 Pandas not enough? Here are a few good alternatives to processing larger and faster data in Python
Pandas not enough? Here are a few good alternatives to processing larger and faster data in Python

 Pandas not enough? Here are a few good alternatives to processing larger and faster data in Python
Pandas not enough? Here are a few good alternatives to processing larger and faster data in PythonWhile the Pandas library remains a crucial workhorse in data processing and management for data science, some limitations exist that can impact efficiencies, especially with very large data sets. Here, a few interesting alternatives to Pandas are introduced to improve your large data handling performance.
By DaurEd, providing quality and affordable education.

Data is found everywhere in various formats of CSVs, flat files, JSON, etc. When the data size is large, it’s difficult to read into memory and time-consuming for EDA (exploratory data analysis). This blog revolves around handling tabular data in CSV format and processing it with Pandas and some alternatives like cuDF, dask, modin, and datatable.
Problem: Importing (reading) a large CSV file leads to an Out of Memory error. Not enough RAM to read the entire CSV at once crashes the computer often. And processing it is slower at times with a single CPU core.
About the data used in this exploration: A sales data record of 5 million rows and 14 columns as shown below. This dataset is in zip format can be found at:
First 5 rows of the data:

Pandas is designed to work only on a single core, so cannot utilize the multi-cores available on your system.
However, the cuDF library aims to implement the Pandas API on GPUs. Modin and the Dask Dataframe library provide parallel algorithms around the Pandas API.
Modin is targeted toward parallelizing the entire pandas API, without exception. This implies all pandas functions can be used on Modin, which happens just by changing one line in code: import modin.pandas as pd (Check the code in git link below to learn about the implementation)
Dask is currently missing multiple APIs from pandas that Modin has implemented.
To learn how to control the number of processors that Modin uses by parameter num_cpus, check out:
https://github.com/Piyush-Kulkarni/ByeByePandas.git
On the Windows platform, you can check the number of cores on your system in Task Manager > Performance.
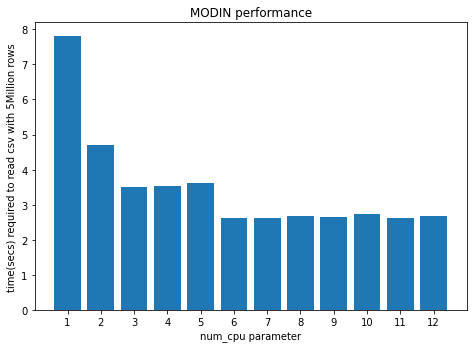
Using num_cpu higher than the cores available on your system wouldn’t improve the performance. Rather, it might end up lowering it. In my case, beyond the 6 cores available on my system, the performance degrades slightly, as shown in the above plot.
Original. Reposted with permission.
Related: