How To Write Efficient Python Code: A Tutorial for Beginners
Are you a programmer looking to get better at Python? Learn some of Python’s features that’ll help you write more elegant and Pythonic code.
Image by Author
Beginner programmers enjoy coding in Python because of its simplicity and easy-to-read syntax. Writing efficient Python code, however, is more involved than you think. It requires understanding of some of the features of the language (they’re just as simple to pick up, though).
If you’re coming from another programming language such as C++ or JavaScript, this tutorial is for you to learn some tips to write efficient code in Python. But if you are a beginner—learning Python as your first (programming) language—then this tutorial will help you write Pythonic code from the get go.
We’ll focus on the following:
- Pythonic loops
- List and dictionary comprehension
- Context managers
- Generators
- Collection classes
So let's dive in!
1. Write Pythonic Loops
Understanding loop constructs is important regardless of the language you’re programming in. If you’re coming from languages such as C++ or JavaScript, it's helpful to learn how to write Pythonic loops.
Generate a Sequence of Numbers with range
The range() function generates a sequence of numbers, often used as an iterator in loops.
The range() function returns a range object that starts from 0 by default and goes up to (but doesn't include) the specified number.
Here’s an example:
for i in range(5):
print(i)
Output >>>
0
1
2
3
4
When using the range() function, you can customize the starting point, ending point, and step size as needed.
Access Both Index and Item with enumerate
The enumerate() function is useful when you want both the index and the value of each element in an iterable.
In this example, we use the index to tap into the fruits list:
fruits = ["apple", "banana", "cherry"]
for i in range(len(fruits)):
print(f"Index {i}: {fruits[i]}")
Output >>>
Index 0: apple
Index 1: banana
Index 2: cherry
But with the enumerate() function, you can access both the index and the element like so:
fruits = ["apple", "banana", "cherry"]
for i, fruit in enumerate(fruits):
print(f"Index {i}: {fruit}")
Output >>>
Index 0: apple
Index 1: banana
Index 2: cherry
Iterate in Parallel Over Multiple Iterables with zip
The zip() function is used to iterate over multiple iterables in parallel. It pairs corresponding elements from different iterables together.
Consider the following example where you need to loop through both names and scores list:
names = ["Alice", "Bob", "Charlie"]
scores = [95, 89, 78]
for i in range(len(names)):
print(f"{names[i]} scored {scores[i]} points.")
This outputs:
Output >>>
Alice scored 95 points.
Bob scored 89 points.
Charlie scored 78 points.
Here's a much more readable loop with the zip() function:
names = ["Alice", "Bob", "Charlie"]
scores = [95, 89, 78]
for name, score in zip(names, scores):
print(f"{name} scored {score} points.")
Output >>>
Alice scored 95 points.
Bob scored 89 points.
Charlie scored 78 points.
The Pythonic version using zip() is more elegant and avoids the need for manual indexing—making the code cleaner and more readable.
2. Use List and Dictionary Comprehensions
In Python, list comprehensions and dictionary comprehensions are concise one-liners to create lists and dictionaries, respectively. They can also include conditional statements to filter items based on certain conditions.
Let's start with the loop version and then move on to comprehension expressions for both lists and dictionaries.
List Comprehension in Python
Say you have a numbers list. And you’d like to create a squared_numbers list. You can use a for loop like so:
numbers = [1, 2, 3, 4, 5]
squared_numbers = []
for num in numbers:
squared_numbers.append(num ** 2)
print(squared_numbers)
Output >>> [1, 4, 9, 16, 25]
But list comprehensions provide a cleaner and simpler syntax to do this. They allow you to create a new list by applying an expression to each item in an iterable.

List Comprehension Syntax | Image by Author
Here’s a concise alternative using a list comprehension expression:
numbers = [1, 2, 3, 4, 5]
squared_numbers = [num ** 2 for num in numbers]
print(squared_numbers)
Output >>> [1, 4, 9, 16, 25]
Here, the list comprehension creates a new list containing the squares of each number in the numbers list.
List Comprehension with Conditional Filtering
You can also add filtering conditions within the list comprehension expression. Consider this example:
numbers = [1, 2, 3, 4, 5]
odd_numbers = [num for num in numbers if num % 2 != 0]
print(odd_numbers)
Output >>> [1, 3, 5]
In this example, the list comprehension creates a new list containing only the odd numbers from the numbers list.
Dictionary Comprehension in Python
With a syntax similar to list comprehension, dictionary comprehension allows you to create dictionaries from existing iterables.

Dictionary Comprehension Syntax | Image by Author
Say you have a fruits list. You’d like to create a dictionary with fruit:len(fruit) key-value pairs.
Here’s how you can do this with a for loop:
fruits = ["apple", "banana", "cherry", "date"]
fruit_lengths = {}
for fruit in fruits:
fruit_lengths[fruit] = len(fruit)
print(fruit_lengths)
Output >>> {'apple': 5, 'banana': 6, 'cherry': 6, 'date': 4}
Let’s now write the dictionary comprehension equivalent:
fruits = ["apple", "banana", "cherry", "date"]
fruit_lengths = {fruit: len(fruit) for fruit in fruits}
print(fruit_lengths)
Output >>> {'apple': 5, 'banana': 6, 'cherry': 6, 'date': 4}
This dictionary comprehension creates a dictionary where keys are the fruits and values are the lengths of the fruit names.
Dictionary Comprehension with Conditional Filtering
Let’s modify our dictionary comprehension expression to include a condition:
fruits = ["apple", "banana", "cherry", "date"]
long_fruit_names = {fruit: len(fruit) for fruit in fruits if len(fruit) > 5}
print(long_fruit_names)
Output >>> {'banana': 6, 'cherry': 6}
Here, the dictionary comprehension creates a dictionary with fruit names as keys and their lengths as values, but only for fruits with names longer than 5 characters.
3. Use Context Managers for Effective Resource Handling
Context managers in Python help you manage resources efficiently. With context managers, you can set up and tear down (clean up) resources easily. The simplest and the most common example of context managers is in file handling.
Look at the code snippet below:
filename = 'somefile.txt'
file = open(filename,'w')
file.write('Something')
It doesn't close the file descriptor resulting in resource leakage.
print(file.closed)
Output >>> False
You’ll probably come up with the following:
filename = 'somefile.txt'
file = open(filename,'w')
file.write('Something')
file.close()
While this attempts to close the descriptor, it does not account for the errors that may arise during the write operation.
Well, you may now implement exception handling to try to open a file and write something in the absence of any errors:
filename = 'somefile.txt'
file = open(filename,'w')
try:
file.write('Something')
finally:
file.close()
But this is verbose. Now look at the following version using the with statement that supports open() function which is a context manager:
filename = 'somefile.txt'
with open(filename, 'w') as file:
file.write('Something')
print(file.closed)
Output >>> True
We use the with statement to create a context in which the file is opened. This ensures that the file is properly closed when the execution exits the with block—even if an exception is raised during the operation.
4. Use Generators for Memory-Efficient Processing
Generators provide an elegant way to work with large datasets or infinite sequences—improving code efficiency and reducing memory consumption.
What Are Generators?
Generators are functions that use the yield keyword to return values one at a time, preserving their internal state between invocations. Unlike regular functions that compute all values at once and return a complete list, generators compute and yield values on-the-fly as they are requested, making them suitable for processing large sequences.
How Do Generators Work?
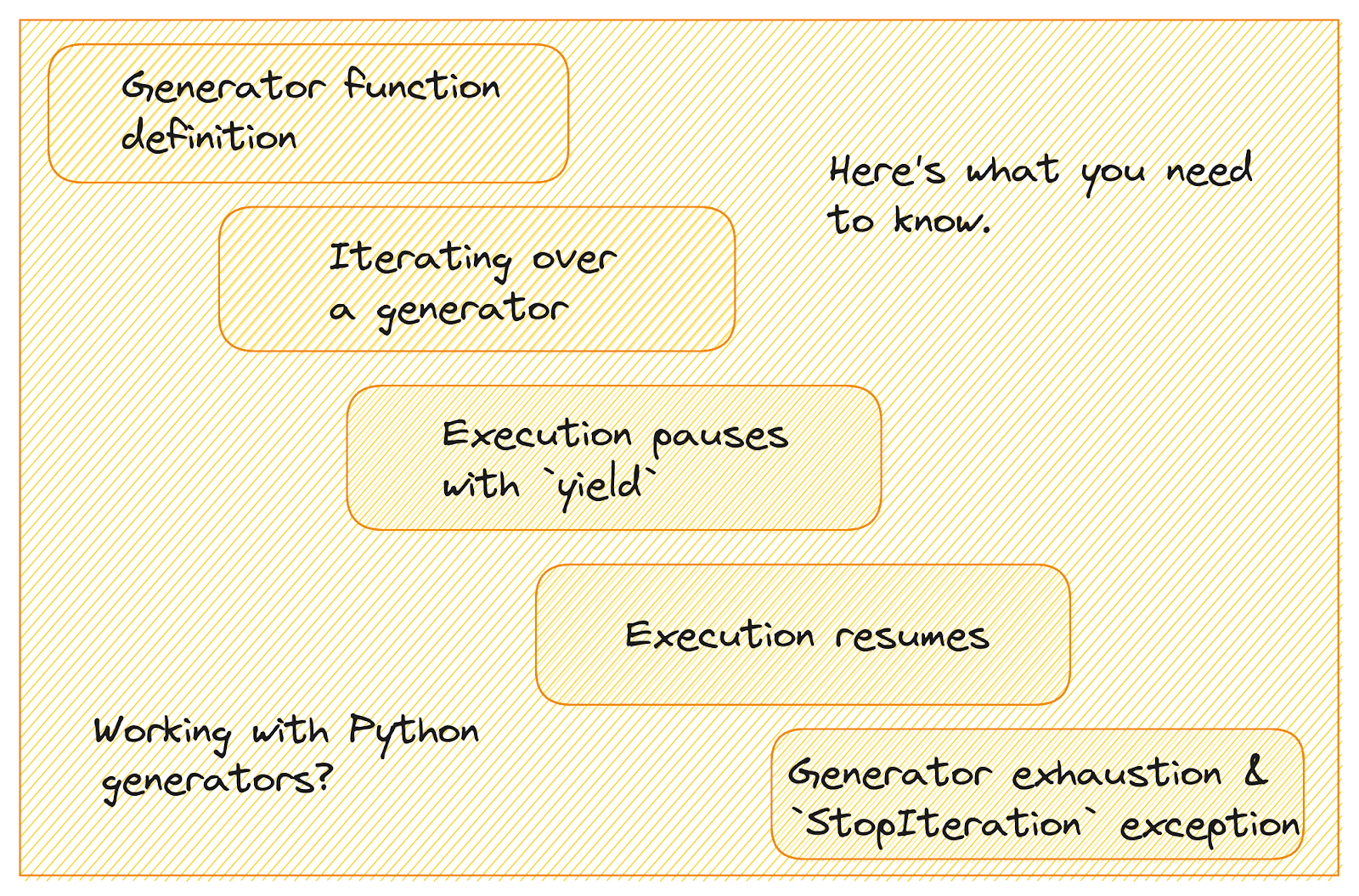
Image by Author
Let’s learn how generators work:
- A generator function is defined like a regular function, but instead of using the
returnkeyword, you’ll useyieldto yield a value. - When you call a generator function, it returns a generator object. Which you can iterate over using a loop or by calling
next(). - When the
yieldstatement is encountered, the function's state is saved, and the yielded value is returned to the caller. The function's execution pauses, but its local variables and state are retained. - When the generator's
next()method is called again, execution resumes from where it was paused, and the function continues until the nextyieldstatement. - When the function exits or raises a
StopIterationexception, the generator is considered exhausted, and further calls tonext()will raiseStopIteration.
Creating Generators
You can create generators using either generator functions or generator expressions.
Here’s an example generator function:
def countdown(n):
while n > 0:
yield n
n -= 1
# Using the generator function
for num in countdown(5):
print(num)
Output >>>
5
4
3
2
1
Generator expressions are similar to list comprehension but they create generators instead of lists.
# Generator expression to create a sequence of squares
squares = (x ** 2 for x in range(1, 6))
# Using the generator expression
for square in squares:
print(square)
Output >>>
1
4
9
16
25
5. Leverage Collection Classes
We’ll wrap up the tutorial by learning about two useful collection classes:
- NamedTuple
- Counter
More Readable Tuples with NamedTuple
In Python, a namedtuple in the collections module is a subclass of the built-in tuple class. But it provides named fields. Which makes it more readable and self-documenting than regular tuples.
Here’s an example of creating a simple tuple for a point in 3D space and accessing the individual elements:
# 3D point tuple
coordinate = (1, 2, 3)
# Accessing data using tuple unpacking
x, y, z = coordinate
print(f"X-coordinate: {x}, Y-coordinate: {y}, Z-coordinate: {z}")
Output >>> X-coordinate: 1, Y-coordinate: 2, Z-coordinate: 3
And here’s the namedtuple version:
from collections import namedtuple
# Define a Coordinate3D namedtuple
Coordinate3D = namedtuple("Coordinate3D", ["x", "y", "z"])
# Creating a Coordinate3D object
coordinate = Coordinate3D(1, 2, 3)
print(coordinate)
# Accessing data using named fields
print(f"X-coordinate: {coordinate.x}, Y-coordinate: {coordinate.y}, Z-coordinate: {coordinate.z}")
Output >>>
Coordinate3D(x=1, y=2, z=3)
X-coordinate: 1, Y-coordinate: 2, Z-coordinate: 3
NamedTuples, therefore, let you write cleaner and more maintainable code than regular tuples.
Use Counter to Simplify Counting
Counter is a class in the collections module that is designed for counting the frequency of elements in an iterable such as a list or a string). It returns a Counter object with {element:count} key-value pairs.
Let’s take the example of counting character frequencies in a long string.
Here’s the conventional approach to counting character frequencies using loops:
word = "incomprehensibilities"
# initialize an empty dictionary to count characters
char_counts = {}
# Count character frequencies
for char in word:
if char in char_counts:
char_counts[char] += 1
else:
char_counts[char] = 1
# print out the char_counts dictionary
print(char_counts)
# find the most common character
most_common = max(char_counts, key=char_counts.get)
print(f"Most Common Character: '{most_common}' (appears {char_counts[most_common]} times)")
We manually iterate through the string, update a dictionary to count character frequencies, and find the most common character.
Output >>>
{'i': 5, 'n': 2, 'c': 1, 'o': 1, 'm': 1, 'p': 1, 'r': 1, 'e': 3, 'h': 1, 's': 2, 'b': 1, 'l': 1, 't': 1}
Most Common Character: 'i' (appears 5 times)
Now, let's achieve the same task using the Counter class using the syntax Counter(iterable):
from collections import Counter
word = "incomprehensibilities"
# Count character frequencies using Counter
char_counts = Counter(word)
print(char_counts)
# Find the most common character
most_common = char_counts.most_common(1)
print(f"Most Common Character: '{most_common[0][0]}' (appears {most_common[0][1]} times)")
Output >>>
Counter({'i': 5, 'e': 3, 'n': 2, 's': 2, 'c': 1, 'o': 1, 'm': 1, 'p': 1, 'r': 1, 'h': 1, 'b': 1, 'l': 1, 't': 1})
Most Common Character: 'i' (appears 5 times)
So Counter provides a much simpler way to count character frequencies without the need for manual iteration and dictionary management.
Wrapping Up
I hope you found a few useful tips to add to your Python toolbox. If you are looking to learn Python or are preparing for coding interviews, here are a couple of resources to help you in your journey:
Happy learning!
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.