The big data ecosystem for science: Climate Science and Climate Change
Climate change is one of the most pressing challenges for human society in the 21st century. We review the Big Data ecosystem for studying the climate change.
By Wahid Bhimji, NERSC
This is part 3, a continuation of the post on Big Data Ecosystem for Science and Big Data Ecosystem for Science: Genomics.
Primary Collaborator: Shane Cannon (LBNL)
Introduction
Climate change is one of the most pressing challenges for human society in the 21st century. Studying how the climate system has evolved over the latter half of the 20th century is largely enabled by a combination of conventional weather stations, ocean sensors, and global satellites. To better understand future climate regimes, we must turn to high-fidelity simulations. CAM5 (Community Atmospheric Model) is a state-of-the-art climate model that, when run at 25-km resolution for a simulated period of three decades, produces more than 100 TB of complex, multivariate data. The 2007 Nobel Peace Prize was awarded to the Intergovernmental Panel on Climate Change (IPCC), which analyzed terabytes of climate simulation data. Storing, managing, accessing, and analyzing such large data sets is key for summarizing global quantities (e.g., mean temperature, sea-level rise) as well as localized extremes (e.g., intensity and frequency of tropical cyclones). The scientific community, policy makers, and the broader public can use this information to understand implications of various emission scenarios and the impact on human society.
Data generation
Climate scientists routinely exercise complex, large-scale climate simulation codes (CAM, WRF, CESM, MPAS, etc.) in a highly parallel fashion on O (10,000) cores on high-performance computing systems (e.g., Edison and Cori at NERSC). These simulations can be configured to explore a broad range of scenarios (e.g., how will the Earth warm under a business-as-usual scenario versus broad adoption of carbon-emission-friendly technologies). A different class of codes are also run in “re-analysis” mode, which produces interpolate satellite and weather station data to produce global maps. International products (NCEP, ECMWF, 20CR, JRA-55, etc.) from various modeling centers are readily available for the research community. Perhaps the most elaborate set of simulations are conducted under the Coupled Model Intercomparison Project(CMIP). The CMIP Phase 5 (CMIP5) data set comprises more than 5 PB of data representing more than 25 climate models from various countries.
Data storage
The climate simulation community realized early on that subscribing to a common standard and storage format was key for sharing and disseminating the results of various codes. A common format also meant that a host of analytics capabilities could easily be applied to output and that the results of various modeling efforts could be readily compared. The climate community uses Network Common Data Form (NetCDF) for storing data. There are two popular variants: NetCDF-4 (which is layered on top of HDF5) and PnetCDF. NetCDF provides for relatively rich semantics; the community has adopted the climate and forecast (CF) metadata conventions for standardizing names of variables, dimensions, and attributes. Broad adoption of these standards has enabled the climate community to work coherently across boundaries of various funding agencies and nations. Large-scale, international projects like the IPCC partially owe their success to the adoption of NetCDF and CF conventions.
Data transfer and access
Currently, the Earth System Grid Federation (ESGF) is a de facto gateway for accessing CMIP5 data. Various modeling groups publish their results in conformance with the data standards required by ESGF. This drastically reduces the complexity of all downstream analysis: any researcher in the world can specify a model, time period, and variable of interest, then download and analyze the data sets on their local resource using the ESGF portal (see Figure 5).
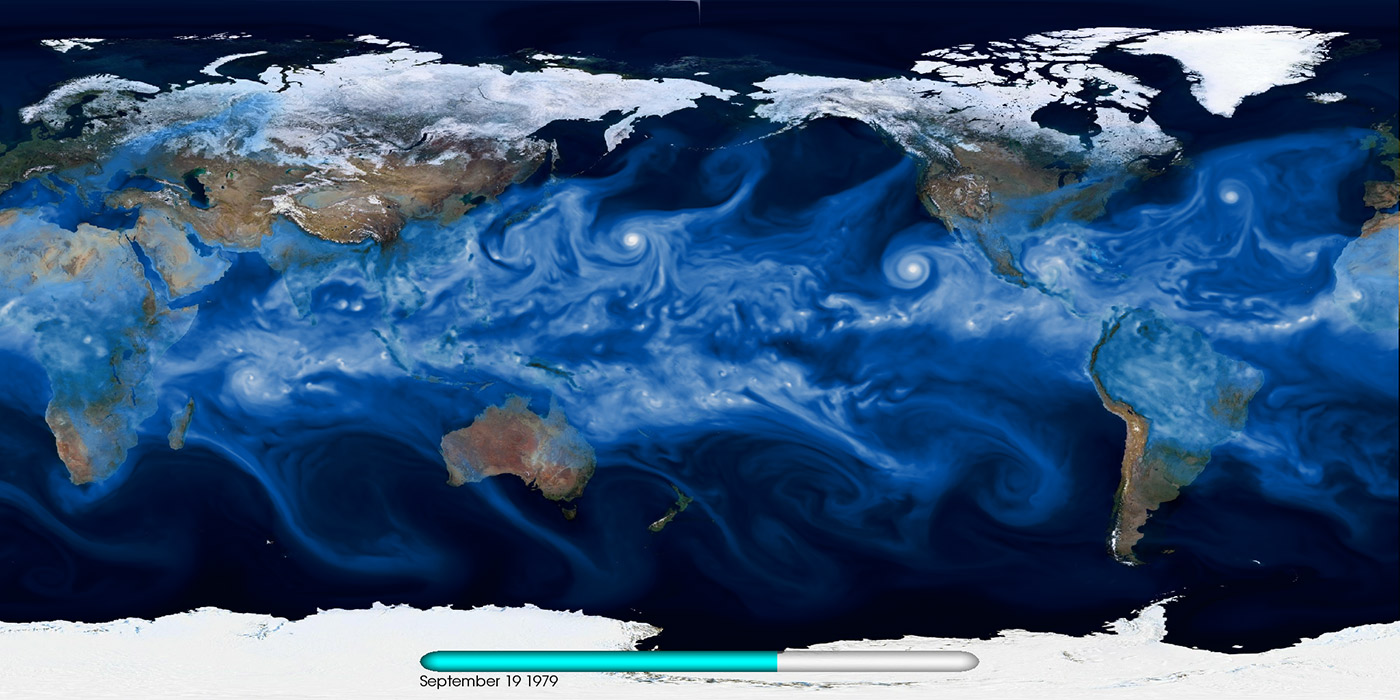
Figure 5. Snapshot of water vapor from a high-resolution CAM5 model output. Source: Prabhat and Michael Wehner, LBNL; used with permission.
Data processing and analysis
Processing tens of terabytes worth of multivariate climate simulation data presents unique challenges. Until recently, stand-alone serial codes like CDO, NCO, and CDAT have largely been used to compute spatial averages, trends, and summary statistics. Recent tools like TECA (Toolkit for Extreme Climate Analytics) have finally bridged the gap between HPC systems and large simulation data sets. It is now possible to detect extreme weather patterns on 10-TB-sized data sets in one hour. Historically, the climate data analytics community has been prescriptive about its definitions of patterns. As data volumes explode, it is inevitable that the community will leverage and adopt machine learning capabilities to automatically detect both patterns and anomalies in climate data. Preliminary work that demonstrates the effectiveness of deep learning in reproducing human-labeled extreme weather patterns lends credibility to this investigation.
The future
As we look toward the future of climate science within the Department of Energy, powerful petascale and exascale-class HPC systems will facilitate more accurate simulations of the global climate system. We will be able to improve spatial scales to permit cloud-resolving simulations, and the representations and coupling of various atmospheric, oceanic, and land processes will improve with time. With improvements in statistical methods, we will be able to better characterize various sources of uncertainty for the future. We expect such simulations to easily produce petabytes of data, which will radically increase the complexity of all stages in the data pipeline: storing, managing, moving, and accessing such large volumes will be a challenge.
This post originally appeared on oreilly.com,
organizers of Strata Hadoop World. Republished with permission.
Strata + Hadoop World | March 13–16, 2017 | San Jose, CA
"One of the most valuable events to advance your career."
Strata + Hadoop World is a rich learning experience at the intersection of data science and business. Thousands of innovators, leaders, and practitioners gather to develop new skills, share best practices, and discover how tools and technologies are evolving to meet new challenges. Find out how big data, machine learning, and analytics are changing not only business, but society itself at Strata + Hadoop World. Save 20% on most passes with discount code PCKDNG.
www.oreilly.com/pub/cpc/35776
Related: