Speech to Text with Wav2Vec 2.0
Facebook recently introduced and open-sourced their new framework for self-supervised learning of representations from raw audio data called Wav2Vec 2.0. Learn more about it and how to use it here.
By Dhilip Subramanian, Data Scientist and AI Enthusiast
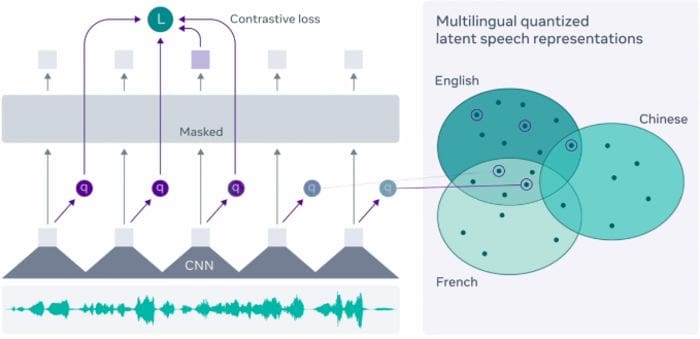
From Wav2vec 2.0: Learning the structure of speech from raw audio
In my previous blog, I explained how to convert speech into text using the Speech Recognition library with the help of Google speech recognition API. In this blog, we see how to convert speech into text using Facebook Wav2Vec 2.0 model.
Facebook recently introduced and open-sourced their new framework for self-supervised learning of representations from raw audio data called Wav2Vec 2.0. Facebook researchers claim this framework can enable automatic speech recognition models with just 10 minutes of transcribed speech data.
As everyone knows, Transformers are playing a major role in Natural Language Processing. The latest version of Hugging Face transformers is version 4.30 and it comes with Wav2Vec 2.0. This is the first Automatic Speech recognition speech model included in the Transformers.
Model Architecture is beyond the scope of this blog. For detailed Wav2Vec model architecture, please check here.
Let’s see how we can convert the audio file into text using Hugging Face transformers with some simple lines of code.
Installing Transformer library
# Installing Transformer !pip install -q transformers
Importing necessary libraries
# Import necessary library # For managing audio file import librosa #Importing Pytorch import torch #Importing Wav2Vec from transformers import Wav2Vec2ForCTC, Wav2Vec2Tokenizer
Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using Wav2Vec2Tokenizer (Ref: Hugging Face)
Reading the audio file
I have used Liam Neeson famous dialogue audio clip from the movie “Taken” in this example which says “I will look for you, I will find you and I will kill you”
Please note the Wav2Vec model is pre-trained on 16 kHz frequency, so we make sure our raw audio file is also resampled to a 16 kHz sampling rate. I have used online audio tool conversion to resample the ‘taken’ audio clip into 16kHz.
Loading the audio file using the librosa library and mentioning my audio clip size is 16000 Hz. It converts the audio clip into an array and is stored into the ‘audio’ variable.
# Loading the audio file
audio, rate = librosa.load("taken_clip.wav", sr = 16000)
# printing audio print(audio) array([0., 0., 0., ..., 0., 0., 0.], dtype=float32)
# printing rate print(rate) 16000
Importing pre-trained Wav2Vec model
# Importing Wav2Vec pretrained model
tokenizer = Wav2Vec2Tokenizer.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
The next step is taking the input values, passing the audio (array) into tokenizer and we want our tensors in PyTorch format instead of Python integers. return_tensors = “pt” which is nothing more than PyTorch format.
# Taking an input value input_values = tokenizer(audio, return_tensors = "pt").input_values
Getting the logit values (non-normalized values)
# Storing logits (non-normalized prediction values) logits = model(input_values).logits
Passing the logit values to softmax to get the predicted values
# Storing predicted ids prediction = torch.argmax(logits, dim = -1)
Converting audio to text
The final step is to pass the prediction to the tokenizer decode to get the transcription
# Passing the prediction to the tokenzer decode to get the transcription transcription = tokenizer.batch_decode(prediction)[0]
# Printing the transcription print(transcription) 'I WILL LOOK FOR YOU I WILL FIND YOU AND I WILL KILL YOU'
It exactly matches our audio clip.
In this blog, we have seen how to convert speech into text using Wav2Vec pretrained model using Transformers. This would be very helpful for NLP projects especially handling audio transcripts data. If you have anything to add, please feel free to leave a comment!
You can find the entire code and data in my GitHub repo.
Thanks for reading. Keep learning and stay tuned for more!
Reference
- https://huggingface.co/transformers/model_doc/wav2vec2.html
- https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/
Bio: Dhilip Subramanian is a Mechanical Engineer and has completed his Master's in Analytics. He has 9 years of experience with specialization in various domains related to data including IT, marketing, banking, power, and manufacturing. He is passionate about NLP and machine learning. He is a contributor to the SAS community and loves to write technical articles on various aspects of data science on the Medium platform.
Original. Reposted with permission.
Related:
- Easy Speech-to-Text with Python
- Getting Started with 5 Essential Natural Language Processing Libraries
- Hugging Face Transformers Package – What Is It and How To Use It