 Machine Learning Exercises in Python: An Introductory Tutorial Series
Machine Learning Exercises in Python: An Introductory Tutorial Series
 Machine Learning Exercises in Python: An Introductory Tutorial Series
Machine Learning Exercises in Python: An Introductory Tutorial SeriesThis post presents a summary of a series of tutorials covering the exercises from Andrew Ng's machine learning class on Coursera. Instead of implementing the exercises in Octave, the author has opted to do so in Python, and provide commentary along the way.
By John Wittenauer, Data Scientist.
Editor's note: This tutorial series was started in September of 2014, with the 8 installments coming over the course of 2 years. I only mention this to put John's first paragraph into context, and to assure readers that this informative series of tutorials, including all of its code, is as relevant and up-to-date today as it was at the time it was written. This is great material, both for anyone taking Andrew Ng's MOOC and as a standalone resource.
One of the pivotal moments in my professional development this year came when I discovered Coursera. I'd heard of the "MOOC" phenomenon but had not had the time to dive in and take a class. Earlier this year I finally pulled the trigger and signed up for Andrew Ng's Machine Learning class. I completed the whole thing from start to finish, including all of the programming exercises. The experience opened my eyes to the power of this type of education platform, and I've been hooked ever since.
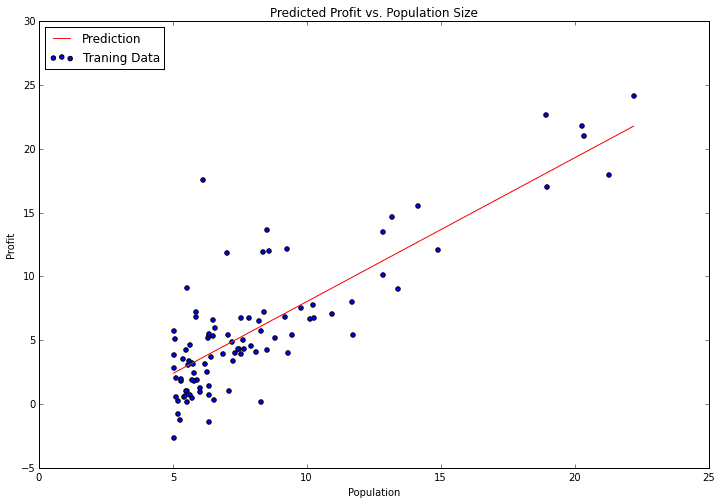
Part 1 - Simple Linear Regression
This blog post will be the first in a series covering the programming exercises from Andrew's class. One aspect of the course that I didn't particularly care for was the use of Octave for assignments. Although Octave/Matlab is a fine platform, most real-world "data science" is done in either R or Python (certainly there are other languages and tools being used, but these two are unquestionably at the top of the list). Since I'm trying to develop my Python skills, I decided to start working through the exercises from scratch in Python. The full source code is available at my IPython repo on Github. You'll also find the data used in these exercises and the original exercise PDFs in sub-folders off the root directory if you're interested.
Part 2 - Multivariate Linear Regression
In part 1 of my series on machine learning in Python, we covered the first part of exercise 1 in Andrew Ng's Machine Learning class. In this post we'll wrap up exercise 1 by completing part 2 of the exercise. If you recall, in part 1 we implemented linear regression to predict the profits of a new food truck based on the population of the city that the truck would be placed in. For part 2 we've got a new task - predict the price that a house will sell for. The difference this time around is we have more than one dependent variable. We're given both the size of the house in square feet, and the number of bedrooms in the house. Can we easily extend our previous code to handle multiple linear regression? Let's find out!
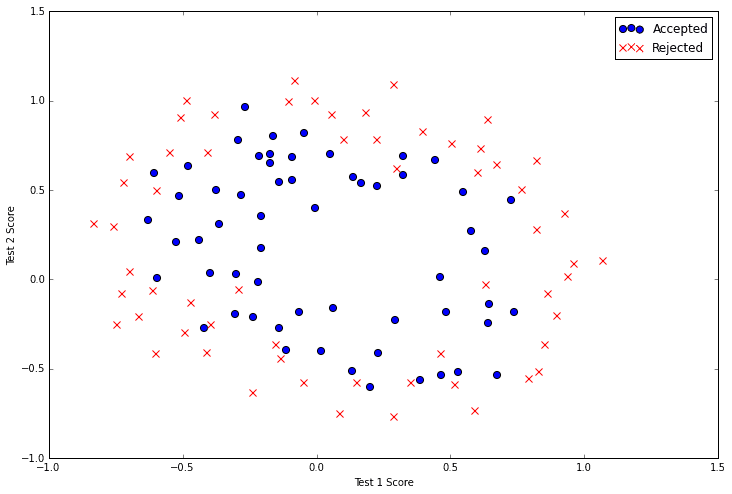
In part 2 of the series we wrapped up our implementation of multivariate linear regression using gradient descent and applied it to a simple housing prices data set. In this post we’re going to switch our objective from predicting a continuous value (regression) to classifying a result into two or more discrete buckets (classification) and apply it to a student admissions problem. Suppose that you are the administrator of a university department and you want to determine each applicant's chance of admission based on their results on two exams. You have historical data from previous applicants that you can use as a training set. For each training example, you have the applicant's scores on two exams and the admissions decision. To accomplish this, we're going to build a classification model that estimates the probability of admission based on the exam scores using a somewhat confusingly-named technique called logistic regression.
Part 4 - Multivariate Logistic Regression
In part three of this series we implemented both simple and regularized logistic regression, completing our Python implementation of the second exercise from Andrew Ng's machine learning class. There's a limitation with our solution though - it only works for binary classification. In this post we'll extend our solution from the previous exercise to handle multi-class classification. In doing so, we'll cover the first half of exercise 3 and set ourselves up for the next big topic, neural networks.
In part four we wrapped up our implementation of logistic regression by extending our solution to handle multi-class classification and testing it on the hand-written digits data set. Using just logistic regression we were able to hit a classification accuracy of about 97.5%, which is reasonably good but pretty much maxes out what we can achieve with a linear model. In this blog post we'll again tackle the hand-written digits data set, but this time using a feed-forward neural network with backpropagation. We'll implement un-regularized and regularized versions of the neural network cost function and compute gradients via the backpropagation algorithm. Finally, we'll run the algorithm through an optimizer and evaluate the performance of the network on the handwritten digits data set.
Part 6 - Support Vector Machines
We're now hitting the home stretch of both the course content and this series of blog posts. In this exercise, we'll be using support vector machines (SVMs) to build a spam classifier. We'll start with SVMs on some simple 2D data sets to see how they work. Then we'll look at a set of email data and build a classifier on the processed emails using a SVM to determine if they are spam or not.
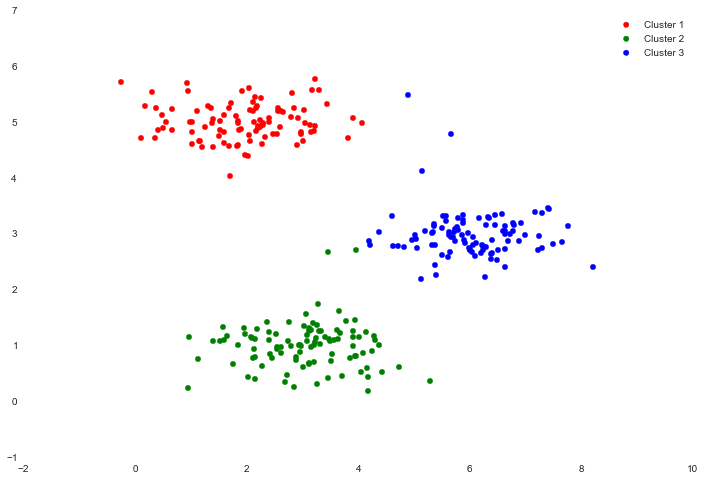
Part 7 - K-Means Clustering & PCA
We're now down to the last two posts in this series! In this installment we'll cover two fascinating topics: K-means clustering and principal component analysis (PCA). K-means and PCA are both examples of unsupervised learning techniques. Unsupervised learning problems do not have any label or target for us to learn from to make predictions, so unsupervised algorithms instead attempt to learn some interesting structure in the data itself. We'll first implement K-means and see how it can be used it to compress an image. We'll also experiment with PCA to find a low-dimensional representation of images of faces.
Part 8 - Anomaly Detection & Recommendation
We've now reached the last post in this series! It's been an interesting journey. Andrew's class was really well-done and translating it all to python has been a fun experience. In this final installment we'll cover the last two topics in the course - anomaly detection and recommendation systems. We'll implement an anomaly detection algorithm using a Gaussian model and apply it to detect failing servers on a network. We'll also see how to build a recommendation system using collaborative filtering and apply it to a movie recommendations data set.
Bio: John Wittenauer (@jdwittenauer) is a data scientist, engineer, entrepreneur, and technology enthusiast.
Related: