ETL vs ELT: Which One is Right for Your Data Pipeline?
Learn about the differences between ETL and ELT data integration techniques and determine which is right for your data pipeline.

Image by Author
ETL and ELT are data integration pipelines that transfer data from multiple sources to a single centralized source and perform some transformation and processing steps to it. The difference between these two is ETL transforms the data before loading, and ELT transforms the data after loading.
But before diving deeply into them, let's first understand the meaning of E, L, and T.
E for Extract - Extracting the data from one or multiple sources.
T for Transform - Transforming the data is a process of cleaning and modifying the data in a format so that it can be used for business analysis.
L for Loading - It involves loading data to a target system, which may be a data warehouse or a database.
ETL (Extract, Transform, Load)
ETL is the first standardized data integration method that emerged in the 1970s due to the evolution of disk storage. As the name suggests, it first extracts the raw data from the source and then transforms it before loading it into the target database, i.e. (Extract ? Transform ? Load)
In ETL, the data ingestion process is slower, as we need to first transform the data on a separate server before loading it to the target database.
ETL is used when storing a small amount of data in finite storage. It is suitable for on-premises, structured, and relational data sets.
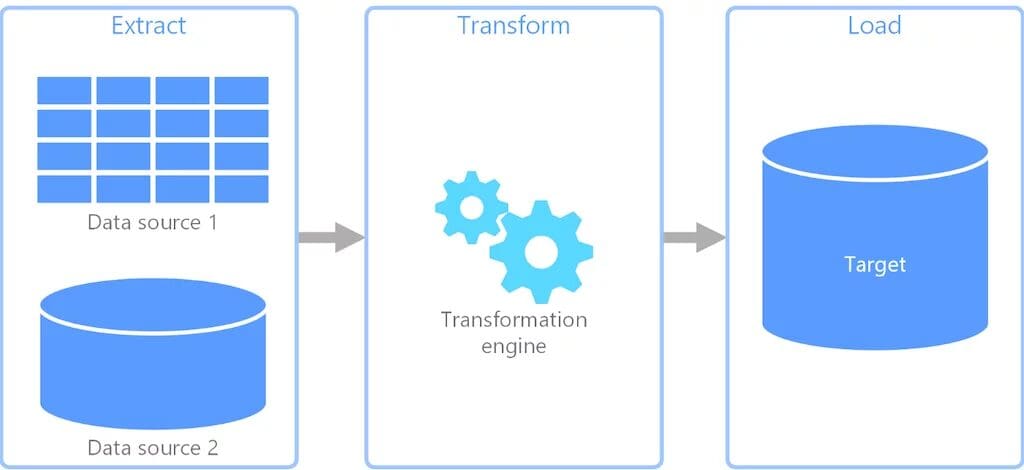
Fig. 1 ETL System Architecture | Image by estuary.dev
Now, let's understand some of its major pros and cons.
Pros
- Data Quality: ETL improves the data quality by processing the raw data from various sources and combining them in a structured format.
- Less Load on Disk Drives: The key feature of ETL is that the data is transformed in memory, which allows us to create such data pipelines where we have throughput-constrained disks.
- Consistency: Storing the processed data in the database ensures that the data is consistent, relevant and accurate, which caters to all the business needs and helps to make better decisions.
Cons
- Flexibility: ETL has a rigid pipeline. It doesn't allow modifications in the database. Suppose if the business plans change, then the business intelligence teams cannot have a chance to revert back to the original raw data and re-query it.
- Latency: The delay between data ingestion and data analysis is unsuitable for real-time applications.
- Data Loss: ETL pipelines can result in data loss if the data is not handled carefully or there are some errors in the transformation step.
ELT (Extract, Load, Transform)
In the early 2000s, cloud computing became more common, and the development of data lakes and warehouses created a revolution in data storage. Now businesses can access cheap and unlimited cloud storage for loading their data.
This leads to developing a new data integration pipeline, i.e. ELT (Extract, Load, Transform). The raw data can be stored inside the data warehouse and queried directly from it.
In simple terms, inside ELT, the raw data is extracted from the source and directly stored in the data warehouse without any transformations. Unlike in ETL, the transformation step is performed in a separate server before loading, which creates additional delays and rigidity in the system.
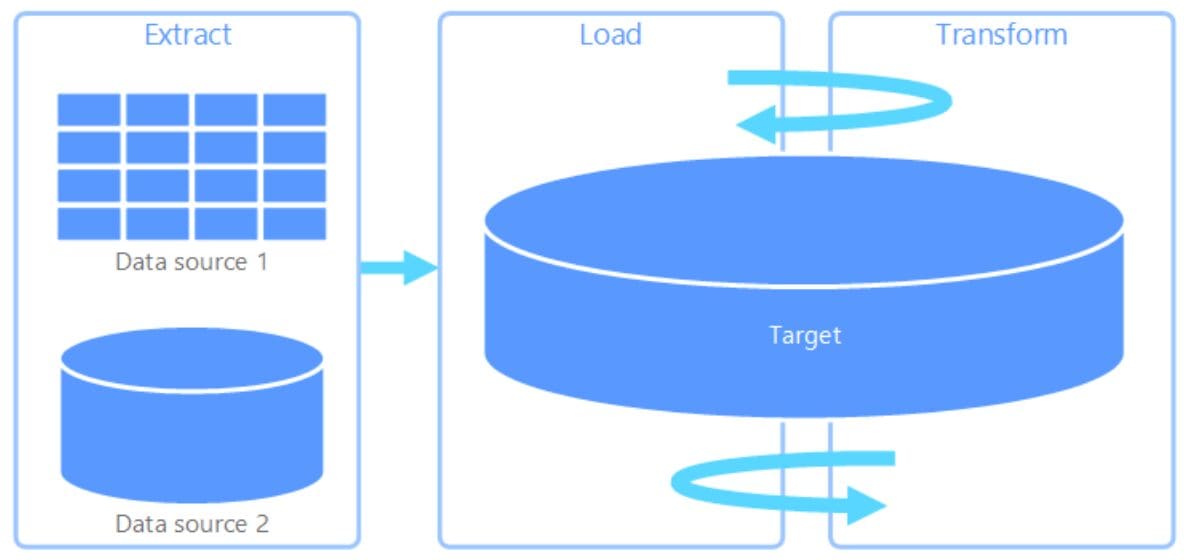
Fig. 2 ELT System Architecture | Image by sqlofthenorth
Now, let's understand some of its major pros and cons.
Pros
- Flexibility: ELT pipelines are more flexible, as they allow the re-querying of relevant data from the raw data if the business plan changes.
- Latency: As data loading and transformation can occur simultaneously, it is suitable for real-time decision-making.
- Cost-effective: ELT pipelines are more cost-effective, as the software required mostly relay on open-source, which is readily available.
Cons
- Data Quality: Data quality in the ELT pipeline may differ from that in ETL. The transformations are applied after the data is stored in the target database.
- Unstructured Data: It is challenging to write queries from unstructured data if they are not adequately managed. Also, the query results cannot be as accurate due to the inconsistency in the data structures.
- Security: Since all the raw data is stored in the database, so there may be a risk that sensitive data can be exposed or may be misused.
- Data Storage: It requires more storage space because the raw data is directly stored into it without any processing.
Difference Between ETL & ELT
ETL and ELT differ in two ways. In ETL, data is transformed before loading, and in ELT, the data is transformed after loading.
ETL has a rigid pipeline because it only supports legacy database architecture, but ELT is flexible and supports data re-querying.
ETL is comparatively slower than ELT, involving an additional data transformation step before loading. But in ELT, this transformation can be done simultaneously with loading.
ETL can only be used with in-premise or structured data. But ELT can be used with any structured, unstructured or semi-structured data.
Below is the table which gives a side-by-side comparison of ETL and ELT data pipelines.
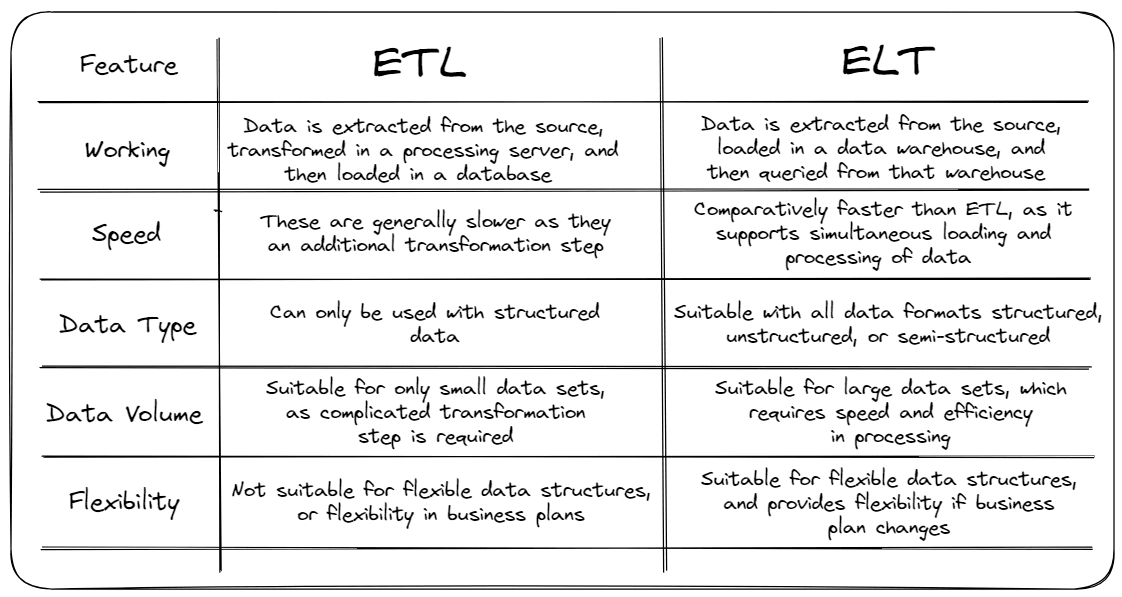
Fig. 3 Side-by-side comparison of ETL & ELT Pipelines | Image by Author
When to use What?
To harness the power of data in today's business, we need efficient and robust data pipelines which can extract, load and transform data from multiple sources to a single centralized storage so that it can be used for analysis. Here ETL and ELT data pipelines come into the picture. But choosing between ETL and ELT will depend entirely on the business’s needs.
Generally, an ETL pipeline can be used when we have strict consistency and data quality requirements before loading the data. Or when we have complex data integration and transformation steps to be performed.
While ELT can be used when we want to store huge amounts of data, and it requires quicker and more efficient processing. ELT also provides flexibility in the database depending on the changing business needs.
I hope you enjoyed reading this article. You can also contact me on Linkedin.
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.