 Machine Learning Workflows in Python from Scratch Part 1: Data Preparation
Machine Learning Workflows in Python from Scratch Part 1: Data Preparation
 Machine Learning Workflows in Python from Scratch Part 1: Data Preparation
Machine Learning Workflows in Python from Scratch Part 1: Data PreparationThis post is the first in a series of tutorials for implementing machine learning workflows in Python from scratch, covering the coding of algorithms and related tools from the ground up. The end result will be a handcrafted ML toolkit. This post starts things off with data preparation.
It seems that, anymore, the perception of machine learning is often reduced to passing a series of arguments to a growing number of libraries and APIs, hoping for magic, and awaiting the results. Maybe you have a very good idea of what's going on under the hood in these libraries -- from data preparation to model building to results interpretation and visualization and beyond -- but you are still relying on these various tools to get the job done.

Machine learning workflows in Python. From scratch.
And that's fine. Using well-tested and proven implementations of tools for performing regular tasks makes sense for a whole host of reasons. Reinventing wheels which don't roll efficiently is not best practice... it's limiting, and it takes an unnecessarily long time. Whether you are using open source or proprietary tools to get your work done, these implementations have been honed by teams of individuals ensuring that you get your hands on the best quality instruments with which to accomplish your goals.
However, there is often value in doing the dirty work yourself, even if as an educational endeavor. I wouldn't suggest coding your own distributed deep learning training framework from scratch -- at least, not normally -- but having gone through the trials and tribulations of writing up your own algorithm implementations and supporting tools from scratch at least once is a great idea. I could be wrong, but I don't think the vast majority of people learning machine learning, data science, artificial intelligence, or << insert related buzzword here >> today are actually doing this.
So let's build some machine learning workflows in Python. From scratch.
What Do We Mean by "From Scratch?"
First, let's clarify: when I say "from scratch," I mean using as few helping hands as possible. It's all relative, but for our purposes I will draw the line this side of writing our own matrix, dataframe, and/or graphing libraries, and as such we will lean on numpy, pandas, and matplotlib, respectively. We won't even use all of the available functionality of these libraries in some cases, as we will see shortly, bypassing them in the name of better understanding. Anything in the standard Python library is also fair game. Beyond that, however, we're on our own.
We will need to start somewhere, and so this post will begin by looking at some simple data preparation tasks. We're going to start slowly, but ramp up quickly over the next few posts after we get a feel for what it is we're doing. Beyond data preparation, we will also need additional data transformation, results interpretation, and visualization tools -- not to mention machine learning algorithms -- to complete our journey, all of which we will get to.
The idea is to manually cobble together whatever non-trivial functionality we need to accomplish our machine learning tasks. As the series unfolds, we can add new tools and algorithms, as well as rethink some of our previous assumptions, making the entire process as much iterative as it will be progressive. Step by step, we will focus on what our goals are, strategize on how to accomplish them, implement them in Python, and then test them to see if they work.
The end result, as it is presently envisioned, will be a set of simple Python modules organized into our own simple machine learning library. For the uninitiated, I believe this will be invaluable experience toward understanding how machine learning processes, workflows, and algorithms work.
What Do We Mean by Workflow?
Workflow can mean different things to different people, but we are generally talking about the entire process considered to be part of a machine learning project. There are numerous process frameworks which can help us keep track of what it is we are doing, but let's simplify things for now to include the following:
- Get some data
- Process and/or prepare the data
- Build a model
- Interpret the results
We can expand on these as we go, but this is our simple machine learning process framework for now. Also, "pipeline" implies the ability to chain workflow functionality together, and so we will also keep this in mind moving forward.
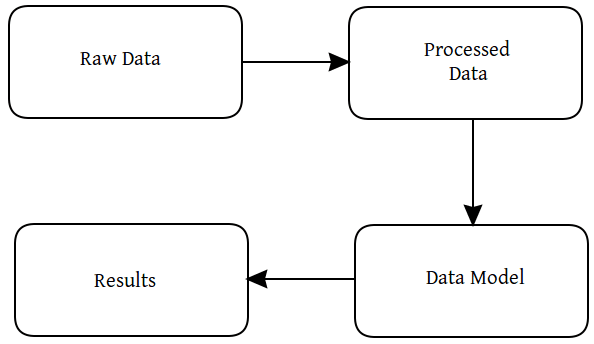
Very simple machine learning process framework.
Getting Our Data
Before we get to building any models, we need some data, and need to make sure this data conforms to some reasonable expectations. For testing purposes (not in the sense of training/testing, but testing our infrastructure), we will use the iris dataset, which you can download here. Given that various versions of the dataset can be found online, I suggest we all start from the same raw data in order to ensure all of our preparation steps work.
Let's take a look:
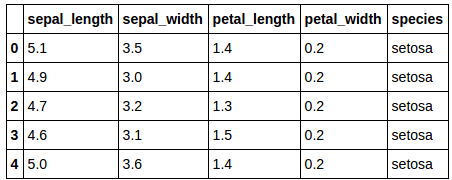
Given what we know about such a simple dataset and its file, let's first think about what it is we will need to do to go from raw data to results:
- Data is stored in CSV file
- Instances are made up mostly of numeric attribute values
- Class is categorical text
Now, none of what is above is universally applicable to all datasets, but neither is any of it specific to this dataset. This affords us the opportunity to write code we can hopefully later re-use. Good coding practices we will focus on herein will include both reusability and modularity.
Some simple exploratory data analysis is shown below.
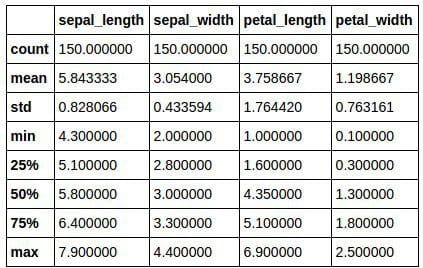
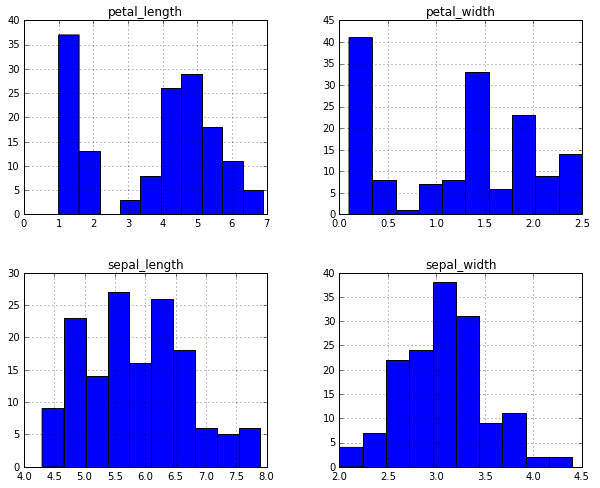
Very simple exploratory data analysis of the iris dataset: description of the dataset (above), and default attribute distribution histograms (below).
Preparing Our Data
While the data preparation we need in this particular scenario is minimal, there is still some needed. Specifically, we need to ensure that we account for the header row, remove any indexing that pandas automatically performs, and convert our class values from nominal to numeric. Since we have no nominal values in the features we will use for modeling, there will be no more complex transformations required -- at least, not yet.
Ultimately, we need a better data representation for our algorithm as well, and so we will make sure we end up with a matrix -- or numpy ndarray -- before we move on. Our data preparation workflow, then, should take the following form:
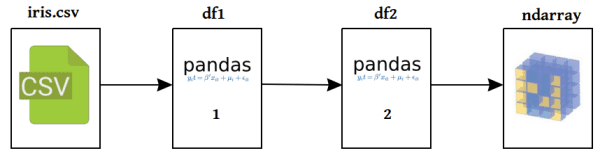
Very simple data preparation process.
Also, note that there is no reason to believe that all interesting data is stored in comma separated files. We may want to grab data from a SQL database or directly from the web at some point, which we will come back to and visit in the future.
First, let's write a simple function to load a CSV file into DataFrame; sure, it's simple to do inline, but thinking ahead we may want to add some additional steps to our dataset loading function in the future. Trust me here.
This code is quite straightforward. Reading data files line by line easily allows for some additional pre-processing, such as ignoring non-data lines (we are assuming comments in data files begin with '#' at the moment, however ridiculous). We can specify whether or not the dataset file includes a header, and we also allow for both CSV and TSV files, with CSV being the default.
A bit of error checking exists, but it isn't terribly robust yet, so we may want to come back to this later. Also, reading a file line by line and making decisions on what to do with these lines one by one will be slower than using built-in functionality to read clean, conforming CSVs directly into a DataFrame, but the trade-off to allow for more flexibility is worth it at this stage (but may take considerably longer with larger files). Don't forget, if some of these inner workings don't seem like the best approach, we can always make changes later.
Before we try out our code, we need to first write a function to convert the nominal class values to numeric values. To generalize the function, we should allow it to be used on any attribute in the dataset, not only the class. We should also keep track of the mapping of attribute names to what will end up being integers. Given our previous step of loading CSV or TSV data files into pandas DataFrames, this function should accept both a pandas DataFrame as well as the attribute name to convert to numeric.
Also note that we are sidestepping a conversation about using one-hot encoding as relates to categorical non-class attributes, but I suspect we will return to that later.
The above function is, again, simple, but accomplishes what we want it to. We could have approached this task in a number of different ways, including using built-in functionality of pandas, but starting off by getting our hands a bit dirty is what this is all about.
At this point we can now load a dataset from file, and replace categorical attribute values with numeric values (we also keep a dictionary of those mappings for later). As previously mentioned, we want our dataset ultimately in the form of a numpy ndarray, in order to most easily use it with our algorithms. Again, a simple task, but making it a function will allow us to build on it in the future if necessary.
Even if any of the preceding functions did not look like overkill, this one probably does. But bear with me; we're actually following sound -- if overly cautious -- programming principles. There is a good chance as we move forward that we will come up with changes or additions to the functions we have built thus far. Being able to implement these changes in one place, and have these changes well-documented, makes sense in the long term.
Testing our Data Preparation Workflow
Out workflow thus far may still be in building block form, but let's give our code a test.
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5 3.6 1.4 0.2 setosa
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 0
1 4.9 3 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5 3.6 1.4 0.2 0
{'setosa': 0, 'versicolor': 1, 'virginica': 2}
[['5.1' '3.5' '1.4' '0.2' 0]
['4.9' '3' '1.4' '0.2' 0]
['4.7' '3.2' '1.3' '0.2' 0]
['4.6' '3.1' '1.5' '0.2' 0]
['5' '3.6' '1.4' '0.2' 0]
['5.4' '3.9' '1.7' '0.4' 0]
['4.6' '3.4' '1.4' '0.3' 0]
['5' '3.4' '1.5' '0.2' 0]
['4.4' '2.9' '1.4' '0.2' 0]
['4.9' '3.1' '1.5' '0.1' 0]]
With our code working as we hoped it would, let's do some quick house cleaning. We will come up with a more comprehensive organizational structure for our code once we get rolling, but for now we should add all of these functions to a single file, and save it as dataset.py. This will allow for more convenient reuse, which we will see next time.
Looking Ahead
Next, we will turn our attention to something of greater substance, an implementation of the k-means clustering algorithm. Then we will have a look at a simple classification algorithm, k-nearest neighbors. We will see how we can build both classification and clustering models in the context of our simple workflows. Undoubtedly, this will require coding some additional tools to help with out project, and I'm sure modifications will be needed to what we have done already.
But that's alright; practicing machine learning is the best prescription for understanding machine learning. Implementing the algorithms and support tools we need for our workflows should ultimately prove useful. I hope you have found this helpful enough to check the next installment.
Related: