Getting Started with Distributed Machine Learning with PyTorch and Ray
Ray is a popular framework for distributed Python that can be paired with PyTorch to rapidly scale machine learning applications.
By Michael Galarnyk, Richard Liaw, and Robert Nishihara

Machine learning today requires distributed computing. Whether you’re training networks, tuning hyperparameters, serving models, or processing data, machine learning is computationally intensive and can be prohibitively slow without access to a cluster. Ray is a popular framework for distributed Python that can be paired with PyTorch to rapidly scale machine learning applications.
This post covers various elements of the Ray ecosystem and how it can be used with PyTorch!
What is Ray
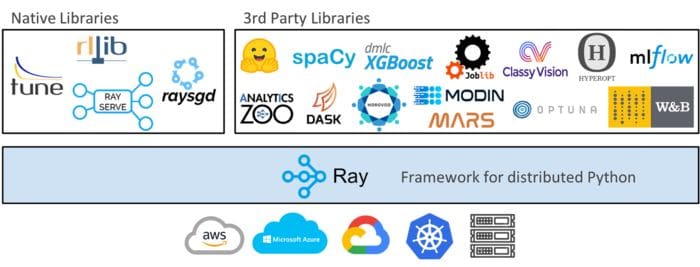
Ray is an open source library for parallel and distributed Python. The diagram above shows that at a high level, the Ray ecosystem consists of three parts: the core Ray system, scalable libraries for machine learning (both native and third party), and tools for launching clusters on any cluster or cloud provider.
The Core Ray System
Ray can be used to scale Python applications across multiple cores or machines. It has a couple major advantages including:
- Simplicity: you can scale your Python applications without rewriting them, and the same code can run on one machine or multiple machines.
- Robustness: applications gracefully handle machine failures and preemption.
- Performance: tasks run with millisecond latencies, scale to tens of thousands of cores, and handle numerical data with minimal serialization overhead.
Library Ecosystem
Because Ray is a general-purpose framework, the community has built many libraries and frameworks on top of it to accomplish different tasks. The vast majority of these support PyTorch, require minimal modifications to your code, and integrate seamlessly with each other. Below are just a few of the many libraries in the ecosystem.
RaySGD

Comparison of PyTorch’s DataParallel vs Ray (which uses PyTorch’s Distributed DataParallel underneath the hood) on p3dn.24xlarge instances. Image source.
RaySGD is a library that provides distributed training wrappers for data parallel training. For example, the RaySGD TorchTrainer is a wrapper around torch.distributed.launch. It provides a Python API to easily incorporate distributed training into a larger Python application, as opposed to needing to wrap your training code in bash scripts.
Some other advantages of the library are:
- Ease of use: You can scale PyTorch’s native DistributedDataParallel without needing to monitor individual nodes.
- Scalability: You can scale up and down. Start on a single CPU. Scale up to multi-node, multi-CPU, or multi-GPU clusters by changing 2 lines of code.
- Accelerated Training: There is built-in support for mixed precision training with NVIDIA Apex.
- Fault Tolerance: There is support for automatic recovery when cloud machines are preempted.
- Compatibility: There is seamless integration with other libraries like Ray Tune and Ray Serve.
You can get started with TorchTrainer by installing Ray (pip install -U ray torch) and running the code below:
The script will download CIFAR10 and use a ResNet18 model to do image classification. With a single parameter change (num_workers=N), you can utilize multiple GPUs.
If you would like to learn more about RaySGD and how to scale PyTorch training across a cluster, you should check out this blog post.
Ray Tune
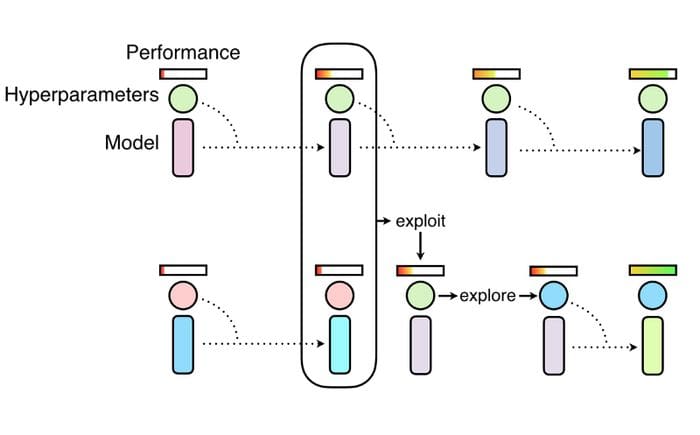
Ray Tune’s implementation of optimization algorithms like Population Based Training (shown above) can be used with PyTorch for more performant models. Image from Deepmind.
Ray Tune is a Python library for experiment execution and hyperparameter tuning at any scale. Some advantages of the library are:
- The ability to launch a multi-node distributed hyperparameter sweep in fewer than 10 lines of code.
- Support for every major machine learning framework including PyTorch.
- First-class support for GPUs.
- Automatic management of checkpoints and logging to TensorBoard.
- Access to state of the art algorithms such as Population Based Training (PBT), BayesOptSearch, HyperBand/ASHA.
You can get started with Ray Tune by installing Ray (pip install ray torch torchvision) and running the code below.
If you would like to learn about how to incorporate Ray Tune into your PyTorch workflow, you should check out this blog post.
Ray Serve
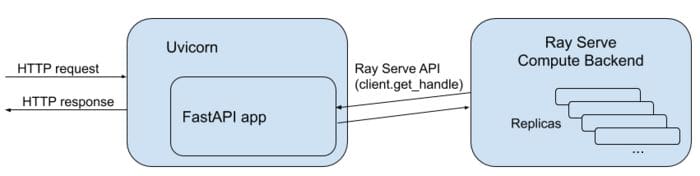
Ray Serve can not only be used to serve models on its own, but also to scale other serving tools like FastAPI.
Ray Serve is a library for easy-to-use scalable model serving. Some advantages of the library are:
- The ability to use a single toolkit to serve everything from deep learning models (PyTorch, TensorFlow, etc) to scikit-learn models, to arbitrary Python business logic.
- Scale to many machines, both in your datacenter and in the cloud.
- Compatibility with many other libraries like Ray Tune and FastAPI.
If you would like to learn how to incorporate Ray Serve and Ray Tune together into your PyTorch workflow, you should check out the documentation for a full code example.
RLlib
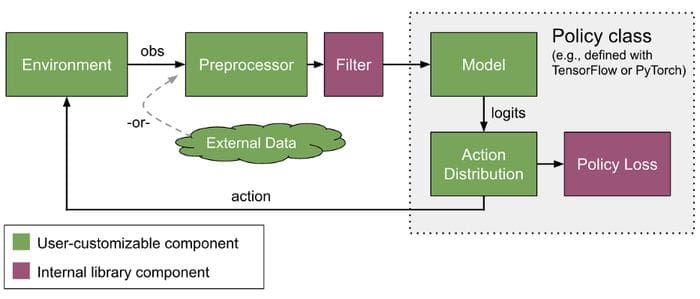
RLlib provides ways to customize almost all aspects of training, including neural network models, action distributions, policy definitions, environments, and the sample collection process.
RLlib is a library for reinforcement learning that offers both high scalability and a unified API for a variety of applications. Some advantages include:
- Native support for PyTorch, TensorFlow Eager, and TensorFlow (1.x and 2.x).
- Support for model-free, model-based, evolutionary, planning, and multi-agent algorithms
- Support for complex model types, such as attention nets and LSTM stacks via simple config flags and auto-wrappers
- Compatibility with other libraries like Ray Tune.
Cluster Launcher
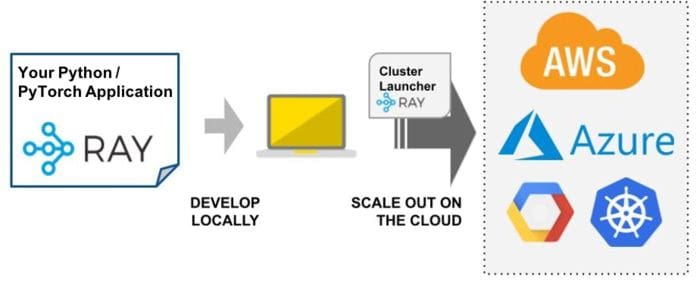
The Ray Cluster Launcher simplifies the process of launching and scaling across any cluster or cloud provider.
Once you have developed an application on your laptop and want to scale it up to the cloud (perhaps with more data or more GPUs), the next steps aren’t always clear. The process is either to have an infrastructure team set it up for you or to go through the following steps.
1. Choose a cloud provider (AWS, GCP, or Azure).
2. Navigate the management console to set instance types, security groups, spot prices, instance limits, and more.
3. Figure out how to distribute your Python script across a cluster.
An easier approach is to use the Ray Cluster Launcher to launch and scale machines across any cluster or cloud provider. Cluster Launcher allows you autoscale, sync files, submit scripts, port forward, and more. This means that you can run your Ray clusters on Kubernetes, AWS, GCP, Azure, or a private cluster without needing to understand the low-level details of cluster management.
Conclusion
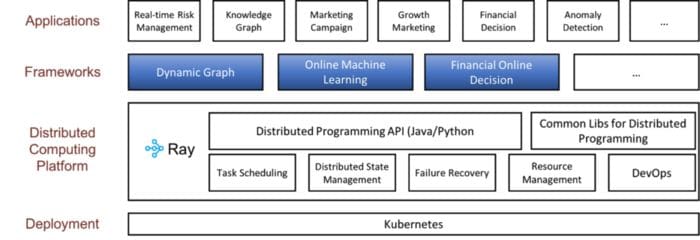
Ray provides a distributed computing foundation for Ant Group’s Fusion Engine.
This article contained some of the benefits of Ray in the PyTorch ecosystem. Ray is being used for a wide variety of applications from Ant Group using Ray to support its financial business, to LinkedIn running Ray on Yarn, to Pathmind using Ray to connect reinforcement learning to simulation software, and more. If you have any questions or thoughts about Ray or want to learn more about parallel and distributed Python, please join our community through Discourse or Slack.
Original. Reposted with permission.
Related:
- How to Speed up Scikit-Learn Model Training
- Train sklearn 100x Faster
- Computer Vision at Scale With Dask And PyTorch