 Are Data Lakes Fake News?
Are Data Lakes Fake News?
 Are Data Lakes Fake News?
Are Data Lakes Fake News?The quick answer is yes, and the biggest problem is that the term “Data Lakes” has been overloaded by vendors and analysts with different meanings, resulting in an ill-defined and blurry concept.
Uli Bethke, Sonra.
Are data lakes fake news? The quick answer is yes and in this post I will show you why.
The biggest problem I have with data lakes is that the term has been overloaded by vendors and analysts with meanings. Sometimes it seems that anything that does not fit into the traditional data warehouse architecture falls under the catch all phrase of the data lake. The result is an ill-defined and blurry concept. We all know that blurred terminology leads to blurred thinking, which in turn leads to poor decisions.
I have come across various definitions for a data lake. We will discuss all of them in this post. Sometimes people only refer to one of these ideas when talking about a data lake other times they mix and match these concepts. Some people mean all of the things below when they refer to a data lake. Others are more selective.

The Data Lake as a Raw Data Reservoir
This is the original meaning of a data lake. In this definition the data lake is not too dissimilar to a staging area in a data warehouse. In a staging area we make a copy of the data from the source systems. We transform and integrate this data downstream to populate our data warehouse. A raw data reservoir can be used to replace an EDW staging area.
There are a few important differences between the idea of a staging area and a raw data reservoir.
- Traditionally, a staging area only has one consumer: the downstream processes to populate the data warehouse. The raw data reservoir on the other hand has multiple consumers including the ETL to populate the data warehouse. Other consumers could be sandboxes for self-service and advanced analytics, enterprise search engines, an MDM hub etc. One of the benefits of making the raw data available to more consumers is that we don’t hit our source systems multiple times.
- In a data reservoir we also store unstructured data, e.g. text, audio, and video.
- Last but not least we can optionally audit and version the raw data by keeping an immutable history of changes. This might be useful for compliance reasons.
The concept of a raw data reservoir is useful and it borrows a lot of ideas from the staging area of an EDW, albeit with a few updates. It should be one of the core components of a modern enterprise data architecture. Remember though that raw data is not useful in its own right. It only becomes useful in the context of integrations, transformations, and yes ETL. I go into more details on the raw data reservoir in my training course Big Data for Data Warehouse Professionals.
Data Lake as Data Reservoir + ETL
Sometimes people also include ETL as a core component of a data lake. This is slight variation on the data reservoir theme. In this formula data lake = data reservoir + ETL.
Data Hoarding Disorder
I think we can all agree that the idea of a raw data reservoir is a useful concept. However, some people suggest to store any and all enterprise data in the data reservoir. It might become useful at some distant future. This is a recipe for disaster. I call this the data hoarding disorder (or messy syndrome as we call it in German).
“Hoarding often creates such cramped living conditions that homes may be filled to capacity, with only narrow pathways winding through stacks of clutter. Countertops, sinks, stoves, desks, stairways and virtually all other surfaces are usually piled with stuff. And when there’s no more room inside, the clutter may spread to the garage, vehicles, yard and other storage facilities.” Mayo Clinic
I presume you get the idea. It’s not a good idea to store data just for the sake of storing it. You will need a well-defined use case and only feed relevant data into the data supply chain. Once we have no more use for the data in the data reservoir we discard it. It is not always necessary to store all of the data that a particular business process generates. Let’s take IOT as an example. Sensors generate humongous amounts of data. In most cases we are only interested in the outliers of this data, e.g. if the temperature rises above a certain threshold. Bill Inmon discusses various data reduction techniques for IoT use cases in his book Data Lake Architecture.
Technologies for Raw Data Reservoir
You might wonder which technologies are a good fit for a data reservoir. This really depends on the type of your data. For unstructured data, a distributed file system such as S3 or HDFS is a good fit. For small volumes of data, e.g. reference, master data, or application data from operational systems, a relational database is a perfect fit. Remember, Hadoop has a problem working with small volumes of data aka the small files problem. A distributed file system is a good fit for very large volumes of event and transactional data. A queue such as Kafka might also be a good fit as a persistent event store for very large volumes of transactional data. Typically Kafka is used as a transient storage engine and using it for persistent storage may seem unusual. I would be interested to hear from people who have experience using Kafka as persistent storage for raw data (reach out to me on LinkedIn ).
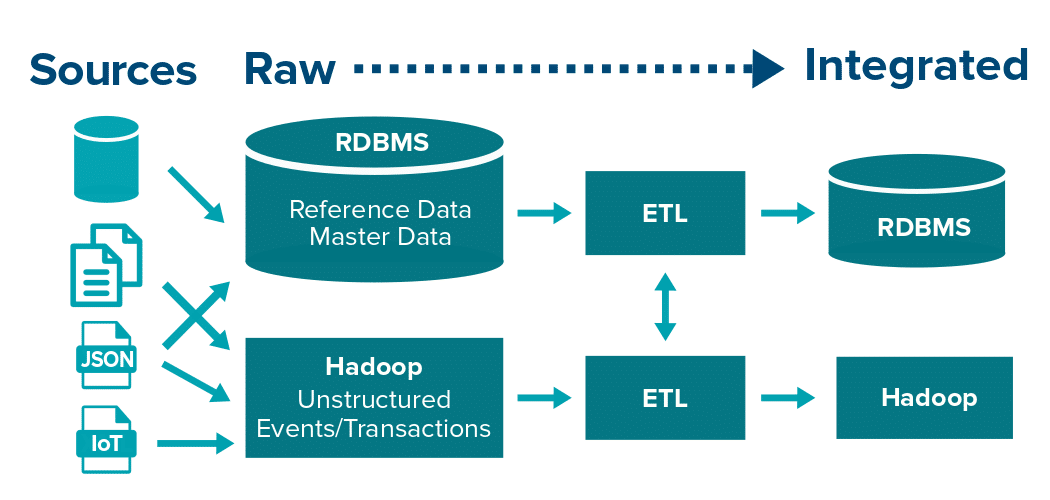
You can transform and integrate the data downstream on these same technologies. Transformations for reference/small data can be done in the RDBMS. Hadoop is a good fit for transforming unstructured data or very large data volumes. Reference data can also be replicated to Hadoop for lookups or accessed via federated query engines. Row storage is best for both Hadoop and the RDBMS.
The Data Lake as a Platform for Self-Service Analytics
Vendors and analysts often combine the concept of the raw data reservoir with the idea of self-service analytics. In this data fairy tale business users tap into the central “data lake” to generate insights without involvement of IT or the new bad boy ETL. Throw in a bit of data governance and a tool (data discovery/preparation) and you are good to go. Sounds too good to be true? Well it is.
The fallacy of the data lake
What are the main problems with this approach?
- Your typical business user has not even time or interest to master ad-hoc style querying using a Business Intelligence tool. What do you think they will tell you when you introduce them to a data preparation tool? Do you really think they would be able to wrangle with raw data? The best data governance and data preparation tool in the world won’t help. In fairness there are probably a few business users (typically accountants, the original data analysts) that are good at working with data and analytics, but the vast majority has no time or interest to spend any amount of time wrangling with data. This is not to say that decision makers and business users don’t need to be skilled in dealing with data. Quite the opposite. However, they don’t need to go into the nitty gritty details of wrangling with data.
- Can you imagine hundreds or thousands of users running analytics and exploratory workloads against a central data lake in an enterprise? It is hard enough to plan and size a data warehouse for what more or less are highly predictable workloads. BI queries are typically similar and repetitive, which makes them good candidates for caching. This is very different from an exploratory environment where it can take just one rogue query to bring down the cluster, e.g. some analysis that requires processing of a huge data set on the master node rather than the data nodes. While this can be handled to some extent through training and software that intercepts rogue queries it does not make it a pleasant experience. You would need hundreds or thousands of servers to cater for a central environment that grants access to a huge part of the workforce. While this scenario is feasible for big web companies that have data written into their DNA I can’t see it happening for your average enterprise any time soon.
Is Self-Service Analytics just a pipe dream?
Is the self-service vision of data lakers impossible to implement? I don’t think so. However, the concept of self-service itself needs to be redefined. Here is my vision for a successful self-service analytics platform.
Users of Self-Service Analytics
What is the target audience for self-service analytics? We have already found out that it’s not our typical business person or executive. Self-service users are data analysts, Excel power users, data engineers, and data scientists. As a rule of thumb these are employees skilled in the art of working with data. Most of these employees also have some technical background and write code. At a minimum they should be familiar with SQL. What this group of users typically lacks is a web based platform in the enterprise that caters for their particular needs. These data workers want to collaborate on a problem, share and re-use code and datasets, write less code by using a GUI, automate certain tasks, write code where necessary, visualise and explore data etc. The concept of self-service analytics that I have in mind would give these resources a home in the enterprise to make them more productive in their job.
Minimal Involvement of IT
Self-service analytics by definition minimises the involvement of IT. It is the role of IT to provision the infrastructure, manage access and permissions to data, and monitor performance. IT resources including ETL developers are not involved in transforming the data. Wrangling with data is a self-service function.
Self-service users may come from various corners of the enterprise. They may be embedded into business units or work in a centralised data competency centre.
Sandboxes for Self-Service Analytics
Self-service analytics should only be used and applied in the context of a well-defined problem, which can be solved with data. Hence the concept of a centrally managed “data lake” is inappropriate in my opinion as this encourages data anarchy and takes away focus. Each well-defined problem gets its own sandbox environment, budget, and resources (people, hardware, software). Once this has been accomplished we can pull the required data into the data playground.
Note: We select the technology for this sandbox environment based on the problem at hand. Don’t jump to Hadoop like a Pavlovian dog.
Scenarios for Self-Service Analytics
Scenario 1: Data Profiling & Exploratory Analysis
A new subject area needs to be brought into the data warehouse. As part of the EDW lifecycle a data analyst needs to establish the profile, integrity, and quality of the data sources. The data analyst spins up a sandbox environment, pulls the data from the sources and uses the data preparation platform to explore, profile, visualise and lightly integrate the data where needed.
Scenario 2: Performance Analysis
We need to analyse the sales performance of a company that has been acquired. The relevant data sources have not yet been loaded to the data warehouse. In the past an army of data analysts would have been tasked to pull the data from the new sources into Excel or some other client tool. They then would have been locked away for a few weeks pouring over this data (going mad at the same time). Because of the brittleness of the whole process and the tools involved we often ended up with incorrect results. In the new world we can spin up a sandbox environment, pull in the required data, use a web based data preparation tool to transform and integrate the data and use Tableau or similar to present the data back to executives. As a nice side effect we can more easily productionise the insights generated. The self-service analytics platform acts as a data exhaust for the data warehouse.
Scenario 3: Advanced Analytics
Which of our customers will churn? This is a standard problem for predictive analytics. In the past, client tools such as Matlab, SPSS or even Excel were used to find answers. Employees pulled the required data onto their laptops and worked away. This approach is flawed for various reasons. It lacks collaboration features, puts the security of enterprise data at risk (think of lost laptops without data encryption), and the approach does not scale beyond small volumes of data. With a sandbox we can pull the required data into a web based environment and collaboratively go through the lifecycle of building, training, and productionising a predictive model.
As you can see from all of these scenarios, sandboxes are indeed a useful addition to the traditional data warehouse architecture.
In this section we have only scratched on the surface of what we need to consider when implementing self-service sandboxes. I cover a lot of the items in my training course Big Data for Data Warehouse and BI Professionals. Below is a non-exhaustive list.
- Data Governance
- Technologies
- What are some recommended Tools (Data Preparation and Data Science Platforms)
- How can we productionise the insights from self-service analytics?
The Data Lake is Hadoop
Let’s move on to another popular definition of a data lake. A data lake is Hadoop or some other technology. This doesn’t really make much sense. The data lake is a concept (albeit fuzzy) and Hadoop is a technology for a limited number of use cases. This is the same mistake as saying that the data warehouse is a relational database. Here is a funny read about this misunderstanding on Bill Inmon’s blog.
Somewhat related to this concept is the idea that all data applications in an enterprise should be run on the Hadoop platform, e.g. as Docker containers and using a resource manager, e.g. YARN.
Data Lakes – Summary
Data lakes have various flaws. Some of them have been discussed in detail elsewhere, e.g.lack of data governance and metadata management. The usefulness of schema on read and raw data is also completely overstated. I should also mention the NoETL lie in this context, which is another ridiculous idea coming from vendor’s marketing departments.
The main issues I have with data lakes are summarised below:
- The term is a catch all phrase for anything that does not fit into the traditional data warehouse architecture. There is no industry consensus on a useful definition.
- The idea that data lakes can be accessed by users without technical and/or data analytics skills is ludicrous.
- Should the data lake really be a central storage and processing area for all of our data and data applications?
- Saying that data lakes are a technology is like comparing apples to pears.
So where does this leave us? There are useful concepts and ideas (if applied correctly) that fall under the data lake label, e.g. the raw data reservoir and self-service analytics. However, as the term is more or less a catch all phrase for anything non data warehouse and used for a diverse range of concepts and ideas it is not a useful term. As an industry we should abandon it.
Original. Reposted with permission.
Bio: Uli Bethke is CEO at Sonra and Chair at Hadoop User Group IRL.
Related: