 Which Machine Learning Algorithm Should I Use?
Which Machine Learning Algorithm Should I Use?
 Which Machine Learning Algorithm Should I Use?
Which Machine Learning Algorithm Should I Use?A typical question asked by a beginner, when facing a wide variety of machine learning algorithms, is "which algorithm should I use?” The answer to the question varies depending on many factors, including the size, quality, and nature of data, the available computational time, and more.
By Hui Li, Principal Staff Scientist at SAS.
This resource is designed primarily for beginner to intermediate data scientists or analysts who are interested in identifying and applying machine learning algorithms to address the problems of their interest.
A typical question asked by a beginner, when facing a wide variety of machine learning algorithms, is “which algorithm should I use?” The answer to the question varies depending on many factors, including:
- The size, quality, and nature of data.
- The available computational time.
- The urgency of the task.
- What you want to do with the data.
Even an experienced data scientist cannot tell which algorithm will perform the best before trying different algorithms. We are not advocating a one and done approach, but we do hope to provide some guidance on which algorithms to try first depending on some clear factors.
The machine learning algorithm cheat sheet
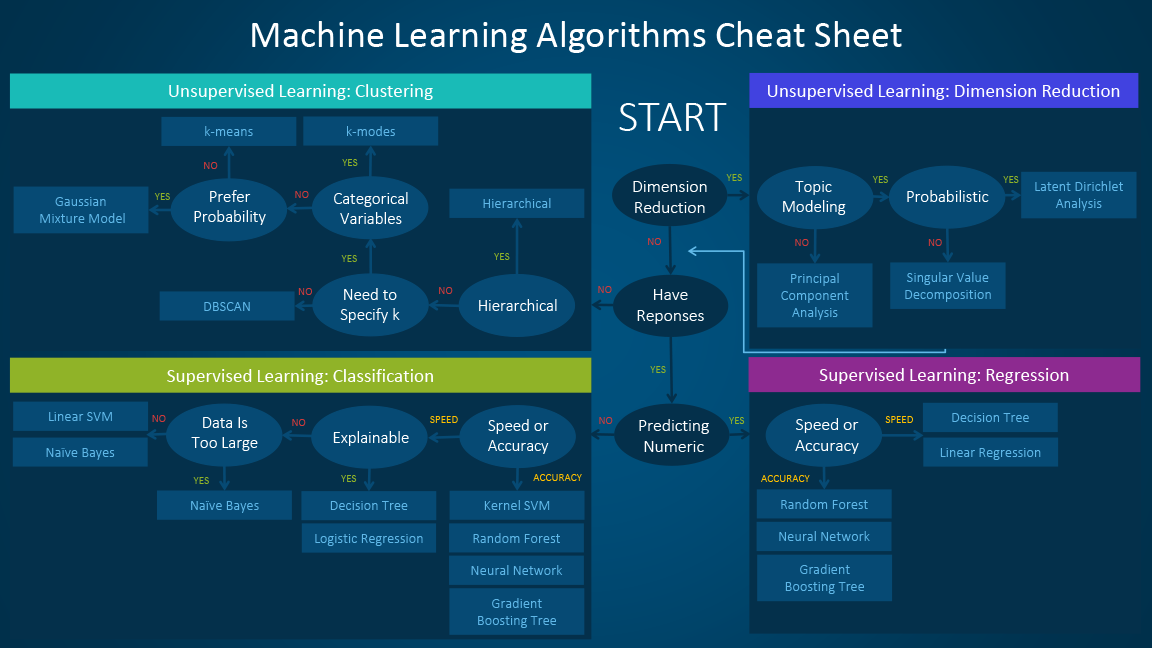
The machine learning algorithm cheat sheet helps you to choose from a variety of machine learning algorithms to find the appropriate algorithm for your specific problems. This article walks you through the process of how to use the sheet.
Since the cheat sheet is designed for beginner data scientists and analysts, we will make some simplified assumptions when talking about the algorithms.
The algorithms recommended here result from compiled feedback and tips from several data scientists and machine learning experts and developers. There are several issues on which we have not reached an agreement and for these issues we try to highlight the commonality and reconcile the difference.
Additional algorithms will be added in later as our library grows to encompass a more complete set of available methods.
How to use the cheat sheet
Read the path and algorithm labels on the chart as "If <path label> then use <algorithm>." For example:
- If you want to perform dimension reduction then use principal component analysis.
- If you need a numeric prediction quickly, use decision trees or logistic regression.
- If you need a hierarchical result, use hierarchical clustering.
Sometimes more than one branch will apply, and other times none of them will be a perfect match. It’s important to remember these paths are intended to be rule-of-thumb recommendations, so some of the recommendations are not exact. Several data scientists I talked with said that the only sure way to find the very best algorithm is to try all of them.
Types of machine learning algorithms
This section provides an overview of the most popular types of machine learning. If you’re familiar with these categories and want to move on to discussing specific algorithms, you can skip this section and go to “When to use specific algorithms” below.
Supervised learning
Supervised learning algorithms make predictions based on a set of examples. For example, historical sales can be used to estimate the future prices. With supervised learning, you have an input variable that consists of labeled training data and a desired output variable. You use an algorithm to analyze the training data to learn the function that maps the input to the output. This inferred function maps new, unknown examples by generalizing from the training data to anticipate results in unseen situations.
- Classification: When the data are being used to predict a categorical variable, supervised learning is also called classification. This is the case when assigning a label or indicator, either dog or cat to an image. When there are only two labels, this is called binary classification. When there are more than two categories, the problems are called multi-class classification.
- Regression: When predicting continuous values, the problems become a regression problem.
- Forecasting: This is the process of making predictions about the future based on the past and present data. It is most commonly used to analyze trends. A common example might be estimation of the next year sales based on the sales of the current year and previous years.
Semi-supervised learning
The challenge with supervised learning is that labeling data can be expensive and time consuming. If labels are limited, you can use unlabeled examples to enhance supervised learning. Because the machine is not fully supervised in this case, we say the machine is semi-supervised. With semi-supervised learning, you use unlabeled examples with a small amount of labeled data to improve the learning accuracy.
Unsupervised learning
When performing unsupervised learning, the machine is presented with totally unlabeled data. It is asked to discover the intrinsic patterns that underlies the data, such as a clustering structure, a low-dimensional manifold, or a sparse tree and graph.
- Clustering: Grouping a set of data examples so that examples in one group (or one cluster) are more similar (according to some criteria) than those in other groups. This is often used to segment the whole dataset into several groups. Analysis can be performed in each group to help users to find intrinsic patterns.
- Dimension reduction: Reducing the number of variables under consideration. In many applications, the raw data have very high dimensional features and some features are redundant or irrelevant to the task. Reducing the dimensionality helps to find the true, latent relationship.
Reinforcement learning
Reinforcement learning analyzes and optimizes the behavior of an agent based on the feedback from the environment. Machines try different scenarios to discover which actions yield the greatest reward, rather than being told which actions to take. Trial-and-error and delayed reward distinguishes reinforcement learning from other techniques.
Considerations when choosing an algorithm
When choosing an algorithm, always take these aspects into account: accuracy, training time and ease of use. Many users put the accuracy first, while beginners tend to focus on algorithms they know best.
When presented with a dataset, the first thing to consider is how to obtain results, no matter what those results might look like. Beginners tend to choose algorithms that are easy to implement and can obtain results quickly. This works fine, as long as it is just the first step in the process. Once you obtain some results and become familiar with the data, you may spend more time using more sophisticated algorithms to strengthen your understanding of the data, hence further improving the results.
Even in this stage, the best algorithms might not be the methods that have achieved the highest reported accuracy, as an algorithm usually requires careful tuning and extensive training to obtain its best achievable performance.
When to use specific algorithms
Looking more closely at individual algorithms can help you understand what they provide and how they are used. These descriptions provide more details and give additional tips for when to use specific algorithms, in alignment with the cheat sheet.
For a full treatment of algorithms and considerations for their use, see the full post on the SAS website.
Bio: Hui Li is a Principal Staff Scientist of Data Science Technologies at SAS. Her current work focuses on Deep Learning, Cognitive Computing and SAS recommendation systems in SAS Viya. She received her PhD degree and Master’s degree in Electrical and Computer Engineering from Duke University. Before joining SAS, she worked at Duke University as a research scientist and at Signal Innovation Group, Inc. as a research engineer. Her research interests include machine learning for big, heterogeneous data, collaborative filtering recommendations, Bayesian statistical modeling and reinforcement learning.
Original. Reposted with permission.
Related: