The Machine Learning Abstracts: Classification
Classification is the process of categorizing or “classifying” some items into a predefined set of categories or “classes”. It is exactly the same even when a machine does so. Let’s dive a little deeper.
By Narendra Nath Joshi, Carnegie Mellon.
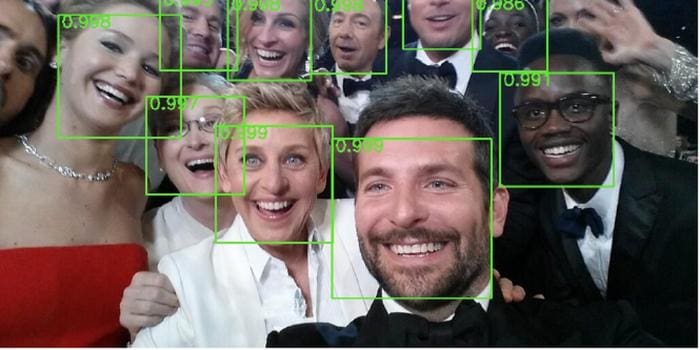
Ever applied for a credit card and been approved in seconds?
Ever read about fraud detection in banks?
Ever wondered how your email filters spam?
Ever curious about how cameras detect faces?
It’s all classification
Classification is the process of categorizing or “classifying” some items into a predefined set of categories or “classes”.
It is exactly the same even when a machine does so.
Let’s dive a little deeper.
How?
How do humans perform classification tasks? Let’s say you want to get rid of some old stuff you have lying around in your house. You look at each item and determine whether you want to dispose off the item or not.
You are “classifying” each item into two “classes”: “throw” and “keep”.
Let’s try to understand what all you will consider for each item to determine if you will throw it away or not. Some examples might be:
- Do you need it in the future?
- Is it expensive?
- Can it be given to someone else as a hand-me-down?
- Does it hold sentimental value?
These things which you consider are “features”.
What About Computers?
Computers also behave the same way. A typical classification algorithm would use these features to determine how to classify a particular item.
Formally defined, each item is called “input vector”. The decision to keep or throw each item is called “label” for that item. You need to provide some examples to the classification algorithm to “learn” which items to throw and which item to keep. This form of learning is called “supervised learning” because we supervise the learning done by the algorithm by providing the labels. In future posts, I will talk about various kinds of machine learning algorithms (supervised learning, unsupervised learning, semi-supervised learning and reinforcement learning) in detail.
Show Me An Example, how bout dah!
Let us consider this Spring cleaning example itself. Let’s say you have 10 items to decide on whether to keep or throw.
You use 7 items to “train” your classification algorithm. Training is the process of making an algorithm “learn”.
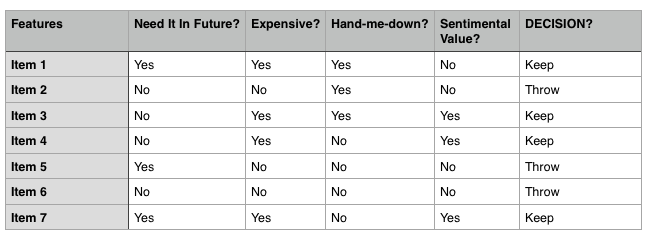
My “Training Set”
Upon careful inspection, we can infer and confirm that we keep an item only if it is of sentimental value or it is both needed in the future and expensive.
KEEP = SENTIMENTAL_VALUE | (NEED_FUTURE & EXPENSIVE)
After training, a classification algorithm will learn exactly the same and try to apply what it has learned to the next item which it has not seen yet. For example, item 8.

Item 8
By the learning the algorithm has done, it will classify Item 8 as Keep.
I hope this gives you a rough idea of the intuition behind classification. In the next post, I will talk about the different types of classification algorithms.
Spoiler Alert:
- Decision Trees
- Neural Networks
- Support Vector Machines
Bio: Narendra Nath Joshi is a graduate student in AI and Machine Learning at Carnegie Mellon University, currently pursuing a research intern at Disney Research Pittsburgh. Has a keen interest in natural language, computer vision, and deep learning.
Original. Reposted with permission.
Related: