 Using Deep Learning To Extract Knowledge From Job Descriptions
Using Deep Learning To Extract Knowledge From Job Descriptions
 Using Deep Learning To Extract Knowledge From Job Descriptions
Using Deep Learning To Extract Knowledge From Job DescriptionsWe present a deep learning approach to extract knowledge from a large amount of data from the recruitment space. A learning to rank approach is followed to train a convolutional neural network to generate job title and job description embeddings.
By Jan Luts, Senior Data Scientist at The Search Party.
At Search Party we are in the business of creating intelligent recruitment software. One of the problems we deal with is matching candidates and vacancies in order to create a recommendation engine. This usually requires parsing, interpreting and normalising messy, semi-/unstructured, textual data from résumés and vacancies, which is where the following come in: conditional random fields, bag-of-words, TF-IDFs, WordNet, statistical analysis, but also a lot of manual work done by linguists and domain experts for the creation of synonym lists, skill taxonomies, job title hierarchies, knowledge bases or ontologies.
While these concepts are valuable for the problem we try to solve, they also require a certain amount of manual feature engineering and human expertise. This expertise is certainly a factor that makes these techniques valuable, but the question remains whether more automated approaches can be used to extract knowledge about the job space to complement these more traditional approaches.
Here, our goal was to explore the use of deep learning methodology to extract knowledge from recruitment data, thereby leveraging a large amount of job vacancies. The data set included 10 million vacancies originating from the UK, Australia, New Zealand and Canada, covering the period 2014-2016. The total number of words in the data was 3 billion. This data set was split in a set for training (8.5 million) and a set for testing (1.5 million). For each vacancy we had the job description and the corresponding job title. We found that the job titles were usually reliable, but there was definitely a certain amount of noise in the data. The 10 million vacancies had 89,098 different job titles. Minimal preprocessing of the data was done: we tokenized the raw text of the job descriptions in words and all words were transformed to lowercase. No feature engineering was done.
Our model architecture consists of a convolutional neural network (CNN) that generates an embedding for a job description and a lookup table with job title embeddings:
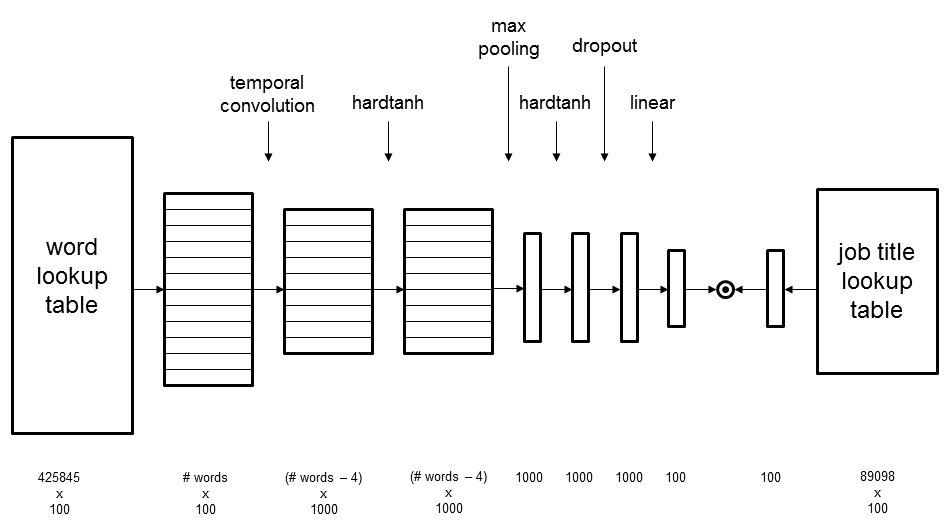
The cosine similarity between the job title embedding and the job description embedding was used as a scoring function. We followed a learning to rank approach using the pairwise hinge loss to train this model. The word lookup table contained 100-dimensional embeddings for the 425,845 most frequent words. The job title lookup table consisted of 89,098 100-dimensional job title embeddings. For the convolution layer we set the number of filters to 1,000, the kernel width to 5 and the stride to 1. This model has 52,095,400 parameters and word embeddings were initialized using rescaled Word2Vec coefficients, obtained from running it on our training data. Optimisation was done using stochastic gradient descent and dropout was used for regularisation purposes. The implementation was done using Torch 7.
Predicting Job Titles
The obvious first results to look at are what the model was trained to do: predicting a job title for a job description. This is a job description for an infrastructure engineer that was not part of the training set:
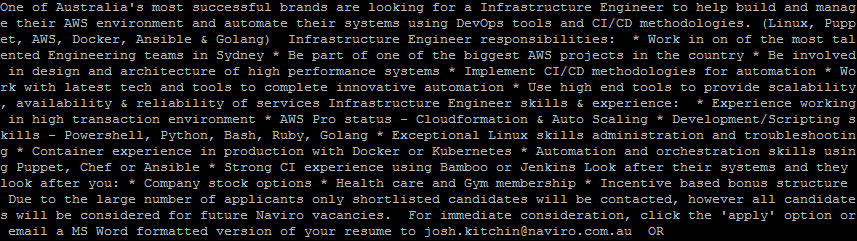
The job title is included in this job description and is in fact mentioned three times. There are also a lot of detailed duties and skills included for the position. An alternative job description was created by replacing the job title “infrastructure engineer” with “person” and removing the two other references.
Now we run the job title prediction model on both job descriptions and compare the resulting embeddings with the learned job title embeddings from the model using the cosine similarity. These are the 10 most likely job titles under both scenarios:
| Original job description | Without “infrastructure engineer” | |
| 1 | infrastructure engineer | linux engineer |
| 2 | linux engineer | devops engineer |
| 3 | systems engineer | linux systems engineer |
| 4 | windows engineer | systems engineer |
| 5 | devops engineer | systems administrator |
| 6 | automation engineer | devops |
| 7 | linux infrastructure engineer | senior devops engineer |
| 8 | automation engineer devops | linux systems administrator |
| 9 | devops infrastructure engineer | devops consultant |
| 10 | linux systems engineer | build automation engineer |
For the original vacancy the best matching job title was “infrastructure engineer”, which happens to be the correct one. However, most other job titles in the top 10 make sense, although the “windows engineer” is a bit of an outlier. For the modified job description, the best matching job title is “linux engineer”. It looks like the other 9 job titles would also be acceptable for this scenario.
This example shows that the model was able to extract the job title, but it also came up with a meaningful prediction when we removed the actual job title from the job description. This suggests that the model was using duties, skills and other types of information in the description to come up with a prediction when the more direct information was missing.
While the model was trained on job description data, we wanted to test it on data that is structured differently: simple queries that do not include the actual job title. This table shows some of the job titles that it came up with for various input:
| Input | Predicted job title |
| operative for groundworks | groundworker |
| babysitting St Martins Primary School | babysitter |
| we are Pemberton Truck Co and we are hiring regional drivers and a | truck driver |
| taking orders, extensive product knowledge, communication skills, dining skills | wait staff |
| our family is looking for someone to take care of our youngest child and a | nanny |
| we are urgently looking for a developer with a c++ background with a | c++ developer |
| Isuzu Technician (AK4679) | auto technician |
| we are looking for someone to manage a team of five software developers and a | software development manager |
| we are looking for someone to manage a team of five accountants and a | finance manager |
| we are looking for someone to manage a team of five sales representatives and a | sales manager |
These examples suggest that the model (to some extent) captures information about what someone with a particular job title usually does. For example, it predicts that someone who manages a team of accountants is probably a finance manager. By simply replacing “accountants” with “software developers” or “sales representatives” we jump to “software development manager” and “sales manager”, respectively. The model learned that a person who takes care of a child is often a nanny. When a truck company is looking for drivers, it is probably looking for truck drivers. Given the fact that “Isuzu technician” was not part of the job titles in our training data set, the prediction “auto technician” makes sense.
Finding Related Job Titles, Analogies and Relationships
A by-product of the model architecture is that embedding vectors are obtained for all job titles in our training set. In order to get a feeling for the quality of these job title embeddings, we had a look at the closest neighbours for a particular job title in the embedding space:
| statistician | humanties teacher | talent acquisition manager |
| statistical analyst | humanities teacher | talent acquisition specialist |
| senior statistician | qualified humanities teacher | talent manager |
| biostatistician | religious studies teacher | talent acquisition partner |
| epidemiologist | qts nqt geography teacher | talent aquisition manager |
| research statistician | geography teacher secondary | talent acquisition consultant |
| statistical programmer | teacher of humanities | head of talent acquisition |
| data scientist | qualified history teacher | recruitment manager |
These examples show that we found different variations of job titles (e.g. “statistician” versus ”statistical analyst” and ”talent acquisition manager” versus ”recruitment manager”), related (sub)fields (e.g. biostatistics and epidemiology for statistics), but also spelling errors (e.g. ”humanties teacher”). Even though our approach does not take the actual characters in words into account, it seems that the model in combination with a large amount of data is (to some extent) tolerant to spelling errors.
Something different now. Researchers have already shown that a simple vector offset approach based on the cosine distance can be very effective for finding analogies using word embeddings. There is the well-known example: cos(w(“king”) – w(“man”) + w(“woman”), w(“queen”)). We took the trained word and job title embeddings from our model and found that such relations hold for our approach too:
| Example | Predicted closest neighbour |
| java developer – java + c++ | c++ developer |
| marketing assistant – junior + senior | senior marketing executive |
| nurse – nursing + programming | software engineer |
| nanny – baby + database | database administrator |
| forklift driver – forklift + hadoop | big data architect |
| mobile phone technician – samsung + ford | mechanical and electrical trim technician |
| vehicle sales executive – ford + insurance | insurance sales executive |
| marketing manager – marketing assistant + junior software developer | software development manager |
| bank staff – nab + hospital | staff nurse |
| bank staff – nab + coles | grocery clerk |
| bank staff – nab + woolworths | supermarket retail assistant |
What are the Feature Detectors Looking for?
The filters in the convolutional layer of the model correspond to feature detectors that are trained to be active when a particular pattern is observed. Since the convolutional layer in our model operates on word embeddings, we can easily interpret what these feature detectors are looking for. One straightforward way of doing this is by visualizing the specific input sequences that lead to maximal activation. The following tables show the top 5 input patterns from all job descriptions of the test data set for several filters.
No surprise, some of the feature detectors are looking for job titles. After all, that’s what we optimized for:
| Teacher | Hospitality staff |
| senior lecturer lecturer senior lecturer | head barista sous chef foh |
| teacher teaching citizenship humanities | ideal hospitality assistant manager will |
| teacher secondary teacher college lecturer | title hospitality assistant apprentice employer |
| description sen teaching assistant sen | page hotel assistant manager m |
| senior lecturer clinical psychology lecturer | head waiter chefs de rang |
Other feature detectors are looking for particular duties:
| Cleaning | Office administration |
| ironing cleaning taking children to | bookings provide typing filing photocopying |
| toilets cleaning oven rubbish bins | filing general typing answering phones |
| janitor janitorial worker maintenance janitor | greeting clients typing filing sending |
| toilets cleaning guest bedrooms landings | earner with typing handling calls |
| ironing cleaning bathrooms cleaning toilets | typing copy typing answering switchboard |
Yet other feature detectors focus on leadership:
| Leader | Supervisor |
| have people leadership experience senior | oversee and supervise welders boilermakers |
| mentoring team lead experience senior | supervise homework supervise bathtime |
| supervise and lead the floor | motivate and supervise staff valid |
| have proven leadership of teams | manage and supervise junior fee |
| supervise and lead the team | motivate and supervise team members |
Type of employment and salary:
| Casual | Salary |
| casual bar porter casual role | hour pro rata weekend hourly |
| casual casual operator needed asap | hour pro rata various hours |
| casual bar attendant write your | hour pro rata to term |
| casual casual cleaner required good | hour pro rata term part |
| casual bar attendant worktype casual | hourly rate overtime available saturdays |
Location and language skills:
| Australia | German |
| sydney cbd nsw sydney cbd | fluent in german consultative professional |
| sydney melbourne brisbane perth canberra | a motivated german specialist teacher |
| sydney australia australia sydney nsw | specified location german resourcer entry |
| sydney adelaide brisbane chatswood melbourne | translation skills german :english . |
| sydney adelaide brisbane chatswood melbourne | job description german resourcer entry |
Interestingly, there was also a feature detector for the desired appearance of candidates. Having good manners, a certain standard of personal hygiene and an English accent seem to go hand in hand according to this feature detector:
| Appearance |
| caucasian languages : english hair |
| caucasian languages : english accents |
| disposition smart clean appearance friendly |
| groomed and presentable appearance caring |
| presentable with a polite courteous |
These examples illustrate that the obtained filters not only focus on the job title, but cover most of the relevant sections that one expects to find in a job description. While CNNs are of course known for representation and feature learning, we still found it quite remarkable what it came up with after learning to predict job titles from raw, uncleaned job descriptions with almost no preprocessing.
Keyphrases and Related Job Descriptions
Let’s have another look at the pieces of input text that tend to maximally activate the feature detectors in the CNN. Although this ignores the transfer functions and fully connected layer in the network, it is a helpful way to understand the predictions that the CNN makes. The figure below highlights the parts of a tandoori chef job description that correspond to the description’s 50 text windows with the largest activation over all filters in the network. By assigning a simple colour code (in increasing order of activation: grey, yellow, orange, red) to each word, it becomes clear that these text windows correspond to the keyphrases in this job description that was taken from the test data set:

Note that the first 20 words of the vacancy were not used since they usually contain the job title (it is often the title of the vacancy).
A final insight is that the CNN part of the model is basically a document to vector approach that generates an embedding for a variable-length job description. Hence, there is nothing stopping us from looking for similar job descriptions by comparing their embeddings. This is the closest test set vacancy in the embedding space for the tandoori chef vacancy above:

No surprises: this employer is also looking for a tandoori chef. Also not very surprising: looking at which neurons show high activations reveals that these vacancies basically share the same active neurons. For example, neuron 725 gets activated for both “culinary skills, knowledge about food” and “restaurant in Prahan. Friendly” and neuron 444 for “all marinades and Indian dishes” and “a Tandoori chef to work”. So, the model knows that these expressions are semantically related. Based on some experiments we did, it looks like this could be an interesting approach to find similar or related vacancies. Given that the model does not only look at the job title and knows which expressions are related, this adds value compared to a simple approach that only compares the actual words of a job title or job description.
This article is a condensed overview of a blog series that was published here.
Bio: Jan Luts is a senior data scientist at Search Party. He received a Master of Information Sciences from Universiteit Hasselt, Belgium, in 2003. He also received Master degrees in Bioinformatics and Statistics from Katholieke Universiteit Leuven, Belgium, in 2004 and 2005, respectively. After obtaining his PhD at the Department of Electrical Engineering (ESAT) of Katholieke Universiteit Leuven in 2010, he worked in postdoctoral research for a further two years at the institution. In 2012 Jan moved to Australia where he worked as a postdoctoral researcher in Statistics at the School of Mathematical Sciences in the University of Technology, Sydney. In 2013 he moved into the private sector as data scientist at Search Party.
Related: