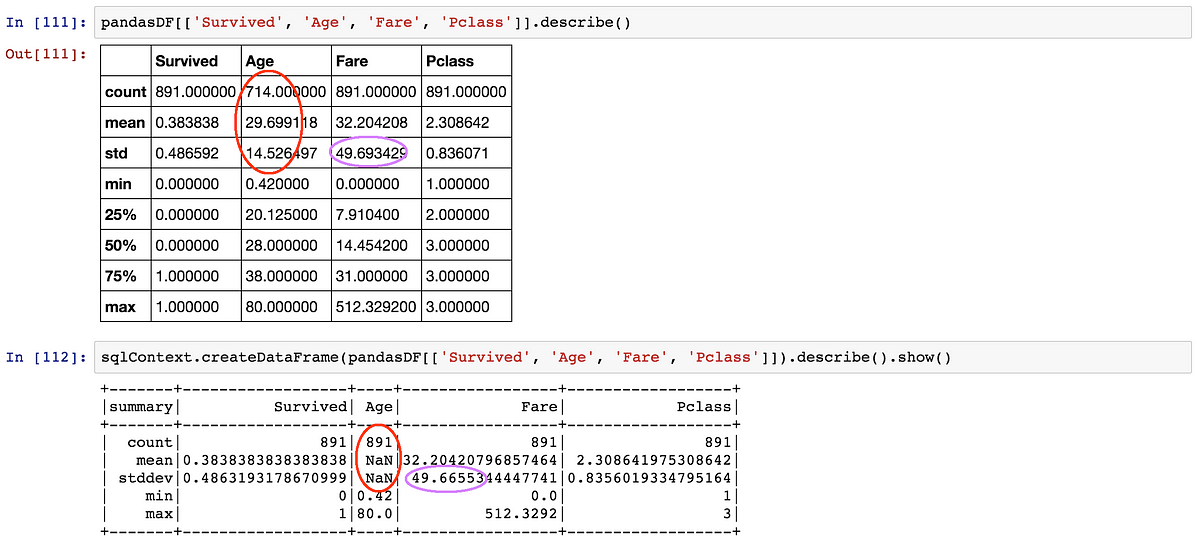
Describing
In Pandas and Spark, .describe() generate various summary statistics. They give slightly different results for two reasons:
- In Pandas, NaN values are excluded. In Spark, NaN values make that computation of mean and standard deviation fail
- standard deviation is not computed in the same way. Unbiased (or corrected) standard deviation by default in Pandas, and uncorrected standard deviation in Spark. The difference is the use of N-1 instead of N on the denominator
Wrangling
In Machine Learning, it is usual to create new columns resulting from a calculus on already existing columns (features engineering).
In Pandas, you can use the ‘[ ]’ operator. In Spark you can’t — DataFrames are immutable. You should use .withColumn().
Concluding
Spark and Pandas DataFrames are very similar. Still, Pandas API remains more convenient and powerful - but the gap is shrinking quickly.
Despite its intrinsic design constraints (immutability, distributed computation, lazy evaluation, ...), Spark wants to mimic Pandas as much as possible (up to the method names). My guess is that this goal will be achieved soon.
And with Spark.ml, mimicking scikit-learn, Spark may become the perfect one-stop-shop tool for industrialized Data Science.
Thanks to Olivier Girardot for helping to improve this post.
EDIT 1: Olivier just released a new post giving more insights: From Pandas To Apache Spark Dataframes
EDIT 2: Here is another post on the same topic: Pandarize Your Spark Dataframes
Bio: Christophe Bourguignat is a data fan, Kaggle master, blogger, and AXA Data Innovation Lab alumni.
Original. Reposted with permission.
Related: