Top /r/MachineLearning Posts, March: A Super Harsh Guide to Machine Learning; Is it Gaggle or Koogle?!?
A Super Harsh Guide to Machine Learning; Google is acquiring data science community Kaggle; Suggestion by Salesforce chief data scientist; Andrew Ng resigning from Baidu; Distill: An Interactive, Visual Journal for Machine Learning Research
In March on /r/MachineLearning we are treated to a super harsh guide to machine learning, find that Google is acquiring Kaggle, get pro-supervised learning advice from Salesforce's chief data scientist, hear a goodbye from Andrew Ng as he resigns from Baidu, and learn more exciting info about Distill, the web-based "Interactive, Visual Journal for Machine Learning Research."

The top 5 /r/MachineLearning posts of the past month are:
1. A Super Harsh Guide to Machine Learning
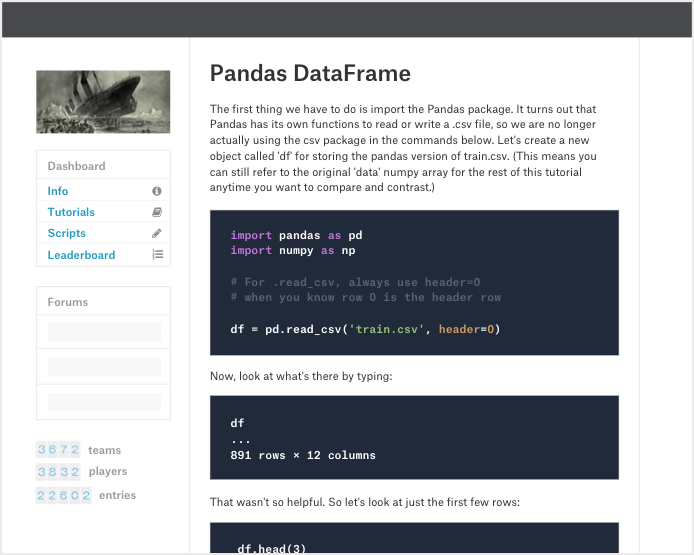
This short, blunt guide to machine learning was written by /u/thatguydr, whose succinctness is admirable. His entire guide -- which is expanded upon, discussed, and has materials sourced by others in the ensuing discussion -- is below:
First, read f***ing Hastie, Tibshirani, and whoever. Chapters 1-4 and 7. If you don't understand it, keep reading it until you do.
You can read the rest of the book if you want. You probably should, but I'll assume you know all of it.
Take Andrew Ng's Coursera. Do all the exercises in Matlab and python and R. Make sure you get the same answers with all of them.
Now forget all of that and read the deep learning book. Put tensorflow or torch on a Linux box and run examples until you get it. Do stuff with CNNs and RNNs and just feed forward NNs.
Once you do all of that, go on arXiv and read the most recent useful papers. The literature changes every few months, so keep up.
There. Now you can probably be hired most places. If you need resume filler, so some Kaggle competitions. If you have debugging questions, use StackOverflow. If you have math questions, read more. If you have life questions, I have no idea.
It's beautiful in both its honesty and accuracy. And I'm a little upset that there is no life advice to follow, because this is the kind of guy (or gal) I expect would be pretty good at dishing it out.
2. Google is acquiring data science community Kaggle
Google buys Kaggle. This shouldn't comes as a huge surprise, given:
Kaggle has a bit of a history with Google, too, but that’s pretty recent. Earlier this month, Google and Kaggle teamed up to host a $100,000 machine learning competition around classifying YouTube videos. That competition had some deep integrations with the Google Cloud Platform, too.
We'll see what Google's endgame is vis-a-vis Kaggle, but there are all sorts of possibilities for crossover here. The event is either exciting or terrifying, depending on your views on potential monopolies. But it's a great branding move, and can help Google extend their recent interests in becoming the lone global machine learning behemoth.
3. Suggestion by Salesforce chief data scientist
Some advice via tweet from Salesforce's Chief Scientist, Richard Socher:

Even though this is an apples and oranges comparison ("Rather than eating a meat lovers pizza, just go chop some wood"), I can see where he is coming from to some extent. It would be a great educational undertaking, and could support the community at large, especially so if he were to encourage the sharing of said curated dataset afterward. But really, in general, I wouldn't think that everyone working on unsupervised learning problems would or should go out and label classification data. That clearly wouldn't lead to progress in unsupervised learning.
4. Andrew Ng resigning from Baidu
In a post on his Medium blog, Andrew Ng announces his resignation from Baidu and what his upcoming plans are. Spoiler alert: he isn't opening a seafood restaurant in Van Nuys:
I will continue my work to shepherd in this important societal change. In addition to transforming large companies to use AI, there are also rich opportunities for entrepreneurship as well as further AI research. I want all of us to have self-driving cars; conversational computers that we can talk to naturally; and healthcare robots that understand what ails us. The industrial revolution freed humanity from much repetitive physical drudgery; I now want AI to free humanity from repetitive mental drudgery, such as driving in traffic.
Excelsior, Mr. Ng!
5. Distill: An Interactive, Visual Journal for Machine Learning Research
Distill officially launches, under the vision and custodianship of founding editors Chris Olah and Shan Carter from Google Brain. Writes Michael Nielsen:
Distill is taking the web seriously. A Distill article (at least in its ideal, aspirational form) isn’t just a paper. It’s an interactive medium that lets users – “readers” is no longer sufficient – work directly with machine learning models.
Ideally, such articles will integrate explanation, code, data, and interactive visualizations into a single environment. In such an environment, users can explore in ways impossible with traditional static media. They can change models, try out different hypotheses, and immediately see what happens. That will let them rapidly build their understanding in ways impossible in traditional static media.
This is definitely a key resources to be keeping an eye on moving ahead. Best of luck to those involved.

Related:
- Top /r/MachineLearning Posts, February: Oxford Deep NLP Course; Data Visualization for Scikit-learn Results
- Top /r/MachineLearning Posts, January: TensorFlow Updates; AlphaGo in the Wild; Self-Driving Mario Kart
- Top /r/MachineLearning Posts, December: OpenAI Universe; Deep Learning MOOC For Coders; Musk: Tesla Gets Awesome-er