Histogram 202: Tips and Tricks for Better Data Science
We show how to make an ideal histogram, share some tips, and give examples. Let's dive into the world of binning.
By Norbert Obsuszt, AnswerMiner.
Compared to other summarizing methods, histograms have the richest descriptive power while being the fastest way to interpret data – the human brain prefers visual perception. However, if you are not careful, viewers will not be able to understand your histogram, or you may fail to get the most out of it. It is especially important to specify the optimal bin size.
Why Choose Histograms?
If you have a set of data values, you probably want to share this information with your boss or co-workers to build a better business based on the information contained in these data. These data values could be any of the following:
- Customers’ ages
- Monthly revenues
- Length of time visitors spend on your website
- The number of sold cars by agents
You should share the information in a compact way because nobody wants to read numeric values one by one.
Alternatives are Wrong
Suppose you have a set of numbers: 1, 23, 24, 25, 25, 25, 26, 27, 30, 32, 999
The mean value (112.45) is very sensitive to outliers. Almost all real-world data has outliers, so the mean value can be very misleading.
The median value (25) does not tell you anything about the distribution.
The full range (1 – 999) just shows the outliers.
The standard deviation (294.1436) can be hard to be interpreted without a statistical background.
The variance (86520.47) can be also hard to be interpreted without a statistical background.
Interquartile range (IQR) (24.5 – 28.5) is the central 50% of your values and does not tell you anything about the other 50%.
Which do you think describes the numbers best? The answer is none of them because these numeric summarizing techniques do not include any information about spikes, or the shape of the distribution. Therefore, you should use always a histogram.
Bin Carefully
Histograms are column-charts, which each column represents a range of the values, and the height of a column corresponds to how many values are in that range.
The wider the range (bin width) you use, the fewer columns (bins) you will have.
Bin that are too wide can hide important details about distribution while bin that are too narrow can cause a lot of noise and hide important information about the distribution as well. The width of the bins should be equal, and you should only use round values like 1, 2, 5, 10, 20, 25, 50, 100, and so on to make it easier for the viewer to interpret the data.
These histograms were created from the same example dataset that contains 550 values between 12 and 69.

Too-wide: Too wide bins, unable to detect unusual spike at around 53

Too-narrow: Too narrow bins, there are lots of spikes just by coincidence

Unpretty: Hard to read, because bins have unpretty 7 width
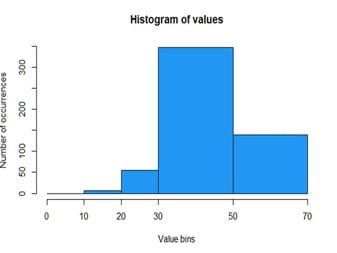
Unequal: Hard to read, because widths of bins are not equal
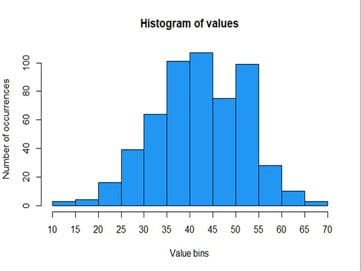
Ideal: This one is good.
TIPS
If you have a small amount of data, use wider bins to eliminate noise. If you have a lot of data, use narrower bins because the histogram will not be that noisy.
Methods That You Can Use
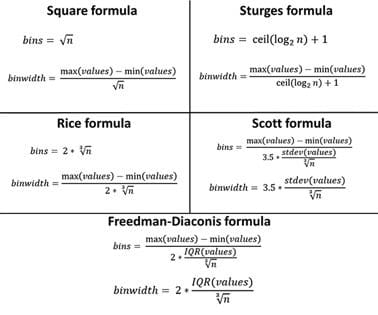
In the case of the above used dataset (that contains 550 values between 12 and 69) we get the following result:
| Square-root | Sturges | Rice | Scott | Freedman-Diaconis | |
| Number of bins | 23 | 11 | 17 | 14 | 16 |
| Bin width | 2 | 5 | 3 | 4 | 4 |
Opened or Closed
It is not so easy to decide. Now comes the trouble. If you look at the 10-15-20-25… binned histogram, are the occurrences of value “20” represented in the second column, the third column, or both? Obviously, you need to put each specific value into an exact bin.
Two options are available to be able to do so:
Option A - All bins should have left-open, right-closed intervals
| First Bin: | (10,15] | Contains these values: | 11 | 12 | 13 | 14 | 15 |
| Second bin: | (15,20] | Contains these values: | 16 | 17 | 18 | 19 | 20 |
| Third bin: | (20,25] | Contains these values: | 21 | 22 | 23 | 24 | 25 |
Option B - All bins should have left-closed, right-open intervals
| First bin: | [10,15) | Contains these values: | 10 | 11 | 12 | 13 | 14 |
| Second bin: | [15,20) | Contains these values: | 15 | 16 | 17 | 18 | 19 |
| Third bin: | [20,25) | Contains these values: | 20 | 21 | 22 | 23 | 24 |
Avoid the Trap
You are free to choose any of these options, but be careful! With both of these options, one value will not be included in the histogram. If you choose option #1, then value “10” will not be included in any of the bins. If you choose option #2, then value “25” will not be included in any of the bins.
The solution is to force the histogram to have the first or last bin be a full-closed interval. We suggest you do this with the last bin when using option #2 because uniform bins are usually more important on the left side than on the right. If you have integer values, it is recommended to label the bins “10-14,” “15-19,” and “20-25” instead of writing out “10,” “15,” “20,” “25.” In this case, viewers of the histogram will understand it better.
Bio: Norbert Obsuszt is the founder of AnswerMiner (www.answerminer.com), data scientist, and programmer. He took his degree in maths and programming. Norbert is passionate about Data Analytics, Predictive Analytics, and Data Science. He can be reached at norbert.obsuszt@answerminer.com or LinkedIn
Related