Must-Know: Why it may be better to have fewer predictors in Machine Learning models?
There are a few reasons why it might be a better idea to have fewer predictor variables rather than having many of them. Read on to find out more.
Editor's note: This post was originally included as an answer to a question posed in our 17 More Must-Know Data Science Interview Questions and Answers series earlier this year. The answer was thorough enough that it was deemed to deserve its own dedicated post.
Here are a few reasons why it might be a better idea to have fewer predictor variables rather than having many of them:
Redundancy/Irrelevance:
If you are dealing with many predictor variables, then the chances are high that there are hidden relationships between some of them, leading to redundancy. Unless you identify and handle this redundancy (by selecting only the non-redundant predictor variables) in the early phase of data analysis, it can be a huge drag on your succeeding steps.
It is also likely that not all predictor variables are having a considerable impact on the dependent variable(s). You should make sure that the set of predictor variables you select to work on does not have any irrelevant ones – even if you know that data model will take care of them by giving them lower significance.
Note: Redundancy and Irrelevance are two different notions –a relevant feature can be redundant due to the presence of other relevant feature(s).
Overfitting:
Even when you have a large number of predictor variables with no relationships between any of them, it would still be preferred to work with fewer predictors. The data models with large number of predictors (also referred to as complex models) often suffer from the problem of overfitting, in which case the data model performs great on training data, but performs poorly on test data.
Productivity:
Let’s say you have a project where there are a large number of predictors and all of them are relevant (i.e. have measurable impact on the dependent variable). So, you would obviously want to work with all of them in order to have a data model with very high success rate. While this approach may sound very enticing, practical considerations (such of amount of data available, storage and compute resources, time taken for completion, etc.) make it nearly impossible.
Thus, even when you have a large number of relevant predictor variables, it is a good idea to work with fewer predictors (shortlisted through feature selection or developed through feature extraction). This is essentially similar to the Pareto principle, which states that for many events, roughly 80% of the effects come from 20% of the causes.
Focusing on those 20% most significant predictor variables will be of great help in building data models with considerable success rate in a reasonable time, without needing non-practical amount of data or other resources.
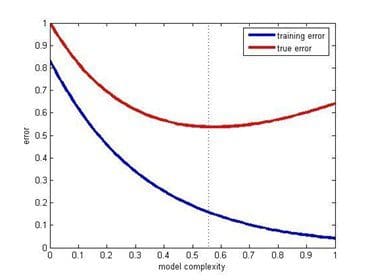
Training error & test error vs model complexity (Source: Posted on Quora by Sergul Aydore)
Understandability:
Models with fewer predictors are way easier to understand and explain. As the data science steps will be performed by humans and the results will be presented (and hopefully, used) by humans, it is important to consider the comprehensive ability of human brain. This is basically a trade-off – you are letting go of some potential benefits to your data model’s success rate, while simultaneously making your data model easier to understand and optimize.
This factor is particularly important if at the end of your project you need to present your results to someone, who is interested in not just high success rate, but also in understanding what is happening “under the hood”.
Related: