Machine Learning-driven Firewall
Cyber Security is always a hot topic in IT industry and machine learning is making security systems more stronger. Here, a particular use case of machine learning in cyber security is explained in detail.
By Faizan Ahmad, CEO Fsecurify.
Lately, I have been thinking of ways of applying machine learning to a security project that I can do and share with all of you. A few days ago, I happened to come across a website called ZENEDGE which is offering AI driven web application firewall. I liked the concept and thought of making something similar and sharing it with the community. So, lets make one.
fWaf – Machine learning driven Web Application Firewall
Dataset:
The first thing to do was to find labelled data but the data I could find was quite old (2010). There is a website called SecRepo that has a lot of security related datasets. One of them was of http logs containing millions of queries. That was the dataset I wanted but it was not labelled. I used some heuristics and my previous knowledge of security to label the data set by writing a few scripts.
After pruning the data, I wanted to collect some more malicious queries. Therefore, I went on for payloads and found some famous GitHub repositories containing Xss, SQL and other attack payloads and used all of them in my malicious queries dataset.
Now, we had two files; one containing clean web queries(1000000) and another one containing malicious web queries(50000). That’s all the data we need to train our classifier.
Training:
For training, I used logistic regression since it is fast and I wanted something fast. We can use SVM or Neural networks but they take a little more time than logistic regression. Our problem is a binary classification problem since we have to predict whether a query is malicious or not. We’ll be using ngrams as our tokens. I read some research papers and using ngrams was a good idea for this sort of project. For this project, I used n=3.
Lets dive right into the code.
Lets define our tokenizer function which will give 3 grams.
def getNGrams(query): tempQuery = str(query) ngrams = [] for i in range(0,len(tempQuery)-3): ngrams.append(tempQuery[i:i+3]) return ngrams
Lets load the queries dataset.
filename = 'badqueries.txt'
directory = str(os.getcwd())
filepath = directory + "/" + filename
data = open(filepath,'r').readlines()
data = list(set(data))
badQueries = []
validQueries = []
count = 0
for d in data:
d = str(urllib.unquote(d).decode('utf8'))
badQueries.append(d)
filename = 'goodqueries.txt'
directory = str(os.getcwd())
filepath = directory + "/" + filename
data = open(filepath,'r').readlines()
data = list(set(data))
for d in data:
d = str(urllib.unquote(d).decode('utf8'))
validQueries.append(d)
Now that we have the dataset loaded into good queries and bad queries. Lets try to visualize them. I used Principal component analysis to visualize the dataset. The read are the bad query ngrams and the blue are the good query ngrams.
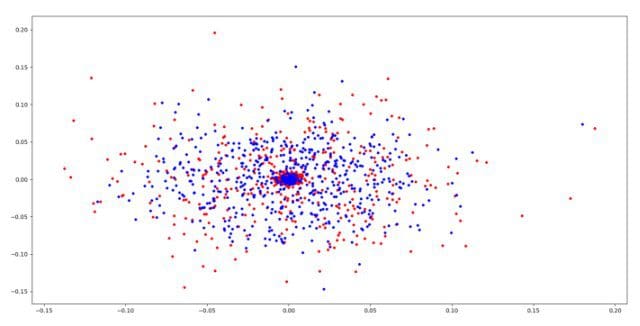
We can see that bad points and good points are indeed on coming out on different positions. Lets proceed further.
badQueries = list(set(badQueries)) tempvalidQueries = list(set(validQueries])) tempAllQueries = badQueries + tempvalidQueries bady = [1 for i in range(0,len(tempXssQueries))] goody = [0 for i in range(0,len(tempvalidQueries))] y = bady+goody queries = tempAllQueries
Lets now use Tfidvectorizer to convert the data into tfidf values and then use our classifier. We are using tfidf values since we want to assign weights to our ngrams e.g the ngram ‘<img’ should have large weight since a query containing this ngram is most likely to be malicious. You can read more about tfidf in this link.
vectorizer = TfidfVectorizer(tokenizer=getNGrams) X = vectorizer.fit_transform(queries) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Now that we have everything set up, lets apply logistic regression.
lgs = LogisticRegression() lgs.fit(X_train, y_train) print(lgs.score(X_test, y_test))
That’s it.
Here’s the part everyone waits for, you must be wanting to see the accuracy, right? The accuracy comes out to be 99%. That’s pretty amazing right? But you won’t believe it until you see some proof. So, lets check some queries and see if the model detects them as malicious or not. Here are the results.
wp-content/wp-plugins (CLEAN) <script>alert(1)</script> (MALICIOUS) SELECT password from admin (MALICIOUS) "> (MALICIOUS) /example/test.php (CLEAN) google/images (CLEAN) q=../etc/passwd (MALICIOUS) javascript:confirm(1) (MALICIOUS) "> (MALICIOUS) foo/bar (CLEAN) foooooooooooooooooooooo (CLEAN) example/test/q=<script>alert(1)</script> (MALICIOUS) example/test/q= (MALICIOUS) fsecurify/q= (MALICIOUS) example/test/q= (MALICIOUS)
Looks good, doesn’t it? It can detect the malicious queries very well.
What next? This is a weekend project and there is a lot that can be done or added in it. We can do multi class classification to detect whether a malicious query is SQL Injection or Cross site scripting or any other injection. We can have a larger dataset with all types of malicious queries and train the model on it thus expanding the type of malicious queries it can detect. One can also save this model and use it with a web server. Let me know if you do any of the above.
Data and script: https://github.com/faizann24/F
I hope you liked the post. We believe in providing security resources for free to the community. Let me know about your comments and critique.
Fsecurify
Bio: Faizan Ahmad is Fulbright undergraduate currently studying in NUCES FAST, Lahore.
Related: