 How to Build a Data Science Pipeline
How to Build a Data Science Pipeline
 How to Build a Data Science Pipeline
How to Build a Data Science PipelineStart with y. Concentrate on formalizing the predictive problem, building the workflow, and turning it into production rather than optimizing your predictive model. Once the former is done, the latter is easy.
By Balázs Kégl, Data scientist, co-creator of RAMP.
There is no debate on how a well-functioning predictive workflow works when it is finally put into production. Data sources are transformed into a set of features or indicators X, describing each instance (client, piece of equipment, asset) on which the prediction will act on. A predictor then turns X into an actionable piece of information y_pred (will the client churn?, will the equipment fail?, will the asset price go up?). In certain fluid markets (e.g., ad targeting) the prediction is then monetized through a fully automated process, in other cases it is used as decision support with a human in the loop.
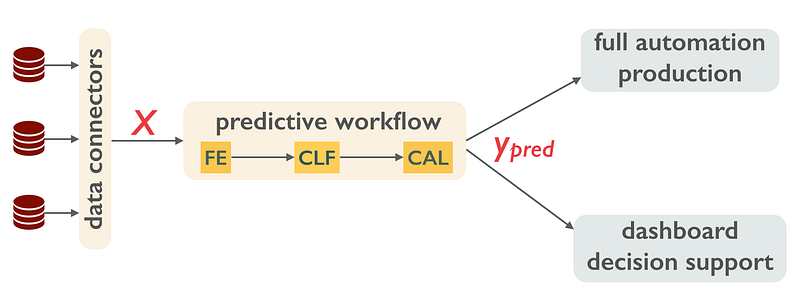
The data flow in a data science pipeline in production.
This sounds simple, yet examples of working and well-monetized predictive workflows are rare. Companies struggle with the building process. The questions they need to ask are:
- Who builds this workflow? What are the roles and expertises I need to cover?
- What is the building process? What are the steps, and what expertise I need at each step?
- What are the costs and risks at any of those steps, and how do I control them?
Hype around data challenges gave the false impression that the data scientist and the predictive score are the main drivers of the process. Even industrial processes (e.g., CRISP-DM and Dataiku) that have been around since the nineties usually put the data scientist in the center and deployment at the end of the process. While they are not wrong, they are mostly irrelevant. Building and optimizing the predictor is easy. What is hard is finding the business problem and the KPI that it will improve, hunting and transforming the data into digestible instances, defining the steps of the workflow, putting it into production, and organizing the model maintenance and regular update.
Companies usually start by what seems to be a no brainer: asking their IT departments to put in place the big data infrastructure and build a data lake. They then hire their first data scientists. These experts, fresh off school and a handful of Kaggle challenges, armed with the data science toolkit, are eager to put their hands on the data. They can predict anything, and they do! They talk the business unit, they find reasonable prediction targets for which labels exist already, they try a dozen models, hyperopt them, and choose the best. They build POCs and send reports to the business unit. And then start again.
The usual way to construct a data science workflow.
Most of those POCs never go into production. The business unit doesn’t know what to do with them. They can’t interpret the scores. The prediction target seems reasonable, yet they have no clue how they will make a money with their y_pred. If they do, putting the POC into production seems insurmountable. Code has to be rewritten. Real time data has to be channeled into the workflow. Operational constraints need to be satisfied. The decision support system needs to be integrated with the existing work tools of the users. Model maintenance, user feedback, rollback needs to be put in place. These operations usually cost more and create more risk than the safe POCs the data scientist worked on, and the POC simply cannot drive the process.
The process I describe below will not solve these problems, but it gives you an ordering in which you can at least address and control costs and risks. First, find a chief data officer (or rather a data value architect) at any cost who has already put in production a predictive workflow. Your CDO doesn’t need to know the latest deep learning architecture, but she should have a broad understanding of both the business of the company and the data science process. She should play a central role and drive the process.
Getting IT on board early is important. You need your data lake, but more importantly, you need data engineers to think in terms of production from day one. But this is not the first step. The first step is to figure out whether you need a prediction at all.
So, start with y, the prediction target.
Your CDO should work closely and longly with the business unit to figure out what they want to know. What y drives their decisions? How would a better prediction of y will improve the bottom line (cost down, profit up, productivity up)? Once you have your y, try to monetize prediction error as much as possible. There is nothing that makes your (future) data scientists happier than a well monetized metrics. They will know that improving their score by 2% make you a million dollars; more importantly you will know how much you can spend on your data science team.
Once you cemented y and the metrics,
go for a data hunt,
find indicators in your data lake and elsewhere which are likely to correlate with your prediction target. In principle, you still don’t need a data scientist for this, the process should be driven by the CDO and the BU (after all, they know what information they use for their decisions, which is usually a great baseline). But it may help to have someone who knows what’s out there in terms of open and buyable data. Here you absolutely need to talk to IT to have an idea about what the operational costs will be when these indicators need to be collected real time. The data scientist needs this information. If storing a new feature on each client costs you 4TB a day, that single fact decides how the predictor will look like.
Now hire a data scientist, preferably one that can also develop production quality software. Make him
build the experimental setup and the baseline workflow
with a simple prediction and check whether it can be put into production. At this point you are ready for the full scale experimental data science loop which data scientists know how to handle. You may need a deep learning specialist, but it is likely that you can out- and crowdsource your first model, e.g., by doing a RAMP with us.
If you like what you read, follow me on Medium, LinkedIn, & Twitter.
Bio: Balázs Kégl is a senior research scientist at CNRS and head of the Center for Data Science of the Université Paris-Saclay. He is co-creator of RAMP (www.ramp.studio).
Original. Reposted with permission.
Related: