Essential Machine Learning Algorithms: A Beginner’s Guide
Machine Learning as a technology, ensures that our current gadgets and their software get smarter by the day. Here are the algorithms that you ought to know about to understand Machine Learning’s varied and extensive functionalities and their effectiveness.

When a machine makes a human-like decision, keeping in view the history and data patterns, there are several machine learning algorithms running in the background that are implementing these functionalities. Be it, apps searching for the appropriate user options as per user data history or a game of playing mind teasing chess, wherein the machine decides on each step to be taken.
Types of Machine Learning Algorithms
Machine Learning, as of now, is a fast-evolving field of Artificial Intelligence wherein machines think and take decisions like humans due to the implementation of Artificial Neural Networks or ANN’s that work on the lines of a human brain. They help customize and analyze user content and data, to decrease the overall requirement and app maintenance cost in the long run.
ANN’s include artificial neurons and nodes that form the three layers of Input, hidden layer as well as output layer. These layers together form the functionality of each Machine Learning Algorithm. Data is provided in the form of various input nodes to the input layer. Each of these nodes carries specific information. The input nodes are then multiplied with random weights and other requisite variables and finally calculated by adding in a bias. Finally, nonlinear functions, also known as activation functions, are applied to determine which neuron to fire. With millions of neurons and inputs to choose from; these algorithms mostly pertain to complex functionalities that require a certain amount of processing power for smooth output.
These are the major types of Machine Learning Algorithms:
Supervised Learning Algorithms
When the algorithm’s outcome type is known to the developer and he or she also explicitly labels the ‘data’ that is to be analyzed to reach the results. Supervised learning primarily scales the scope of data and helps software and hardware to make predictions of unavailable, future, or unseen data based on labeled sample data. Supervised Learning Algorithms are widely used for the classification of the type of data that is ‘input’ and for regression of the same into patterns that would eventually provide the output. For instance, the processes of price predictions and trends forecasting, etc. are taken care of by supervised ML algorithms.
Unsupervised Learning Algorithms
There is no defined output or input type or any specifically marked data for the algorithms to utilize under the purview of unsupervised machine learning algorithms. Their output and learning are not under the direct control of the developer. Their functionalities are used for exploring the structure of the information, extracting valuable insights, detecting patterns, and implementing this into its operation to increase efficiency. The fields of digital marketing and ad tech are known to aggressively use these ML algorithms to provide customized services to users.
Semi-supervised Learning Algorithms
They are somewhere in between the supervised and unsupervised lead learning algorithms, wherein a designated set of output from a designated data is used to further ‘train’ an algorithm to label unlabeled data and then columbine the two. Several legal and healthcare industries are known to successfully use semi-supervised algorithms to manage their web content classification, image, and speech analysis with the help of semi-supervised learning, etc.
Reinforcement learning Algorithms
When a system reinforces the learnings of a previously analyzed output onto its newer analysis, it is a reinforcement algorithm. It includes mostly all AI-based functionalities wherein algorithms learn on their own and get smarter with usage. Herein the developer tries to develop a self-sustained system that, throughout contiguous sequences of tries and fails, improves itself based on the combination of labeled data and interactions with the incoming data. Self-driving cars and modern video games are all examples of Reinforcement based ML algorithms.
ML Algorithms You Should Know About
Let us now analyze the functionalities of specific ML algorithms that are touted to become famous in the times to come:
Linear Regression
Linear Regression Algorithms are employed by machines to analyze data and predict its outcomes following a particle equation with particular kinds of input variables leading to the formation of a particular ‘visual slope’ for accurate predictions. They have supervised learning algorithms and simple versions generally are based upon equations to the tune of:
wherein, x and y are the input and output variables, respectively. In the case of multi-variable scenarios, equations like:
wherein x, y, and z represent attributes of a function to be analyzed and predicted.
Logistic Regression
These are also supervised learning algorithms that utilize the concepts of predictive analytics to classify problems to find solutions. It is utilized by businesses to help predict the probability of an event by fitting data to a logit function. It is thus also called logit regression and basically inculcates a complex ‘cost function’ utility (essentially limited between 0 and 1) in the linear regression-based algorithms (mentioned above). It tends to develop as a Sigmoid Function’ that effectively predicts values as per probabilities.
Naive Bayes
It is a fast-working supervised learning algorithm that assumes that the occurrence of a certain feature is independent of the occurrence of other features and that the output value of such function can be calculated using the Bayes theorem:
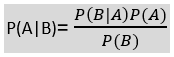
Famously used in text classifications within spam filtration, Sentimental analysis, and classifying articles related algorithms; Naive Bayes is a probabilistic classifier, which means it predicts based on the probability of an object.
K-Nearest Neighbor (K-NN)
The K-NN algorithm analyzes the similarities between the new case or data and the earlier available cases and puts the new case into the category that is most similar to the already available categories. In the training phase, it just stores the earlier available dataset and when it gets new data, then it classifies that data into a category that is much similar to the new data. It is an easy-to-use supervised learning algorithm that is mostly used for resolving classification problems including classification of images for image search, etc.
K-means Clustering
K-means clustering is a simple unsupervised machine learning algorithm that effectively clusters data based on some similarities (data points) and tries analyzing any and all data patterns. To achieve this objective, K-means looks for a fixed number (k) of clusters in a dataset and the term ‘mean’ implies a calculation of averages around the available datasets.
The Road Ahead...
Machine Learning, as a technology, has been taking shape and giving shape to other technologies; all around us. There are several other algorithms, apart from those stated above that help meet these criteria and utilities. But, they cannot be included in your digital assets through simple, widely available DIY websites or platforms. In order to inculcate these functionalities, you would have to hire a dedicated mobile app developer with appropriate expertise and experience in this field! You also need to know the estimated time and cost of the ML Project to have a smooth development and delivery process.
Ria Katiyar is a Content contributor who loves to write her understanding and knowledge in a simplified and engaging manner. She is an early adopter, likes to stay up to date with the latest trends & technologies.