Data Science for Newbies: An Introductory Tutorial Series for Software Engineers
This post summarizes and links to the individual tutorials which make up this introductory look at data science for newbies, mainly focusing on the tools, with a practical bent, written by a software engineer from the perspective of a software engineering approach.
By Harris Brakmić, Software Engineer.
Editor's note: This is an overview of a multi-part tutorial on data science for newbies. The author has given the series a different -- tongue-in-cheek -- title; take it in stride and recognize that the series' approach and content is a fresh look at getting started with various aspects of data science from a software engineering perspective.
The PySpark console.
To do some serious statistics with Python one should use a proper distribution like the one provided by Continuum Analytics. Of course, a manual installation of all the needed packages (Pandas, NumPy, Matplotlib etc.) is possible but beware the complexities and convoluted package dependencies. In this article we’ll use the Anaconda Distribution. The installation under Windows is straightforward but avoid the usage of multiple Python installations (for example, Python3 and Python2 in parallel). It’s best to let Anaconda’s Python binary be your standard Python interpreter.
Part 2: Analyzing Reddit Comments & Querying Databases
Patterns are everywhere but many of them can’t be immediately recognized. This is one of the reasons why we’re digging deep holes in our databases, data warehouses, and other silos. In this article we’ll use a few more methods from Pandas’ DataFrames and generate plots. We’ll also create pivot tables and query an MS SQL database via ODBC. SqlAlchemy will be our helper in this case and we’ll see that even Losers like us can easily merge and filter SQL tables without touching the SQL syntax. No matter the task you always need a powerful tool-set in the first place. Like the Anaconda Distribution which we’ll be using here. Our data sources will be things like JSON files containing reddit comments or SQL-databases like Northwind. Many 90’es kids used Northwind to learn SQL.
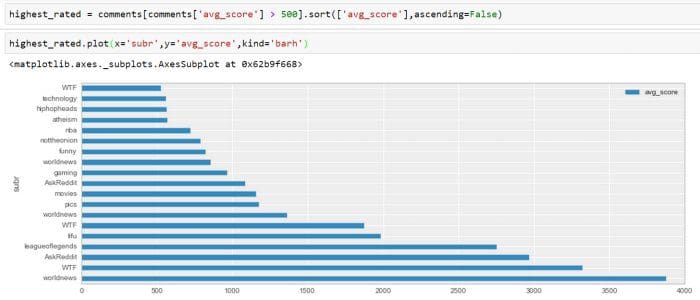
Highest rated comments for all available sub-reddits.
Part 2 Addendum: Playing SQL with DataFrames
So, let’s talk about a few features from Pandas I’ve forgot to mention in the last two articles.
By its own definition Spark is a fast, general engine for large-scale data processing. Well, someone would say: but we already have Hadoop, so why should we use Spark? Such a question I’d answer with a remark that Hadoop is EJB reinvented and that we need something more flexible, more general, more expandable and…much faster than MapReduce. Spark handles both batch and streaming processing at a very fast rate.
From my non-scientist perspective I’d define ML as a subset of the Artificial Intelligence research which develops self-learning (or self-improving?) algorithms that try to gain knowledge from data and make predictions based on it. However, ML is not only reserved for academia or some “enlightened circles”. We use ML every day without being aware of its existence and usefulness. A few examples of ML in the wild would be: spam filters, speech-recognition software, automatic text-analysis, “intelligent game characters”, or the upcoming self-driving cars. All these entities make decisions based on some ML algorithms.
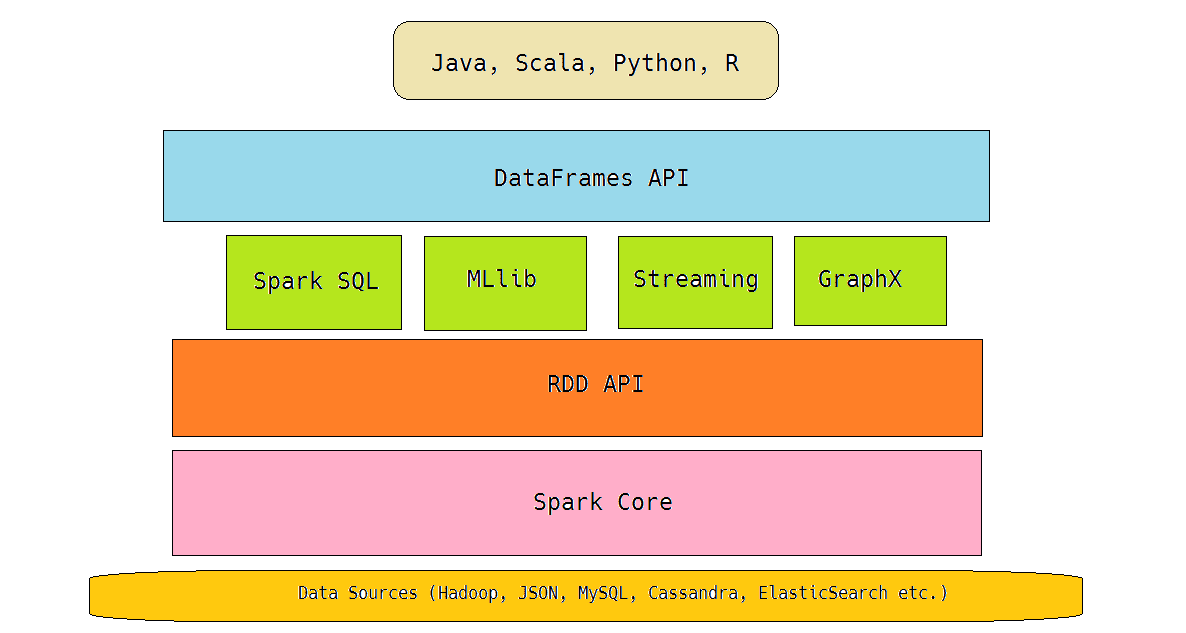
DataFrames in the Spark stack.
Before we start using DataFrames we first have to prepare our environment which will run in Jupyter (formerly known as “IPython”). After you’ve downloaded and unpacked the Spark Package you’ll find some important Python libraries and scripts inside the python/pyspark directory. These files are used, for example, when you start the PySpark REPL in the console. As you may know, Spark supports Java, Scala, Python and R. Python-based REPL called PySpark offers a nice option to control Spark via Python scripts
In this article we’ll explore Microsoft’s Azure Machine Learning environment and how to combine Cloud technologies with Python and Jupyter. As you may know I’ve been extensively using them throughout this article series so I have a strong opinion on how a Data Science-friendly environment should look like. Of course, there’s nothing against other coding environments or languages, for example R, so your opinion may greatly differ from mine and this is fine. Also AzureML offers a very good R-support! So, feel free to adapt everything from this article to your needs. And before we begin, a few words about how I came to the idea to write about Azure and Data Science.
While finishing my Data Science and ML Essentials course, I discovered that Azure ML has a built-in support for Jupyter and Python which, of course, made it very interesting to me because it makes Azure ML an ideal ground for experimentation. They even call one of their working areas “Experiments” so one can expect good Python (and R) support and many cool off-the-shelf modules. Being no different than other tech-enthusiasts I quickly decided to write an article describing some of the key parts of Azure ML.
Bio: Harris Brakmić (@brakmic) is a Software Developer at Advarics GmbH. He writes WebApps with Ractive, React, Backbone & DevExtreme, and Azure-based backends with C#.
Related: