Four Problems in Using CRISP-DM and How To Fix Them
CRISP-DM is the leading approach for managing data mining, predictive analytic and data science projects. CRISP-DM is effective but many analytic projects neglect key elements of the approach.
CRISP-DM – the CRoss Industry Standard Process for Data Mining – is by far the most popular methodology for data mining (see this KDnuggets poll for instance). Analytics Managers use CRISP-DM because they recognize the need for a repeatable approach. However, there are some persistent problems with how CRISP-DM is generally applied. The top four problems are a lack of clarity, mindless rework, blind hand-offs to IT and a failure to iterate. Decision modeling and decision management can address these problems, maximizing the value of CRISP-DM and ensuring analytic success.
The phases of the complete CRISP-DM approach are shown in Figure 1. These phases set up the business problem (Business Understanding), review the available data (Data Understanding), develop analytic models (Data Preparation and Modeling), evaluate results against business need (Evaluation) and deploy the model (Deployment). The whole cycle is designed to be iterative, repeating as necessary to keep models current and effective.
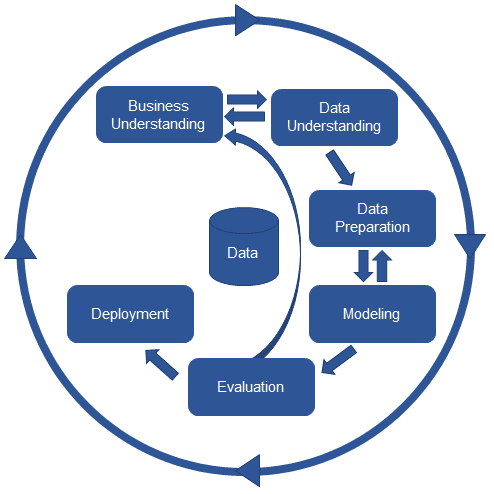
Figure 1: Complete CRISP-DM Approach
CRISP-DM is a great framework and its use on projects helps focus them on delivering real business value. CRISP-DM has been around a long time so many projects that are using CRISP-DM are taking shortcuts. Some of these shortcuts make sense but too often they result in projects using a corrupted version of the approach like the one shown in Figure 2.
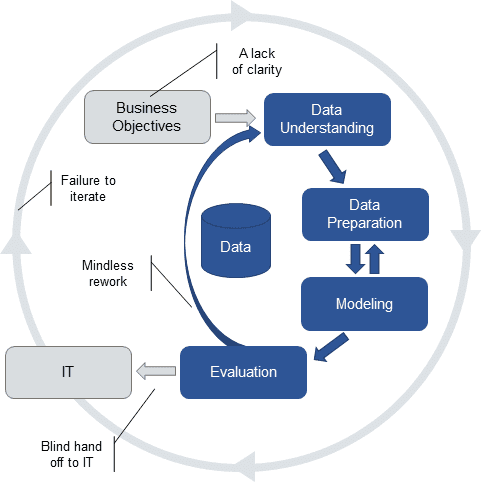
Figure 2: Typical corrupted variation of CRISP-DM
The four problems with this corrupted approach are:
- A lack of clarity
Rather than drill down into the details and really get clarity on both the business problem and exactly how an analytic might help, the project team make do with the business goals and some metrics to measure success. Now they “understand” the business objective, they want to minimize “overhead” and leap into the “interesting” bit of the project, analyzing the data. Too often this results in interesting models that don’t meet a real business need. - Mindless rework
Some analytic teams simply assess their project results in analytic terms – if the model is predictive then it must be good. Most realize that this is not necessarily true and try and check their analytic results against the business objective. This is difficult without real clarity on the business problem. If the analytic they have developed does not seem to meet the business objectives, the team has few options. Most try to find new data or new modeling techniques rather than working with their business partners to re-evaluate the business problem. - Blind hand-off to IT
Some analytic teams don’t think about deployment and operationalization of their models at all. Most do better than that, though, recognizing that the models they build will have to be applied to live data in operational data stores or embedded in operational systems. Even these teams have typically not engaged with IT prior to this point don’t have clarity on how the analytic needs to be deployed and don’t really regard deployment as “analytic” work. The end result is a model that is thrown over the wall to IT. Whether the model is easy to implement or hard (or impossible) and whether it’s really usable once deployed is someone else’s problem. This increases the time and cost of deploying a model and contributes to the huge percentage of models that never have a business impact. - Failure to iterate
Analytic professionals know that models age and that models need to be kept up to date if they are to continue to be valuable. They know that business circumstances can change and undermine the value of a model. They know that the data patterns that drove the model may change in the future. But they think of that as a problem for another day – they don’t have enough clarity on the business problem to determine how to track the model’s business performance nor do they invest in thinking about to make revision of the model less work than the initial creation. After all, it’s much more interesting to tackle another new problem. This leaves aging models unmonitored and unmaintained, undermining the long term value of analytics.
Each of these problems adds to the likelihood that the team will build an impressive analytic solution that will not add business value. Organizations that want to really exploit analytics – especially more advanced analytics like data mining, predictive analytics and machine learning – cannot afford these problems to persist.
Fixing the problems revolves around a clear and unambiguous focus on decision-making – what decision must be improved, what does it mean to improve it, does the analytic actually improve it, which systems and processes embed or support this decision-making and what environment changes might cause a re-evaluation of the decision making?
Two subsequent articles will show how a focus on decisions – and decision modeling – addresses these challenges. The first will address the problems of clarity and rework..The second will address the problems of deployment and iteration.
Related: