A Beginner’s Guide to Data Engineering – Part II
In this post, I share more technical details on how to build good data pipelines and highlight ETL best practices. Primarily, I will use Python, Airflow, and SQL for our discussion.
The Anatomy of an Airflow Pipeline

Now that we have learned about the concept of fact tables, dimension tables, date partitions, and what it means to do data backfilling, let’s crystalize these concepts and put them in an actual Airflow ETL job.
Defining the Directed Acyclic Graph (DAG)
As we mentioned in the earlier post, any ETL job, at its core, is built on top of three building blocks: Extract, Transform, and Load. As simple as it might sound conceptually, ETL jobs in real life are often complex, consisting of many combinations of E, T, and L tasks. As a result, it is often useful to visualize complex data flows using a graph. Visually, a node in a graph represents a task, and an arrow represents the dependency of one task on another. Given that data only needs to be computed once on a given task and the computation then carries forward, the graph is directed and acyclic. This is why Airflow jobs are commonly referred to as “DAGs” (Directed Acyclic Graphs).

Source: A screenshot of Airbnb’s Experimentation Reporting Framework DAG
One of the clever designs about Airflow UI is that it allows any users to visualize the DAG in a graph view, using code as configuration. The author of a data pipeline must define the structure of dependencies among tasks in order to visualize them. This specification is often written in a file called the DAG definition file, which lays out the anatomy of an Airflow job.
Operators: Sensors, Operators, and Transfers
While DAGs describe how to run a data pipeline, operators describe what to do in a data pipeline. Typically, there are three broad categories of operators:
- Sensors: waits for a certain time, external file, or upstream data source
- Operators: triggers a certain action (e.g. run a bash command, execute a python function, or execute a Hive query, etc)
- Transfers: moves data from one location to another
Shrewd readers can probably see how each of these operators correspond to the Extract,
Transform, and Load steps that we discussed earlier.
Sensors unblock the data flow after a certain time has passed or when data from an upstream data source becomes available. At Airbnb, given that most of our ETL jobs involve Hive queries, we often used NamedHivePartitionSensors to check whether the most recent partition of a Hive table is available for downstream processing.
Operators trigger data transformations, which corresponds to the Transform step. Because Airflow is open-source, contributors can extend BaseOperatorclass to create custom operators as they see fit. At Airbnb, the most common operator we used is HiveOperator (to execute hive queries), but we also use PythonOperator (e.g. to run a Python script) and BashOperator (e.g. to run a bash script, or even a fancy Spark job) fairly often. The possibilities are endless here!
Finally, we also have special operators that Transfers data from one place to another, which often maps to the Load step in ETL. At Airbnb, we use MySqlToHiveTransfer or S3ToHiveTransfer pretty often, but this largely depends on one’s data infrastructure and where the data warehouse lives.
A Simple Example
Below is a simple example that demonstrate how to define a DAG definition file, instantiate a Airflow DAG, and define the corresponding DAG structure using the various operators we described above.
When the DAG is rendered, we see the following graph view:
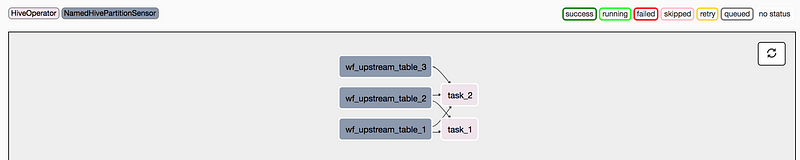
Graph View of the toy example DAG
ETL Best Practices To Follow

Image Credit: Building your craft takes practice, so it’s wise to follow best practices
Like any craft, writing Airflow jobs that are succinct, readable, and scalable requires practice. On my first job, ETL to me was just a series of mundane mechanical tasks that I had to get done. I did not see it as a craft nor did I know the best practices. At Airbnb, I learned a lot about best practices and I started to appreciate good ETLs and how beautiful they can be. Below, I list out a non-exhaustive list of principles that good ETL pipelines should follow:
- Partition Data Tables: As we mentioned earlier, data partitioning can be especially useful when dealing with large-size tables with a long history. When data is partitioned using datestamps, we can leverage dynamic partitions to parallelize backfilling.
- Load Data Incrementally: This principle makes your ETL more modular and manageable, especially when building dimension tables from the fact tables. In each run, we only need to append the new transactions to the dimension table from previous date partition instead of scanning the entire fact history.
- Enforce Idempotency: Many data scientists rely on point-in-time snapshots to perform historical analysis. This means the underlying source table should not be mutable as time progresses, otherwise we would get a different answer. Pipeline should be built so that the same query, when run against the same business logic and time range, returns the same result. This property has a fancy name called Idempotency.
- Parameterize Workflow: Just like how templates greatly simplified the organization of HTML pages, Jinja can be used in conjunction with SQL. As we mentioned earlier, one common usage of Jinja template is to incorporate the backfilling logic into a typical Hive query. Stitch Fix has a very nice post that summarized how they use this technique for their ETL.
- Add Data Checks Early and Often: When processing data, it is useful to write data into a staging table, check the data quality, and only then exchange the staging table with the final production table. At Airbnb, we call this the stage-check-exchange paradigm. Checks in this 3-step paradigm are important defensive mechanisms — they can be simple checks such as counting if the total number of records is greater than 0 or something as complex as an anomaly detection system that checks for unseen categories or outliers.
A skeleton of stage-check-exchange operation (aka “Unit Test” for data pipelines)
- Build Useful Alerts & Monitoring System: Since ETL jobs can often take a long time to run, it’s useful to add alerts and monitoring to them so we do not have to keep an eye on the progress of the DAG constantly. Different companies monitor DAGs in many creative ways — at Airbnb, we regularly use EmailOperators to send alert emails for jobs missing SLAs. Other teams have used alerts to flag experiment imbalances. Yet another interesting example is from Zymergen where they report model performance metrics such as R-squared with a SlackOperator.
Many of these principles are inspired by a combination of conversations with seasoned data engineers, my own experience building Airflow DAGs, and readings from Gerard Toonstra’s ETL Best Practices with Airflow. For the curious readers, I highly recommend this following talk from Maxime:
Source: Maxime, the original author of Airflow, talking about ETL best practices
Recap of Part II
In the second post of this series, we discussed star schema and data modeling in much more details. We learned the distinction between fact and dimension tables, and saw the advantages of using datestamps as partition keys, especially for backfilling. Furthermore, we dissected the anatomy of an Airflow job, and crystallized the different operators available in Airflow. We also highlighted best practices for building ETL, and showed how flexible Airflow jobs can be when used in conjunction with Jinja and SlackOperators. The possibilities are endless!
In the last post of the series, I will discuss a few advanced data engineering patterns — specifically, how to go from building pipelines to building frameworks. I will again use a few example frameworks that we used at Airbnb as motivating examples.
If you found this post useful, please visit Part I and stay tuned for Part III.
I want to appreciate Jason Goodman and Michael Musson for providing invaluable feedback to me
Bio: Robert Chang is a data scientist at Airbnb working on Machine Learning, Machine Learning Infrastructure, and Host Growth. Prior to Airbnb, he was a data scientist at Twitter and have a degree in Statistics from Stanford University and a degree of Operations Research from UC Berkeley.
Original. Reposted with permission.
Related:
- A Beginner’s Guide to Data Engineering – Part I
- Advice For New and Junior Data Scientists
- How to Build a Data Science Pipeline