 Getting Started with 5 Essential Natural Language Processing Libraries
Getting Started with 5 Essential Natural Language Processing Libraries
 Getting Started with 5 Essential Natural Language Processing Libraries
Getting Started with 5 Essential Natural Language Processing LibrariesThis article is an overview of how to get started with 5 popular Python NLP libraries, from those for linguistic data visualization, to data preprocessing, to multi-task functionality, to state of the art language modeling, and beyond.
Let's say that you have an understanding of how to tackle natural language processing tasks. Let's also say that you have decided, more specifically, the type of approach you will employ in attempting to solve your task. You still need to put your plan into action, computationally, and there is a good chance you will be looking to leverage an existing NLP library to help you do so.
Assuming you are programming in Python (I can't help you if not), there is quite a landscape of options to choose from. While this article is not an endorsement of any particular collection of such solutions, it serves as an overview to a curated list of 5 popular libraries you may look to in order to work on your problems.

1. Hugging Face Datasets
Hugging Face's Datasets library is, in essence, a packaged collection of publicly-available NLP datasets with a common set of APIs and data formats, as well as some ancillary functionality.
The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools.
One can easily install Datasets with:
pip install datasets
Datasets is further described as providing two main features: one-line dataloaders for many public datasets, and efficient data pre-processing. This description glosses over another major piece of the library, however: a number of built-in evaluation metrics relevant to NLP tasks. The library also has additional features such as back-end memory management of datasets and interoperability with popular Python tools such as NumPy, Pandas, along with major machine learning platforms TensorFlow and PyTorch.
Let's first look at loading a dataset:
from datasets import load_dataset, list_datasets
print(f"The Hugging Face datasets library contains {len(list_datasets())} datasets")
squad_dataset = load_dataset('squad')
print(squad_dataset['train'][0])
print(squad_dataset)
The Hugging Face datasets library contains 635 datasets
Reusing dataset squad (/home/matt/.cache/huggingface/datasets/squad/plain_text/1.0.0/4c81550d83a2ac7c7ce23783bd8ff36642800e6633c1f18417fb58c3ff50cdd7)
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']}, 'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.', 'id': '5733be284776f41900661182', 'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?', 'title': 'University_of_Notre_Dame'}
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 87599
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 10570
})
})
Loading a metric is just as straightforward:
from datasets import load_metric, list_metrics
print(f"The Hugging Face datasets library contains {len(list_metrics())} metrics")
print(f"Available metrics are: {list_metrics()}")
# Load a metric
squad_metric = load_metric('squad')
The Hugging Face datasets library contains 19 metrics Available metrics are: ['accuracy', 'bertscore', 'bleu', 'bleurt', 'comet', 'coval', 'f1', 'gleu', 'glue', 'indic_glue', 'meteor', 'precision', 'recall', 'rouge', 'sacrebleu', 'seqeval', 'squad', 'squad_v2', 'xnli']
What you do with them is up to you, but loading a publicly-accessible dataset and a tried and true evaluation metric has never been easier.
2. TextHero
TextHero is succinctly described in its Github repo as:
Text preprocessing, representation and visualization from zero to hero.
Though this does a fine job of explaining in a few words what you might use this library for, the following answer to the question of "why TextHero?" from the repo sheds a little more light as to the reasoning behind the library:
In a very pragmatic way, texthero has just one goal: make the developer spare time. Working with text data can be a pain and in most cases, a default pipeline can be quite good to start. There is always time to come back and improve previous work.
Now that you know why you might use TextHero, here's how to install it:
pip install texthero
A look at the getting started guide shows what you can accomplish in a few lines of code. With the below example from the TextHero Github repo, we will load a dataset, clean it, create a TF-IDF representation, perform principle component analysis, and plot the results of this PCA.
def text_texthero():
import texthero as hero
import pandas as pd
df = pd.read_csv("https://github.com/jbesomi/texthero/raw/master/dataset/bbcsport.csv")
df['pca'] = (
df['text']
.pipe(hero.clean)
.pipe(hero.tfidf)
.pipe(hero.pca)
)
hero.scatterplot(df, 'pca', color='topic', title="PCA BBC Sport news")
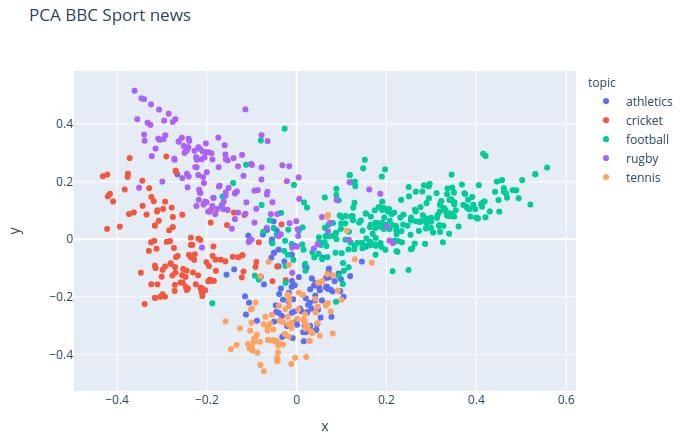
There is much more you can accomplish with TextHero, so check the rest of the documentation for info on data cleaning and preprocessing, visualization, representation, basic NLP tasks, and more.
3. spaCy
spaCy is specifically designed with the goal of being a useful library for implementing production-ready systems.
spaCy is designed to help you do real work — to build real products, or gather real insights. The library respects your time, and tries to avoid wasting it. It's easy to install, and its API is simple and productive. We like to think of spaCy as the Ruby on Rails of Natural Language Processing.
So when you are ready to get to doing some real work, you need to first install spaCy and at least one language model. In this example we will use its English language model. The installation of both the library and the language model can be accomplished with these lines:
pip install spacy
python -m spacy download en
To get started with spaCy, we will use this sentence of sample text:
sample = u"I can't imagine spending $3000 for a single bedroom apartment in N.Y.C."
Now let's import spaCy and a list of English stop words. We also load the English language model as a Language object (we will call it 'nlp' out of spaCy convention), and then call the nlp object on our sample text, which returns a processed Doc object (which we cleverly call 'doc').
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
nlp = spacy.load('en')
doc = nlp(sample)
So... that's it? From the spaCy documentation:
Even though a Doc is processed – e.g. split into individual words and annotated – it still holds all information of the original text, like whitespace characters. You can always get the offset of a token into the original string, or reconstruct the original by joining the tokens and their trailing whitespace. This way, you'll never lose any information when processing text with spaCy.
Now, let's have a look at that processed sample:
# Print out tokens
print("Tokens:\n=======)
for token in doc:
print(token)
# Identify stop words
print("Stop words:\n===========")
for word in doc:
if word.is_stop == True:
print(word)
# POS tagging
print("POS tagging:\n============")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
# Print out named entities
print("Named entities:\n===============")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
Tokens: ======= I ca n't imagine spending $ 3000 for a single bedroom apartment in N.Y.C. Stop words: =========== ca for a in POS tagging: ============ I -PRON- PRON PRP nsubj X True False ca can VERB MD aux xx True True n't not ADV RB neg x'x False False imagine imagine VERB VB ROOT xxxx True False spending spend VERB VBG xcomp xxxx True False $ $ SYM $ nmod $ False False 3000 3000 NUM CD dobj dddd False False for for ADP IN prep xxx True True a a DET DT det x True True single single ADJ JJ amod xxxx True False bedroom bedroom NOUN NN compound xxxx True False apartment apartment NOUN NN pobj xxxx True False in in ADP IN prep xx True True N.Y.C. n.y.c. PROPN NNP pobj X.X.X. False False Named entities: =============== 3000 26 30 MONEY N.Y.C. 65 71 GPE
spaCy is powerful, opinionated, and can be useful for a wide array of NLP tasks, from preprocessing, to representation, to modeling. Check out the spaCy documentation to see where you can go from here.
4. Hugging Face Transformers
It's hard to overstate how integral to the practice of NLP the Hugging Face Transformers library has become. By providing access to
The big picture, directly from the Github repo:
State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0
Transformers provides thousands of pretrained models to perform tasks on texts such as classification, information extraction, question answering, summarization, translation, text generation, etc in 100+ languages. Its aim is to make cutting-edge NLP easier to use for everyone.
Transformers provides APIs to quickly download and use those pretrained models on a given text, fine-tune them on your own datasets then share them with the community on our model hub. At the same time, each python module defining an architecture can be used as a standalone and modified to enable quick research experiments.
Transformers is backed by the two most popular deep learning libraries, PyTorch and TensorFlow, with a seamless integration between them, allowing you to train your models with one then load it for inference with the other.
You can test out the Transformer library online using Write With Transformer, the official demo of just what the library is capable of.
Installation of this complex library is simple:
pip install transformers
There is an awful lot to the Transformers library, and you could spend a lot of time learning all of its ins and outs. However, the inclusion of the pipeline API allows for the immediate use of a model out of the gate, with little configuration necessary. Here is an example of how to use a Transformers pipeline for classification (note that either TensorFlow or PyTorch should be installed to proceed):
from transformers import pipeline
# Allocate a pipeline for sentiment-analysis
classifier = pipeline('sentiment-analysis')
# Classify text
print(classifier('I am a fan of KDnuggets, its useful content, and its helpful editors!'))
[{'label': 'POSITIVE', 'score': 0.9954679012298584}]
Ridiculously, that's it. The pipeline uses a pre-trained model as well as the preprocessing used for that model, and even without fine-tuning the results can be quite compelling.
Here is a second pipeline example, this time for question answering:
from transformers import pipeline
# Allocate a pipeline for question-answering
question_answerer = pipeline('question-answering')
# Ask a question
answer = question_answerer({
'question': 'Where is KDnuggets headquartered?',
'context': 'KDnuggets was founded in February of 1997 by Gregory Piatetsky in Brookline, Massachusetts.'
})
# Print the answer
print(answer)
{'score': 0.9153624176979065, 'start': 66, 'end': 90, 'answer': 'Brookline, Massachusetts'}
A simple pair of examples, to be sure, but these pipelines are much more powerful than only being able to solve trivial KDnuggets-related tasks! You can read more about pipelines here.
Transformers makes state of the art models easy to use, and available to everyone. Visit the library's Github repo to start exploring more.
5. Scattertext
Scattertext is made for creating attractive visualizations depicting how language differs among document types. From its Github repo:
A tool for finding distinguishing terms in corpora, and presenting them in an interactive, HTML scatter plot. Points corresponding to terms are selectively labeled so that they don't overlap with other labels or points.
If you can't guess by now, installation is accomplished with:
pip install scattertext
The following example is from the Github repo, visualizing terms used at the 2012 US political conventions.
The 2,000 most party-associated unigrams are displayed as points in the scatter plot. Their x- and y- axes are the dense ranks of their usage by Republican and Democratic speakers respectively.
Note that running the example code produces an HTML file which can then be viewed and interacted with in your browser.
import scattertext as st
df = st.SampleCorpora.ConventionData2012.get_data().assign(
parse=lambda df: df.text.apply(st.whitespace_nlp_with_sentences)
)
corpus = st.CorpusFromParsedDocuments(
df, category_col='party', parsed_col='parse'
).build().get_unigram_corpus().compact(st.AssociationCompactor(2000))
html = st.produce_scattertext_explorer(
corpus,
category='democrat', category_name='Democratic', not_category_name='Republican',
minimum_term_frequency=0, pmi_threshold_coefficient=0,
width_in_pixels=1000, metadata=corpus.get_df()['speaker'],
transform=st.Scalers.dense_rank
)
open('./demo_compact.html', 'w').write(html)
The results of the saved HTML file, when viewed (not this is a static image shown below, and is therefore not interactive):
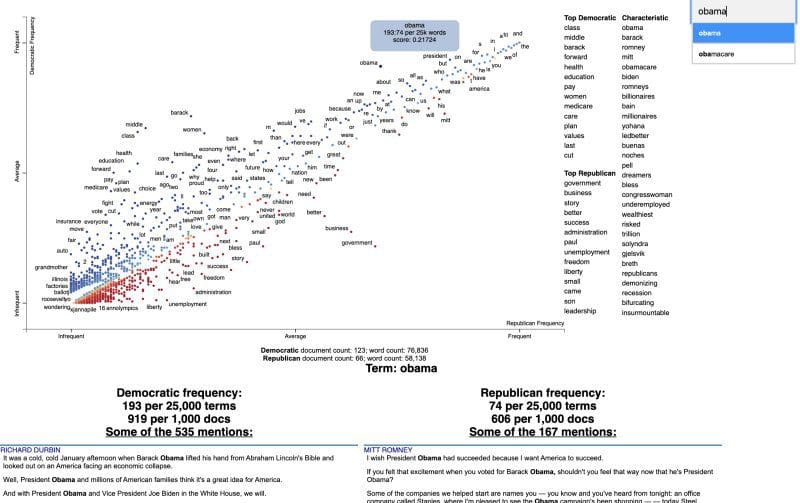
Scattertext serves a narrow and defined purpose, but does so very well. The visualizations are definitely beautiful, and, just as importantly, insightful. Visit their Github repository for more info and what else can be done with the library.
Related:
- Top Python Libraries for Deep Learning, Natural Language Processing & Computer Vision
- 5 Fantastic Natural Language Processing Books
- The Best NLP with Deep Learning Course is Free