How to Speed Up Pandas with Modin
The Modin library has the ability to scale your pandas workflows by changing one line of code and integration with the Python ecosystem and Ray clusters. This tutorial goes over how to get started with Modin and how it can speed up your pandas workflows.
By Michael Galarnyk, Developer Relations at Anyscale
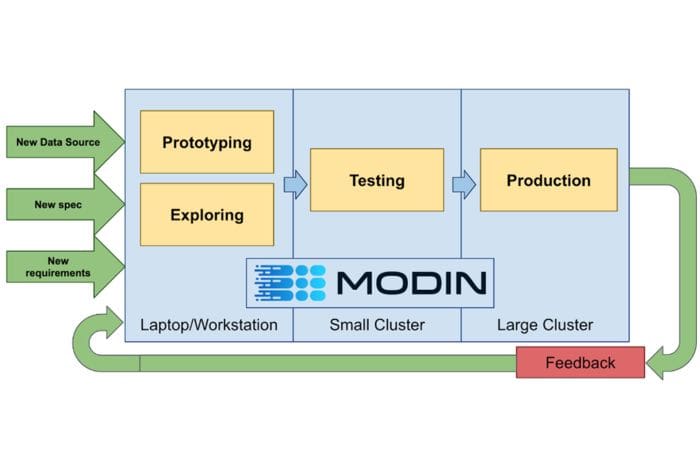
A goal of Modin is to allow data scientists to use the same code for small (kilobytes) and large datasets (terabytes). Image by Devin Petersohn.
The pandas library provides easy-to-use data structures like pandas DataFrames as well as tools for data analysis. One issue with pandas is that it can be slow with large amounts of data. It wasn’t designed for analyzing 100 GB or 1 TB datasets. Fortunately, there is the Modin library which has benefits like the ability to scale your pandas workflows by changing one line of code and integration with the Python ecosystem and Ray clusters. This tutorial goes over how to get started with Modin and how it can speed up your pandas workflows.
How to get started with Modin
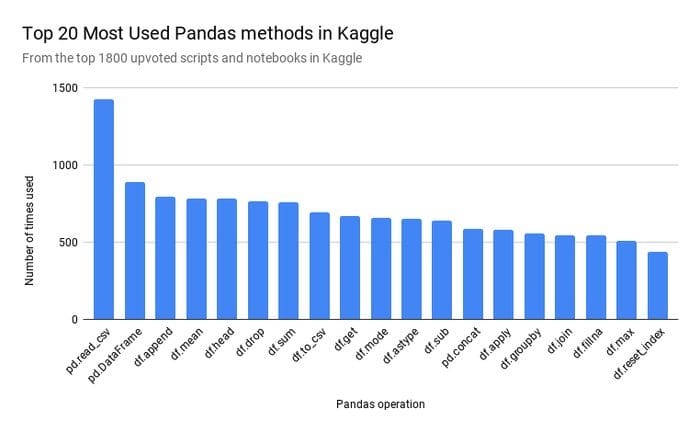
To determine which Pandas methods to implement in Modin first, the developers of Modin scraped 1800 of the most upvoted Python Kaggle Kernels (code).
Modin’s coverage of the pandas API is over 90% with a focus on the most commonly used pandas methods like pd.read_csv, pd.DataFrame, df.fillna, and df.groupby. This means if you have a lot of data, you can perform most of the same operations as the pandas library faster. This section highlights some commonly used operations.
To get started, you need to install modin.
pip install “modin[all]” # Install Modin dependencies and modin’s execution engines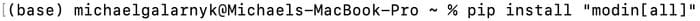
Don’t forgot the “” when pip installing
Import Modin
A major advantage of Modin is that it doesn’t require you to learn a new API. You only need to change your import statement.
import modin.pandas as pd
You only need to change your import statement to use Modin.
Load data (read_csv)

Modin really shines with larger datasets (image source)
The dataset used in this tutorial is from the Health Insurance Marketplace dataset which is around 2GB .The code below reads the data into a Modin DataFrame.
modin_df = pd.read_csv("Rate.csv”)
In this case, Modin is faster due to it taking work off the main thread to be asynchronous. The file was read in-parallel. A large portion of the improvement was from building the DataFrame components asynchronously.
head
The code below utilizes the head command.
# Select top N number of records (default = 5)
modin_df.head()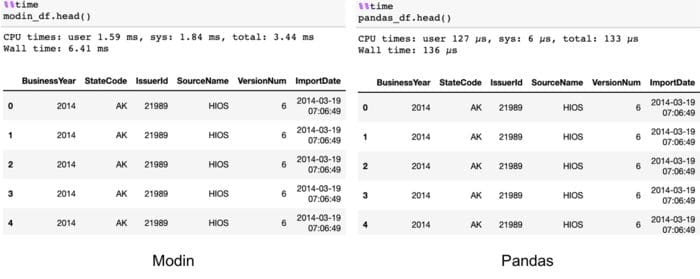
In this case, Modin is slower as it requires collecting the data together. However, users should not be able to perceive this difference in their interactive workflow.
groupby
Similar to pandas, modin has a groupby operation.
df.groupby(['StateCode’]).count()
Note that there are plans to further optimize the performance of groupby operations in Modin.
fillna
Filling in missing values with the fillna method can be much faster with Modin.
modin_df.fillna({‘IndividualTobaccoRate’: ‘Unknown’})
Default to pandas implementation
As mentioned earlier, Modin’s API covers about 90% of the Pandas API. For methods not covered yet, Modin will default to a pandas implementation like in the code below.
modin_df.corr(method = ‘kendall’)
When Modin defaults to pandas, you will see a warning.
While there is a performance penalty for defaulting to pandas, Modin will complete all operations whether or not the command is currently implemented in Modin.

If a method is not implemented, it will default to pandas.
Modin’s documentation explains how this process works.
We first convert to a pandas DataFrame, then perform the operation. There is a performance penalty for going from a partitioned Modin DataFrame to pandas because of the communication cost and single-threaded nature of pandas. Once the pandas operation has completed, we convert the DataFrame back into a partitioned Modin DataFrame. This way, operations performed after something defaults to pandas will be optimized with Modin.
How Modin can Speed up your Pandas Workflows
The three main ways modin makes pandas workflows faster are through it’s multicore/multinode support, system architecture, and ease of use.
Multicore/Multinode Support
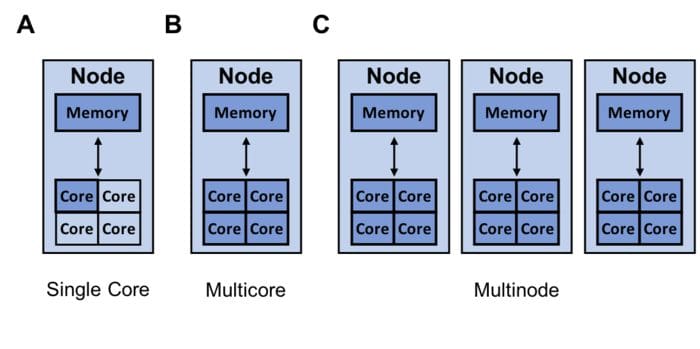
Pandas can only utilize a single core. Modin is able to efficiently make use of all of the hardware available to it. The image shows resources (dark blue) that Modin can utilize with multiple cores (B) and multiple nodes available (C).
The pandas library can only utilize a single core. As virtually all computers today have multiple cores, there is a lot of opportunity to speed up your pandas workflow by having modin utilize all the cores on your computer.
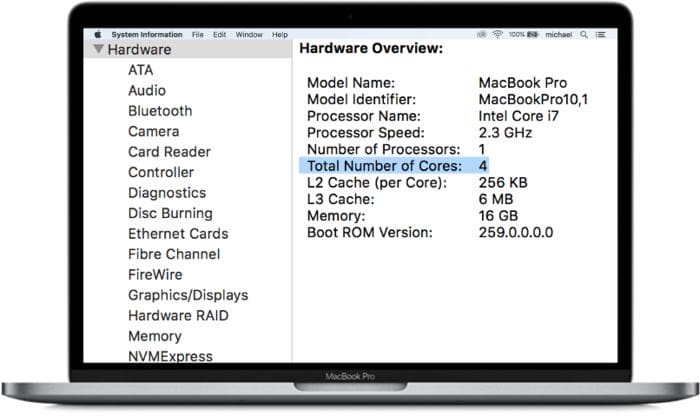
For the purpose of this blog, you can think of the MacBook above as a single node with 4 cores.
If you would like to scale your code to more than 1 node, Modin has an API for switching between running code locally and on cloud providers/clusters.
System Architecture
Another way Modin can be faster than pandas is due to how pandas itself was implemented. Wes McKinney, the creator of pandas, gave a famous talk “10 Things I Hate about Pandas” where he went over some pandas’ lack of flexibility and performance issues.

Some of Wes McKinney’s issues with pandas are performance related.
Modin endeavors to solve some of these issues. To understand how, it’s important to understand some of its system architecture. The diagram below outlines the general layered view to the components of Modin with a short description of each major section.

Modin’s System Architecture
APIs layer: This is the user facing layer which primarily is Modin’s coverage of the pandas API. The SQLite API is experimental and the Modin API is something still being designed.
Modin Query Compiler: In addition to its other duties, the Query Compiler layer closely follows the pandas API, but cuts out a large majority of the repetition.
Modin DataFrame layer: This is where Modin’s optimized dataframe algebra takes place.
Execution: While Modin also supports other execution engines like Dask, the most commonly used execution engine is Ray which you can learn about in the next section.
What is Ray

Ray makes parallel and distributed processing work more like you would hope (image source).
Ray is the default execution engine for Modin. This section briefly goes over what Ray is and how it can be used as more than just a execution engine.
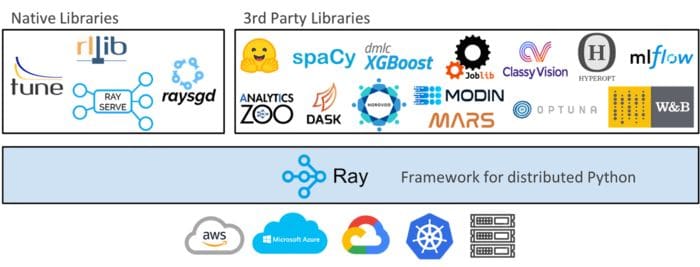
The diagram above shows that at a high level, the Ray ecosystem consists of the core Ray system and scalable libraries for data science like Modin. It is a library for scaling up Python applications across multiple cores or machines. It has a couple major advantages including:
- Simplicity: you can scale your Python applications without rewriting them, and the same code can run on one machine or multiple machines.
- Robustness: applications gracefully handle machine failures and preemption.
- Performance: tasks run with millisecond latencies, scale to tens of thousands of cores, and handle numerical data with minimal serialization overhead.
Because Ray is a general-purpose framework, the community has built many libraries and frameworks on top of it to accomplish different tasks like Ray Tune for hyperparameter tuning at any scale, Ray Serve for easy-to-use scalable model serving, and RLlib for reinforcement learning. It also has integrations for machine learning libraries like scikit-learn as well as support for data processing libraries such as PySpark and Dask.
While you don’t need to learn how to use Ray to use Modin, the image below shows that it generally only requires adding a couple lines of code to turn a simple Python program into a distributed one running across a compute cluster.

Example of how to turn a simple program into a distributed one using Ray (code explanation).
Conclusion
A goal of Modin is to allow data scientists to use the same code for small (kilobytes) and large datasets (terabytes). Image from Devin Petersohn.
Modin allows you to use the same Pandas script for a 10KB dataset on a laptop as well as a 10TB dataset on a cluster. This is possible due to Modin’s easy to use API and system architecture. This architecture can utilize Ray as an execution engine to make scaling Modin easier. If you have any questions or thoughts about Ray, please feel free to join our community through Discourse or Slack.
Bio: Michael Galarnyk works in Developer Relations at Anyscale, the company behind the Ray Project. You can find him on Twitter, Medium, and GitHub.
Original. Reposted with permission.
Related:
- Getting Started with Distributed Machine Learning with PyTorch and Ray
- Train sklearn 100x Faster
- How to Speed up Scikit-Learn Model Training