What Developers Actually Need to Know About Machine Learning
Some guidance on what, exactly, it is that developers need to know to get up to speed with machine learning.
By Louis Dorard, PAPIs.io.
Something is wrong in the way ML is being taught to developers.
Most ML teachers like to explain how different learning algorithms work and spend tons of time on that. For a beginner who wants to start using ML, being able to choose an algorithm and set parameters looks like the #1 barrier to entry, and knowing how the different techniques work seems to be a key requirement to remove that barrier. Many practitioners argue however that you only need one technique to get started: random forests. Other techniques may sometimes outperform them, but in general, random forests are the most likely to perform best on a variety of problems (see Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?), which makes them more than enough for a developer just getting started with ML.
I would further argue that you don’t need to know all the inner workings of (random forest) learning algorithms (and the simpler decision tree learning algorithms that they use). A high-level understanding of the algorithms, the intuitions behind them, their main parameters, their possibilities and limitations is enough. You’ll know enough to start practicing and experimenting with ML, as there are great open source ML libraries (such as scikit-learn in Python) and cloud platforms that make it super easy to create predictive models from data.
So, if we just give an overview of only one technique, what else can we teach?

Deploying ML models into production
It turns out that, when using ML in real-world applications, most of the work takes place before and after the learning. ML instructors rarely provide an end-to-end view of what it takes to use ML in a predictive application that’s deployed in production. They just explain one part of the problem, then they assume you’ll figure out the rest and you’ll connect the dots on your own. Like for instance, connecting the dots between the ML libraries you were taught to use in Python, R, or Matlab, and your application in production which is developed in Ruby, Swift, C++, etc.
When I started my PhD almost 10 years ago, I had a friend at Yahoo who had just finished his and who was explaining to me how Software Engineers would re-write the ML researchers’ code into the language used in production. As Dataiku’s Florian Douetteau showed at PAPIs Connect last year, the cost of deploying Proofs of Concept into production could kill ML projects altogether. Deployment is such an important problem that he estimates top companies like Spotify and Facebook each invested more than $5M in their ML production platforms (counting 10–20 people dedicated to that, resources, infrastructure…).
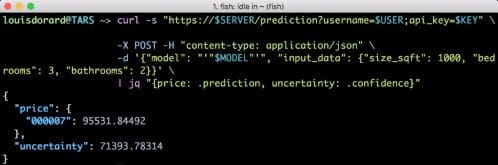
Fortunately, today there are new and accessible solutions to this “last-mile problem”. They revolve around the use of REST (http) APIs. Models need to be exposed as APIs, and if scaling the number of predictions performed by a given model can be an issue, these APIs would be served on multiple endpoints with load balancers in front. Platforms-as-a service can help for that—here is some info about Microsoft Azure ML’s scaling capabilities, Amazon ML’s, and Yhat’s Analytics Load Balancer (which you can also run on your own private infrastructure/cloud). Some of these platforms allow you to use whatever ML library you want, others restrict you to their own proprietary ones. In my upcoming workshop, I’ve chosen to use Azure to deploy models created with scikit-learn into APIs, and also to demonstrate how Amazon and BigML provide an even higher level of abstraction (while still providing accurate models) that can make them easier to work with in many cases.
ML workflow
Deployment is not the only post-learning challenge there is in real-world ML. You should also find appropriate ways to evaluate and monitor your models’ performance/impact, before and after deployment.
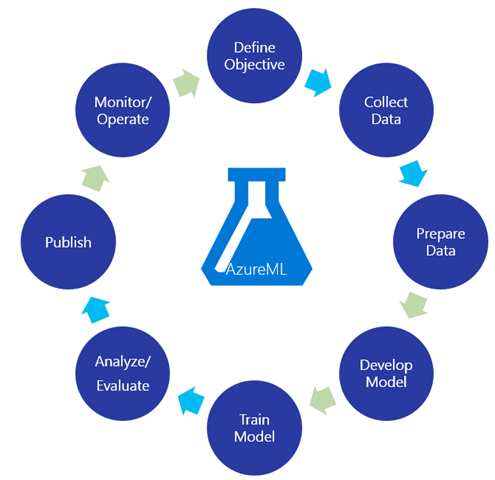
The ML workflow diagram above also presents some of the steps to take before learning a model, which are about preparing the right dataset for the algorithms to run on. Before actually running any algorithm you need to…
- Define the right ML problem to tackle for your organization
- Engineer features, i.e. find ways to represent the objects on which you’ll be making predictions with ML
- Figure out when/how often you’ll need to make predictions, and how much time you’ll have for that (is there a way to do predictions in batches or do you absolutely need all your predictions to be real-time?)
- Collect data
- Prepare the actual dataset to run learning algorithms on, i.e. extract features from the “raw” collected data and clean it
- Figure out when/how often you’ll need to learn new/updated models, and how much time you’ll have for that.
Operational Machine Learning in 2 days
What should be the purpose of an ML course for developers? It shouldn’t just be about teaching something new and interesting and intellectually challenging, but also about making developers as operational as possible in their use of the new techniques they’ve learnt.
At PAPIs, we want to enable developers to improve their apps and create new value from data with Machine Learning. We’re starting a new series of 2-day hands-on workshops in classroom settings and online. The 1st type of workshop we’ve planned is an agnostic introduction to operational ML with open source and cloud platforms. Day 1 covers an intro to ML, the creation, operationalization, and evaluation of predictive models. Day 2 features model selection, ensembles, data preparation, a practical overview of advanced topics such as unsupervised learning and deep learning, and methodology for developing your own ML use case.
We’re using Python with libraries such as Pandas, scikit-learn, SKLL, and cloud platforms such as Microsoft Azure ML, Amazon ML, BigML and Indico. I think these platforms are great for many organizations and real-world use cases, but even if for some reason you’d realize they may not be the perfect fit for you, I’d still recommend using them for learning and practicing ML. ML-as-a-Service makes it much quicker to setup work environments (e.g. Azure ML has most popular libraries preinstalled and can run interactive Jupyter notebooks, which you can access from your browser) but also to experiment with ML with the higher levels of abstraction they provide (e.g. combining one-click clustering, anomaly detection, and classification models with BigML, or quickly featurizing text and images with Indico’s Deep Learning API).
Find out more information about PAPIs.io Operational Machine Learning with Open Source and Cloud Platforms 2-day workshops for developers - in-person and online - approached from the perspective of an application developer, providing an end-to-end view of ML integration into your applications.
Bio: Louis Dorard is the author of Bootstrapping Machine Learning and co-founder of PAPIs.io.
Original. Reposted with permission.
Related: