Unlock the Secrets to Choosing the Perfect Machine Learning Algorithm!
When working on a data science problem, one of the most important choices to make is selecting the appropriate machine learning algorithm.
One of the key decisions you need to make when solving a data science problem is which machine learning algorithm to use.
There are hundreds of machine learning algorithms to choose from, each with its own advantages and disadvantages. Some algorithms may work better than others on specific types of problems or on specific data sets.
The “No Free Lunch” (NFL) theorem states that there is no one algorithm that works best for every problem, or in other words, all algorithms have the same performance when their performance is averaged over all the possible problems.
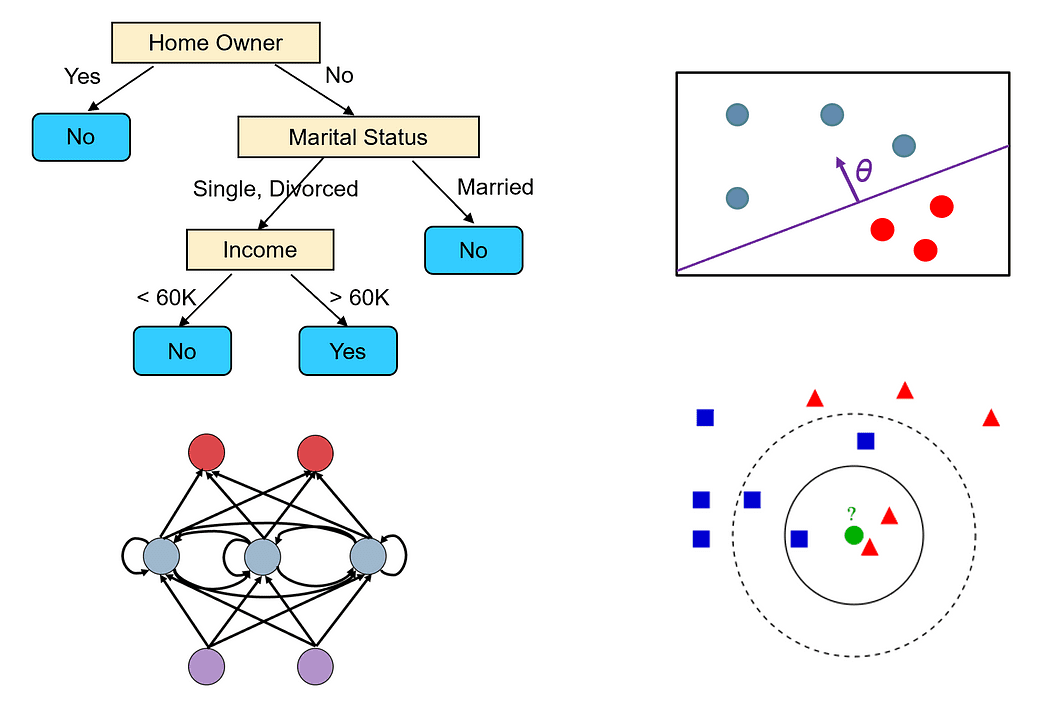
Different machine learning models
In this article, we will discuss the main points you should consider when choosing a model for your problem and how to compare different machine learning algorithms.
Key Algorithm Aspects
The following list contains 10 questions you may ask yourself when considering a specific machine-learning algorithm:
- Which type of problems can the algorithm solve? Can the algorithm solve only regression or classification problems, or can it solve both? Can it handle multi-class/multi-label problems or only binary classification problems?
- Does the algorithm have any assumptions about the data set? For example, some algorithms assume that the data is linearly separable (e.g., perceptron or linear SVM), while others assume that the data is normally distributed (e.g., Gaussian Mixture Models).
- Are there any guarantees about the performance of the algorithm? For example, if the algorithm tries to solve an optimization problem (as in logistic regression or neural networks), is it guaranteed to find the global optimum or only a local optimum solution?
- How much data is needed to train the model effectively? Some algorithms, like deep neural networks, are more data-savvy than others.
- Does the algorithm tend to overfit? If so, does the algorithm provide ways to deal with overfitting?
- What are the runtime and memory requirements of the algorithm, both during training and prediction time?
- Which data preprocessing steps are required to prepare the data for the algorithm?
- How many hyperparameters does the algorithm have? Algorithms that have a lot of hyperparameters take more time to train and tune.
- Can the results of the algorithm be easily interpreted? In many problem domains (such as medical diagnosis), we would like to be able to explain the model’s predictions in human terms. Some models can be easily visualized (such as decision trees), while others behave more like a black box (e.g., neural networks).
- Does the algorithm support online (incremental) learning, i.e., can we train it on additional samples without rebuilding the model from scratch?
Algorithm Comparison Example
For example, let’s take two of the most popular algorithms: decision trees and neural networks, and compare them according to the above criteria.
Decision Trees
- Decision trees can handle both classification and regression problems. They can also easily handle multi-class and multi-label problems.
- Decision tree algorithms do not have any specific assumptions about the data set.
- A decision tree is built using a greedy algorithm, which is not guaranteed to find the optimal tree (i.e., the tree that minimizes the number of tests required to classify all the training samples correctly). However, a decision tree can achieve 100% accuracy on the training set if we keep extending its nodes until all the samples in the leaf nodes belong to the same class. Such trees are usually not good predictors, as they overfit the noise in the training set.
- Decision trees can work well even on small or medium-sized data sets.
- Decision trees can easily overfit. However, we can reduce overfitting by using tree pruning. We can also use ensemble methods such as random forests that combine the output of multiple decision trees. These methods suffer less from overfitting.
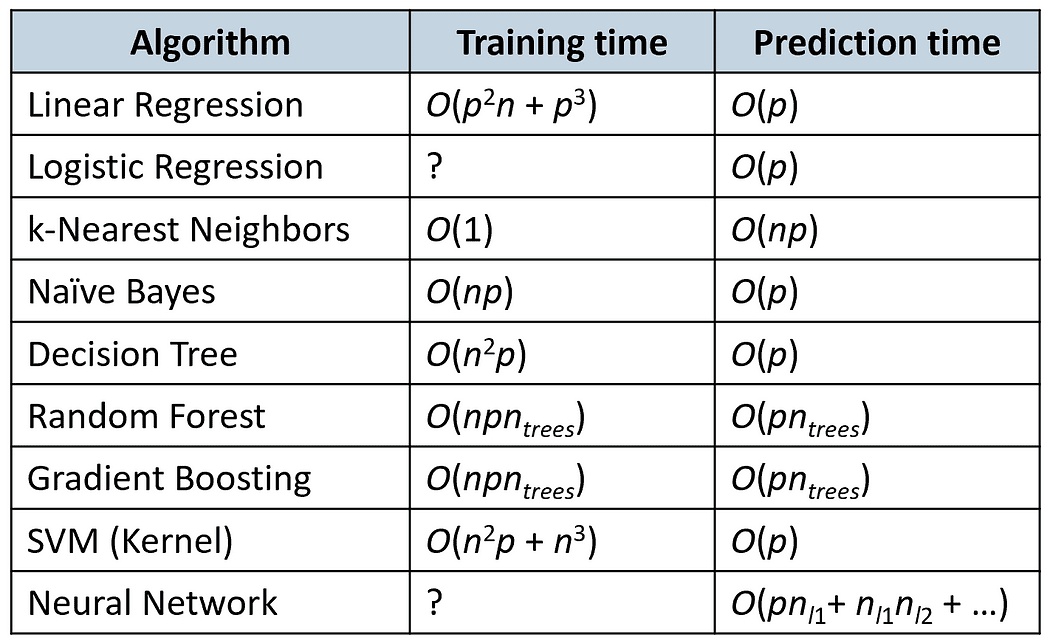
- The time to build a decision tree is O(n²p), where n is the number of training samples, and p is the number of features. The prediction time in decision trees depends on the height of the tree, which is usually logarithmic in n, since most decision trees are fairly balanced.
- Decision trees do not require any data preprocessing. They can seamlessly handle different types of features, including numerical and categorical features. They also do not require normalization of the data.
- Decision trees have several key hyperparameters that need to be tuned, especially if you are using pruning, such as the maximum depth of the tree and which impurity measure to use to decide how to split the nodes.
- Decision trees are simple to understand and interpret, and we can easily visualize them (unless the tree is very large).
- Decision trees cannot be easily modified to take into account new training samples since small changes in the data set can cause large changes in the topology of the tree.
Neural Networks
- Neural networks are one of the most general and flexible machine learning models that exist. They can solve almost any type of problem, including classification, regression, time series analysis, automatic content generation, etc.
- Neural networks do not have assumptions about the data set, but the data needs to be normalized.
- Neural networks are trained using gradient descent. Thus, they can only find a local optimum solution. However, there are various techniques that can be used to avoid getting stuck in local minima, such as momentum and adaptive learning rates.
- Deep neural nets require a lot of data to train in the order of millions of sample points. In general, the larger the network is (the more layers and neurons it has), more we need data to train it.
- Networks that are too large might memorize all the training samples and not generalize well. For many problems, you can start from a small network (e.g., with only one or two hidden layers) and gradually increase its size until you start overfitting the training set. You can also add regularization in order to deal with overfitting.
- The training time of a neural network depends on many factors (the size of the network, the number of gradient descent iterations needed to train it, etc.). However, prediction time is very fast since we only need to do one forward pass over the network to get the label.
- Neural networks require all the features to be numerical and normalized.
- Neural networks have a lot of hyperparameters that need to be tuned, such as the number of layers, the number of neurons in each layer, which activation function to use, the learning rate, etc.
- The predictions of neural networks are hard to interpret as they are based on the computation of a large number of neurons, each of which has only a small contribution to the final prediction.
- Neural networks can easily adapt to include additional training samples, as they use an incremental learning algorithm (stochastic gradient descent).
Time Complexity
The following table compares the training and prediction times of some popular algorithms (n is the number of training samples and p is the number of features).
Most Successful Algorithms in Kaggle Competitions
According to a survey that was done in 2016, the most frequently used algorithms by Kaggle competition winners were gradient boosting algorithms (XGBoost) and neural networks (see this article).
Amongst the 29 Kaggle competition winners in 2015, 8 of them used XGBoost, 9 used deep neural nets, and 11 used an ensemble of both.
XGBoost was mainly used in problems that dealt with structured data (e.g., relational tables), whereas neural networks were more successful in handling unstructured problems (e.g., problems that deal with image, voice, or text).
It would be interesting to check if this is still the situation today or whether the trends have changed (is anyone up for the challenge?)
Thanks for reading!
Dr. Roi Yehoshua is a teaching professor at Northeastern University in Boston, teaching classes that make up the Master's program in Data Science. His research in multi-robot systems and reinforcement learning has been published in the top leading journals and conferences in AI. He is also a top writer on the Medium social platform, where he frequently publishes articles on Data Science and Machine Learning.
Original. Reposted with permission.