The 10 Algorithms Machine Learning Engineers Need to Know
The 10 Algorithms Machine Learning Engineers Need to Know
 The 10 Algorithms Machine Learning Engineers Need to Know
The 10 Algorithms Machine Learning Engineers Need to KnowRead this introductory list of contemporary machine learning algorithms of importance that every engineer should understand.

It is no doubt that the sub-field of machine learning / artificial intelligence has increasingly gained more popularity in the past couple of years. As Big Data is the hottest trend in the tech industry at the moment, machine learning is incredibly powerful to make predictions or calculated suggestions based on large amounts of data.
Some of the most common examples of machine learning are Netflix’s ML algorithms to make movie suggestions based on movies you have watched in the past, or Amazon’s ML algorithms that recommend books based on books you have bought before.
Getting Started With Machine Learning Algorithms
So if you want to learn more about machine learning, how do you start? For me, my first introduction is when I took an Artificial Intelligence class when I was studying abroad in Copenhagen.
My lecturer is a full-time Applied Math and CS professor at the Technical University of Denmark, in which his research areas are logic and artificial, focusing primarily on the use of logic to model human-like planning, reasoning and problem solving.
The class was a mix of discussion of theory/core concepts and hands-on problem solving. The textbook that we used is one of the AI classics: Peter Norvig’s Artificial Intelligence — A Modern Approach, in which we covered major topics including intelligent agents, problem-solving by searching, adversarial search, probability theory, multi-agent systems, social AI, philosophy/ethics/future of AI.
At the end of the class, in a team of 3, we implemented simple search-based agents solving transportation tasks in a virtual environment as a programming project.
I have learned a tremendous amount of knowledge thanks to that class, and decided to keep learning about this specialized topic. In the last few weeks, I have been multiple tech talks in San Francisco on deep learning, neural networks, data architecture — and a Machine Learning conference with a lot of well-known professionals in the field.
Most importantly, I enrolled in Udacity’s Intro to Machine Learning online course in the beginning of June and has just finished it a few days ago. In this post, I want to share some of the most common machine learning algorithms that I learned from the course.
The 3 Types of Machine Learning / AI Algorithms
ML / AI algorithms can be divided into 3 broad categories — supervised learning, unsupervised learning, and reinforcement learning.
- Supervised learning is useful in cases where a property (label) is available for a certain dataset (training set), but is missing and needs to be predicted for other instances.
- Unsupervised learning is useful in cases where the challenge is to discover implicit relationships in a given unlabeled dataset (items are not pre-assigned).
- Reinforcement learning falls between these 2 extremes — there is some form of feedback available for each predictive step or action, but no precise label or error message. Since this is an intro class, I didn’t learn about reinforcement learning, but I hope that 10 algorithms on supervised and unsupervised learning will be enough to keep you interested.
Supervised Learning Algorithms
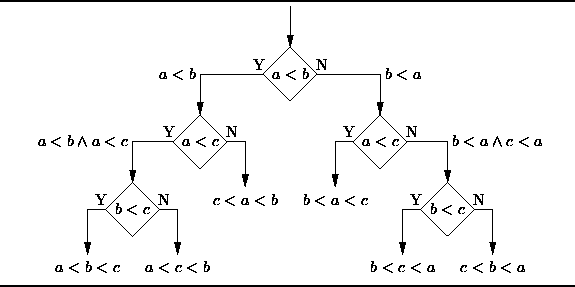
1. Decision Trees:
A decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences, including chance-event outcomes, resource costs, and utility. Take a look at the image to get a sense of how it looks like.
2. Naive Bayes Classification:
Naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes’ theorem with strong (naive) independence assumptions between the features. The featured image is the equation — with P(A|B) is posterior probability, P(B|A) is likelihood, P(A) is class prior probability, and P(B) is predictor prior probability.
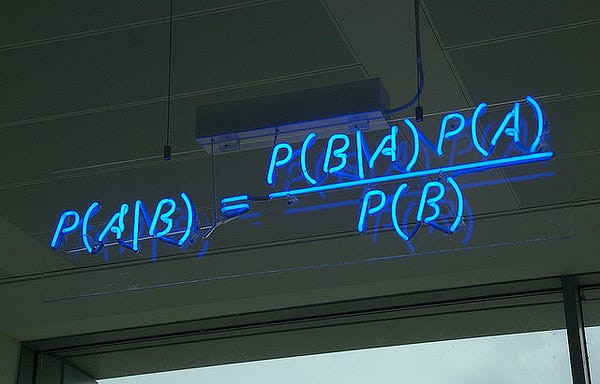
- To mark an email as spam or not spam
- Classify a news article about technology, politics, or sports
- Check a piece of text expressing positive emotions, or negative emotions?
- Used for face recognition software.
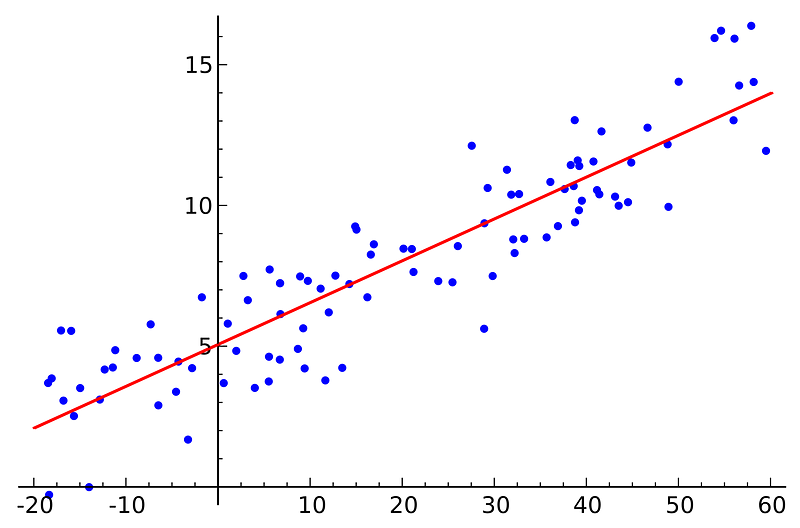
3. Ordinary Least Squares Regression:
If you know statistics, you probably have heard of linear regression before. Least squares is a method for performing linear regression. You can think of linear regression as the task of fitting a straight line through a set of points. There are multiple possible strategies to do this, and “ordinary least squares” strategy go like this — You can draw a line, and then for each of the data points, measure the vertical distance between the point and the line, and add these up; the fitted line would be the one where this sum of distances is as small as possible.
4. Logistic Regression:
Logistic regression is a powerful statistical way of modeling a binomial outcome with one or more explanatory variables. It measures the relationship between the categorical dependent variable and one or more independent variables by estimating probabilities using a logistic function, which is the cumulative logistic distribution.
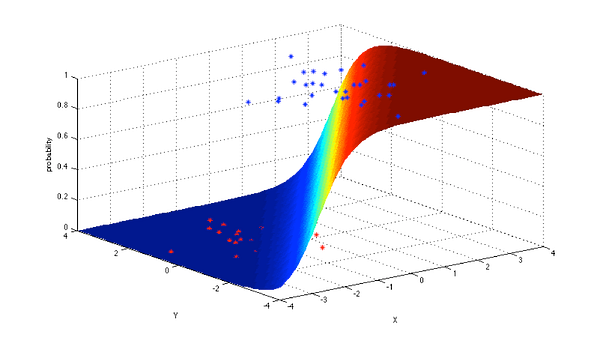
- Credit Scoring
- Measuring the success rates of marketing campaigns
- Predicting the revenues of a certain product
- Is there going to be an earthquake on a particular day?
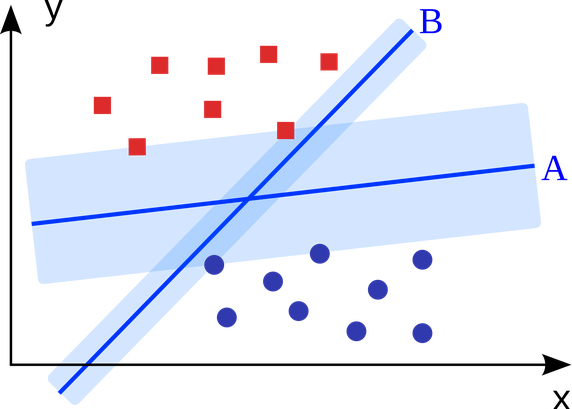
5. Support Vector Machines:
SVM is binary classification ML algorithm. Given a set of points of 2 types in N dimensional place, SVM generates a (N — 1) dimensional hyperplane to separate those points into 2 groups. Say you have some points of 2 types in a paper which are linearly separable. SVM will find a straight line which separates those points into 2 types and situated as far as possible from all those points.