 A Framework for Approaching Textual Data Science Tasks
A Framework for Approaching Textual Data Science Tasks
 A Framework for Approaching Textual Data Science Tasks
A Framework for Approaching Textual Data Science TasksAlthough NLP and text mining are not the same thing, they are closely related, deal with the same raw data type, and have some crossover in their uses. Let's discuss the steps in approaching these types of tasks.
There's an awful lot of text data available today, and enormous amounts of it are being created on a daily basis, ranging from structured to semi-structured to fully unstructured. What can we do with it? Well, quite a bit, actually; it depends on what your objectives are, but there are 2 intricately related yet differentiated umbrellas of tasks which can be exploited in order to leverage the availability of all of this data.
Text Mining or Natural Language Processing?
Natural language processing (NLP) concerns itself with the interaction between natural human languages and computing devices. NLP is a major aspect of computational linguistics, and also falls within the realms of computer science and artificial intelligence.
Text mining exists in a similar realm as NLP, in that it is concerned with identifying interesting, non-trivial patterns in textual data.
OK, great. But really, what is the difference?
First off, the exact boundaries of these 2 concepts are not well-defined and agreed-upon (see data mining vs. data science), and bleed into one another to varying degrees, depending on the practitioners and researchers with whom you discuss such matters. I find it easiest to differentiate by degree of insight. If raw text is data, then text mining is information and NLP is knowledge (see the Pyramid of Understanding below). Syntax versus semantics, if you will.
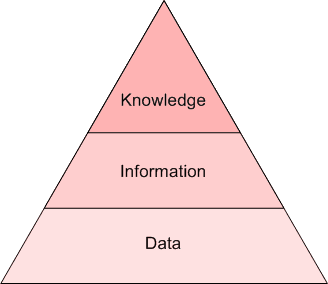
The Pyramid of Understanding: data, information, knowledge.
Another way to approach the difference between these 2 concepts is by visualization via the Venn diagram below, which also takes other related concepts into account in order to demonstrate the relationships and significant overlaps between a number of closely-related fields and disciplines.

Source: Practical Text Mining and Statistical Analysis for Non-structured Text Data Applications.
I am not totally sold on this diagram -- it conflates processes with tools -- but it does serve its limited purpose.
Various other explanations as to the precise relationship between text mining and NLP exist, and you are free to find something that works better for you. We aren't really as concerned with the exact definitions -- absolute or relative -- as much as we are with the intuitive recognition that the concepts are related with some overlap, yet still distinct.
The point we will move forward with: although NLP and text mining are not the same thing, they are closely related, deal with the same raw data type, and have some crossover in their uses. Importantly, much of the preprocessing of data for the tasks falling under these 2 umbrellas is identical.
Attempts to avoid ambiguity is a large part of text preprocessing. We want to preserve intended meaning while eliminating noise. In order to do so, the following is required:
- Knowledge about language
- Knowledge about the world
- A way to combine knowledge sources
Why else is text difficult?

Source: CS124 Stanford.
Textual Data Science Task Framework
Can we craft a sufficiently general framework for approaching textual data science tasks? It turns out that processing text is very similar to other non-text processing tasks, and so we can look to the KDD Process for inspiration.
We can say that these are the main steps of a generic text-based task, one which falls under text mining or NLP.
1 - Data Collection or Assembly
- Obtain or build corpus, which could be anything from emails, to the entire set of English Wikipedia articles, to our company's financial reports, to the complete works of Shakespeare, to something different altogether
2 - Data Preprocessing
- Perform the preparation tasks on the raw text corpus in anticipation of text mining or NLP task
- Data preprocessing consists of a number of steps, any number of which may or not apply to a given task, but generally fall under the broad categories of tokenization, normalization, and substitution
3 - Data Exploration & Visualization
- Regardless of what our data is -- text or not -- exploring and visualizing it is an essential step in gaining insight
- Common tasks may include visualizing word counts and distributions, generating wordclouds, and performing distance measures
4 - Model Building
- This is where our bread and butter text mining or NLP task takes place (includes training and testing)
- Also includes feature selection & engineering when applicable
- Language models: Finite state machines, Markov models, vector space modeling of word meanings
- Machine learning classifiers: Naive bayes, logistic regression, decision trees, Support Vector Machines, neural networks
- Sequence models: Hidden Markov models, recursive neural networks (RNNs), Long short term memory neural networks (LSTMs)
5 - Model Evaluation
- Did the model perform as expected?
- Metrics will vary dependent on what type of text mining or NLP task
- Even thinking outside of the box with chatbots (an NLP task) or generative models: some form of evaluation is necessary

A simple textual data task framework. These steps aren't exactly linear, but visualized as such for convenience.
Join me next time we will define and further explore a data preprocessing framework for textual data tasks.
Related: