Make Pandas 3 Times Faster with PyPolars
Learn how to speed up your Pandas workflow using the PyPolars library.
By Satyam Kumar, Machine Learning Enthusiast & Programmer

Photo by Tim Gouw on Unsplash
Pandas is one of the most important Python packages among data scientist’s to play around with the data. Pandas library is used mostly for data explorations and visualizations as it comes with tons of inbuilt functions. Pandas fail to handle large size datasets as it does not scale or distributes its process across all the cores of the CPU.
To speed up the computations, one can utilize all the cores of the CPU and speed up the workflow. There are various open-source libraries including Dask, Vaex, Modin, Pandarallel, PyPolars, etc that parallelize the computations across multiple cores of the CPU. In this article, we will discuss the implementation and usage of the PyPolars library and compare its performance with Pandas library.
Whats is PyPolars?
PyPolars is an open-source Python data frame library similar to Pandas. PyPolars utilizes all the available cores of the CPU and hence performs the computations faster than Pandas. PyPolars has an API similar to that of Pandas. It is written in rust with Python wrappers.
Ideally, PyPolars is used when the data is too big for Pandas and too small for Spark
How PyPolars Works?
PyPolars library has two APIs, one is Eager API and the other is Lazy API. Eager API is very similar to that of Pandas, and the results are produced just after the execution is completed similar to Pandas. Lazy API is very similar to Spark, where a map or plan is formed upon execution of a query. Then the execution is executed parallelly across all the cores of the CPU.

(Image by Author), PyPolars API’s
PyPolars is basically as python binding to Polars library. The best part of the PyPolars library is its API similarity to Pandas, which makes it easier for the developers.
Installation:
PyPolars can be installed from PyPl using the following command:
pip install py-polarsand import the library using
import pypolars as pl
Benchmark Time Constraints:
For demonstrations, I have used a large size dataset (~6.4Gb) having 25 million instances.
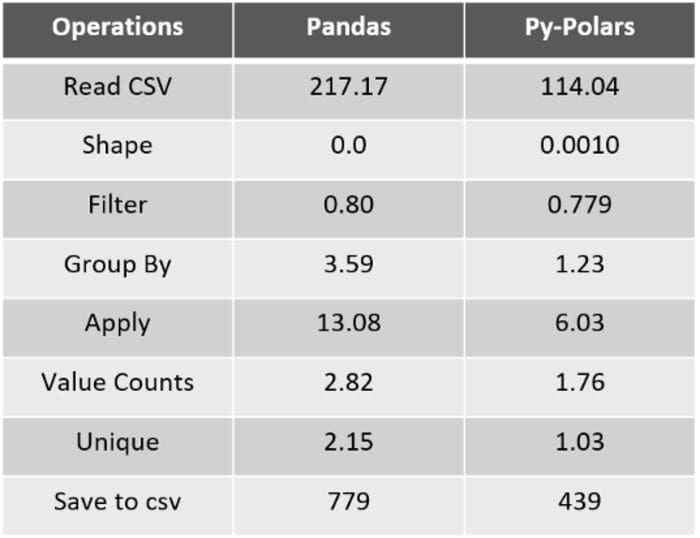
(Image by Author), Benchmark Time Number for Pandas and Py-Polars basic operations
For the above benchmark time numbers for some basic operations using Pandas and PyPolars library, we can observe that PyPolars is almost 2x to 3x faster than Pandas.
Now we know that PyPolars has an API very similar to that of Pandas, but still, it does not cover all the functions of Pandas. For example, we don’t have .describe() function in PyPolars, instead, we can use df_pypolars.to_pandas().describe()
Usage:
(Code by Author)
Conclusion:
In this article, we have covered a small introduction to the PyPolars library, including its implementation, usage, and comparing its benchmark time numbers with Pandas for some basic operations. Note that PyPolars works very similar to that of Pandas, and PyPolars is a memory-efficient library since the memory backed by it is immutable.
One can go through the documentation to get a detailed understanding of the library. There are various other open-source libraries that can parallelize the Pandas operations and speed up the process. Read the below-mentioned article to know 4 such libraries:
4 Libraries that can parallelize the existing Pandas ecosystem
Distribute Python workload by parallel processing using these frameworks
References:
[1] Polars Documentation and GitHub repository: https://github.com/ritchie46/polars
Thank You for Reading
Bio: Satyam Kumar is a Machine Learning Enthusiast & Programmer. Satyam writes about Data Science, and is a Top Writer in AI. He is seeking an challenging career with a organisation that provides an opportunity to capitalise on his technical skills and abilities.
Original. Reposted with permission.
Related:
- Vaex: Pandas but 1000x faster
- How to Speed Up Pandas with Modin
- How to Deal with Categorical Data for Machine Learning