2011: DanNet triggers deep CNN revolution
In 2021, we are celebrating the 10-year anniversary of DanNet, which, in 2011, was the first pure deep convolutional neural network (CNN) to win computer vision contests. Read about its history here.
By Jürgen Schmidhuber (@SchmidhuberAI)

Abstract. In 2021, we are celebrating the 10-year anniversary of DanNet, named after my outstanding Romanian postdoc Dan Claudiu Cireșan (aka Dan Ciresan). In 2011, DanNet was the first pure deep convolutional neural network (CNN) to win computer vision contests. For a while, it enjoyed a monopoly. From 2011 to 2012 it won every contest it entered, winning four of them in a row (15 May 2011, 6 Aug 2011, 1 Mar 2012, 10 Sep 2012), driven by a very fast implementation based on graphics processing units (GPUs). Remarkably, already in 2011, DanNet achieved the first superhuman performance in a vision challenge, although compute was still 100 times more expensive than today. In July 2012, our CVPR paper on DanNet hit the computer vision community. The similar AlexNet (citing DanNet) joined the party in Dec 2012. Our even much deeper Highway Net (May 2015) and its special case ResNet (Dec 2015) further improved performance (a ResNet is a Highway Net whose gates are always open). Today, a decade after DanNet, everybody is using fast deep CNNs for computer vision.
 CNNs originated over 4 decades ago [CNN1-4]. The basic CNN architecture with convolutional layers and downsampling layers is due to Kunihiko Fukushima (1979) [CNN1, CNN1+]. In 1987, NNs with convolutions were combined by Alex Waibel [CNN1a,b] with weight sharing and backpropagation, a technique from 1970 [BP1-4] [R7]. Yann LeCun's team later contributed important improvements of CNNs, especially for images, e.g., [CNN2] [CNN4] [T20] (Sec. XVIII). The popular downsampling variant called "max-pooling" was introduced by Juyang Weng et al. (1993) [CNN3]. In 2010, my own team at the Swiss AI Lab IDSIA showed [MLP1] that unsupervised pre-training is not necessary to train deep NNs (a reviewer called this a "wake-up call to the machine learning community"— compare the survey blog post [MLP2]).
CNNs originated over 4 decades ago [CNN1-4]. The basic CNN architecture with convolutional layers and downsampling layers is due to Kunihiko Fukushima (1979) [CNN1, CNN1+]. In 1987, NNs with convolutions were combined by Alex Waibel [CNN1a,b] with weight sharing and backpropagation, a technique from 1970 [BP1-4] [R7]. Yann LeCun's team later contributed important improvements of CNNs, especially for images, e.g., [CNN2] [CNN4] [T20] (Sec. XVIII). The popular downsampling variant called "max-pooling" was introduced by Juyang Weng et al. (1993) [CNN3]. In 2010, my own team at the Swiss AI Lab IDSIA showed [MLP1] that unsupervised pre-training is not necessary to train deep NNs (a reviewer called this a "wake-up call to the machine learning community"— compare the survey blog post [MLP2]).
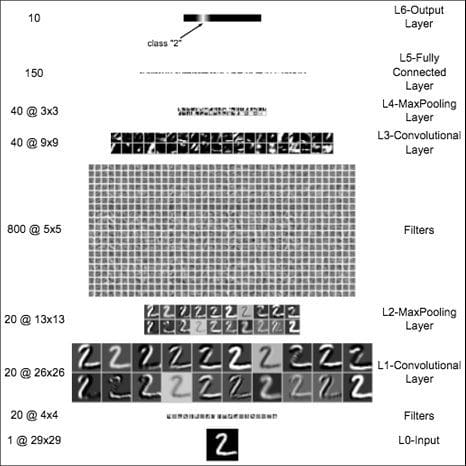
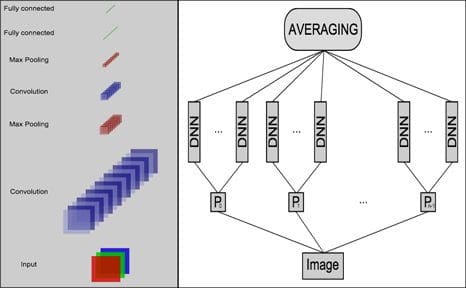 One year later, our team with my postdocs Dan Cireșan & Ueli Meier and my PhD student Jonathan Masci (a fellow co-founder of NNAISENSE) greatly sped up the training of deep CNNs. Our fast GPU-based [GPUNN] CNN of 1 Feb 2011 [GPUCNN1,2,6], often called "DanNet," was a practical breakthrough. Published later that year at IJCAI [GPUCNN1], it was much deeper and faster than earlier GPU-accelerated CNNs of 2006 [GPUCNN]. DanNet showed that deep CNNs worked far better than the existing state-of-the-art for recognizing objects in images [GPUCNN2,2+,5,6].
One year later, our team with my postdocs Dan Cireșan & Ueli Meier and my PhD student Jonathan Masci (a fellow co-founder of NNAISENSE) greatly sped up the training of deep CNNs. Our fast GPU-based [GPUNN] CNN of 1 Feb 2011 [GPUCNN1,2,6], often called "DanNet," was a practical breakthrough. Published later that year at IJCAI [GPUCNN1], it was much deeper and faster than earlier GPU-accelerated CNNs of 2006 [GPUCNN]. DanNet showed that deep CNNs worked far better than the existing state-of-the-art for recognizing objects in images [GPUCNN2,2+,5,6].
 On a sunny day in Silicon Valley, at IJCNN 2011, DanNet blew away the competition and achieved the first superhuman visual pattern recognition in an international contest [GPUCNN2-3,5]. Even the New York Times mentioned this. DanNet performed twice as good as human test subjects and three times better than the already impressive second place entry by LeCun's team [SER11]. Compare Sec. D & Sec. XVIII of [T20].
On a sunny day in Silicon Valley, at IJCNN 2011, DanNet blew away the competition and achieved the first superhuman visual pattern recognition in an international contest [GPUCNN2-3,5]. Even the New York Times mentioned this. DanNet performed twice as good as human test subjects and three times better than the already impressive second place entry by LeCun's team [SER11]. Compare Sec. D & Sec. XVIII of [T20].
Since 2011, DanNet has attracted tremendous interest from industry. Its temporary monopoly on winning computer vision competitions made it the first deep CNN to win: a Chinese handwriting contest (ICDAR, May 2011), a traffic sign recognition contest (IJCNN, Aug 2011), an image segmentation contest (ISBI, May 2012), and a contest on object detection in large images (ICPR, Sept 2012). The latter was actually a medical imaging contest on cancer detection [GPUCNN8]. Our CNN image scanners were 1000 times faster than previous methods [SCAN]. The significance of these kind of improvements for the health care industry is obvious. Today IBM, Siemens, Google, and many startups are pursuing this approach.
In 2011, we also introduced our deep neural nets to Arcelor Mittal, the world's largest steel producer, and were able to greatly improve steel defect detection [ST]. To the best of my knowledge, this was the first deep learning breakthrough in heavy industry. A significant part of modern computer vision is extending our work of 2011, e.g., [DL1-4] and Sec. 19 of [MIR].
 A follow up technical report on DanNet in Feb 2012 summarized some of the recent breakthroughs. In July 2012, DanNet was also presented at CVPR, the leading computer vision conference [GPUCNN3]. This helped to spread the word in the computer vision community. As of 2020, the CVPR article was the most cited DanNet paper, albeit not the first [GPUCNN1-3,6].
A follow up technical report on DanNet in Feb 2012 summarized some of the recent breakthroughs. In July 2012, DanNet was also presented at CVPR, the leading computer vision conference [GPUCNN3]. This helped to spread the word in the computer vision community. As of 2020, the CVPR article was the most cited DanNet paper, albeit not the first [GPUCNN1-3,6].
After DanNet had won 4 image recognition competitions, the similar GPU-accelerated "AlexNet" won the ImageNet [IM09] 2012 contest [GPUCNN4-5] [R6]. Unlike DanNet, AlexNet used Christoph v. d. Malsburg's rectified linear neurons (ReLUs) [CMB] (1973) and a variant of Stephen J. Hanson's stochastic delta rule (1990) called "dropout" [Drop1] [T20]. While both of these techniques helped, they are not really required to win vision contests [GPUCNN5] [R6]. Back then, the only really important CNN-related task was to greatly accelerate known techniques for training CNNs through GPUs. Compare Sec. XIV of [T20].
 We continued to make CNNs and other neural nets even deeper and better. Until 2015, deep networks had at most a few tens of layers, e.g., 20-30 layers. But in May 2015, our Highway Net [HW1] [HW3] [HW] [R5] was the first working extremely deep feedforward neural net with hundreds of layers. The Highway Net is based on the LSTM principle [LSTM1-2] which enables much deeper learning. Its special case called "ResNet" [HW2] (the ImageNet 2015 winner of Dec 2015) is a Highway Net whose gates are always open (compare [HW] & Sec. 4 of [MIR]). Highway Nets perform roughly as well as ResNets on ImageNet [HW3]. Highway layers are also often used for natural language processing [HW3] (compare [MIR] [DEC] [T20]).
We continued to make CNNs and other neural nets even deeper and better. Until 2015, deep networks had at most a few tens of layers, e.g., 20-30 layers. But in May 2015, our Highway Net [HW1] [HW3] [HW] [R5] was the first working extremely deep feedforward neural net with hundreds of layers. The Highway Net is based on the LSTM principle [LSTM1-2] which enables much deeper learning. Its special case called "ResNet" [HW2] (the ImageNet 2015 winner of Dec 2015) is a Highway Net whose gates are always open (compare [HW] & Sec. 4 of [MIR]). Highway Nets perform roughly as well as ResNets on ImageNet [HW3]. Highway layers are also often used for natural language processing [HW3] (compare [MIR] [DEC] [T20]).
The original successes of DanNet required a precise understanding of the inner workings of GPUs [GPUCNN1-3]. Today, convenient software packages shield the user from such details, and compute is roughly 100 times cheaper than 10 years ago when our results set the stage for the recent decade of deep learning [DEC]. Many current commercial neural net applications are based on what started in 2011 [DL1-4] [DEC].
Acknowledgments
Thanks to several expert reviewers for useful comments. (Let me know under juergen@idsia.ch if you can spot any remaining error.) The contents of this article may be used for educational and non-commercial purposes, including articles for Wikipedia and similar sites.
References
[MLP1] D. C. Ciresan, U. Meier, L. M. Gambardella, J. Schmidhuber. Deep Big Simple Neural Nets For Handwritten Digit Recognition. Neural Computation 22(12): 3207-3220, 2010. ArXiv Preprint (1 March 2010). [Showed that plain backprop for deep standard NNs is sufficient to break benchmark records, without any unsupervised pre-training.]
[MLP2] J. Schmidhuber (Sep 2020). 10-year anniversary of supervised deep learning breakthrough (2010). No unsupervised pre-training. The rest is history
[MIR] J. Schmidhuber (2019). Deep Learning: Our Miraculous Year 1990-1991. See also arxiv:2005.05744.
[DEC] J. Schmidhuber (2020). The 2010s: Our Decade of Deep Learning / Outlook on the 2020s.
[DL1] J. Schmidhuber, 2015. Deep Learning in neural networks: An overview. Neural Networks, 61, 85-117. More.
[DL2] J. Schmidhuber, 2015. Deep Learning. Scholarpedia, 10(11):32832.
[DL4] J. Schmidhuber, 2017. Our impact on the world's most valuable public companies: 1. Apple, 2. Alphabet (Google), 3. Microsoft, 4. Facebook, 5. Amazon ....
[T20] J. Schmidhuber (2020). Critique of 2018 Turing Award for deep learning.
[CNN1] K. Fukushima: Neural network model for a mechanism of pattern recognition unaffected by shift in position—Neocognitron. Trans. IECE, vol. J62-A, no. 10, pp. 658-665, 1979. [The first deep convolutional neural network architecture, with alternating convolutional layers and downsampling layers. In Japanese. English version: [CNN1+]. More in Scholarpedia.]
[CNN1+] K. Fukushima: Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, vol. 36, no. 4, pp. 193-202 (April 1980). Link.
[CNN1a] A. Waibel. Phoneme Recognition Using Time-Delay Neural Networks. Meeting of IEICE, Tokyo, Japan, 1987. [First application of backpropagation [BP1][BP2] and weight-sharing to a convolutional architecture.]
[CNN1b] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano and K. J. Lang. Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328-339, March 1989.
[CNN2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel: Backpropagation Applied to Handwritten Zip Code Recognition, Neural Computation, 1(4):541-551, 1989. PDF.
[CNN3] Weng, J., Ahuja, N., and Huang, T. S. (1993). Learning recognition and segmentation of 3-D objects from 2-D images. Proc. 4th Intl. Conf. Computer Vision, Berlin, Germany, pp. 121-128. [A CNN whose downsampling layers use Max-Pooling (which has become very popular) instead of Fukushima's Spatial Averaging [CNN1].]
[CNN4] M. A. Ranzato, Y. LeCun: A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images. Proc. ICDAR, 2007
[IM09] J. Deng, R. Socher, L.J. Li, K. Li, L. Fei-Fei (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248-255). IEEE, 2009.
[GPUNN] Oh, K.-S. and Jung, K. (2004). GPU implementation of neural networks. Pattern Recognition, 37(6):1311-1314. [Speeding up traditional NNs on GPU by a factor of 20.]
[GPUCNN] K. Chellapilla, S. Puri, P. Simard. High performance convolutional neural networks for document processing. International Workshop on Frontiers in Handwriting Recognition, 2006. [Speeding up shallow CNNs on GPU by a factor of 4.]
[GPUCNN1] D. C. Ciresan, U. Meier, J. Masci, L. M. Gambardella, J. Schmidhuber. Flexible, High Performance Convolutional Neural Networks for Image Classification. International Joint Conference on Artificial Intelligence (IJCAI-2011, Barcelona), 2011. PDF. ArXiv preprint (1 Feb 2011). [Speeding up deep CNNs on GPU by a factor of 60. Used to win four important computer vision competitions 2011-2012 before others won any with similar approaches.]
[GPUCNN2] D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. A Committee of Neural Networks for Traffic Sign Classification. International Joint Conference on Neural Networks (IJCNN-2011, San Francisco), 2011. PDF. HTML overview. [At IJCNN 2011, DanNet achieved the first superhuman performance in a computer vision contest, with half the error rate of humans, and one third the error rate of the closest competitor. This led to massive interest from industry.]
[GPUCNN2+] D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. Multi-Column Deep Neural Network for Traffic Sign Classification. Neural Networks 32: 333-338, 2012. PDF of preprint.
[GPUCNN3] D. C. Ciresan, U. Meier, J. Schmidhuber. Multi-column Deep Neural Networks for Image Classification. Proc. IEEE Conf. on Computer Vision and Pattern Recognition CVPR 2012, p 3642-3649, July 2012. PDF. Longer TR of Feb 2012: arXiv:1202.2745v1 [cs.CV]. More.
[GPUCNN4] A. Krizhevsky, I. Sutskever, G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. NIPS 25, MIT Press, Dec 2012. PDF.
[GPUCNN5] J. Schmidhuber. History of computer vision contests won by deep CNNs on GPU. March 2017. [How IDSIA used deep and fast GPU-based CNNs to win four important computer vision competitions 2011-2012 before others won contests using similar approaches.]
[GPUCNN6] J. Schmidhuber, D. Ciresan, U. Meier, J. Masci, A. Graves. On Fast Deep Nets for AGI Vision. In Proc. Fourth Conference on Artificial General Intelligence (AGI-11), Google, Mountain View, California, 2011. PDF.
[GPUCNN7] D. C. Ciresan, A. Giusti, L. M. Gambardella, J. Schmidhuber. Mitosis Detection in Breast Cancer Histology Images using Deep Neural Networks. MICCAI 2013. PDF.
[GPUCNN8] J. Schmidhuber. First deep learner to win a contest on object detection in large images— first deep learner to win a medical imaging contest (2012). HTML. [How IDSIA used GPU-based CNNs to win the ICPR 2012 Contest on Mitosis Detection and the MICCAI 2013 Grand Challenge.]
[SER11] P. Sermanet, Y. LeCun. Traffic sign recognition with multi-scale convolutional networks. Proc. IJCNN 2011, p 2809-2813, IEEE, 2011
[SCAN] J. Masci, A. Giusti, D. Ciresan, G. Fricout, J. Schmidhuber. A Fast Learning Algorithm for Image Segmentation with Max-Pooling Convolutional Networks. ICIP 2013. Preprint arXiv:1302.1690.
[ST] J. Masci, U. Meier, D. Ciresan, G. Fricout, J. Schmidhuber Steel Defect Classification with Max-Pooling Convolutional Neural Networks. Proc. IJCNN 2012. PDF.
[HW] J. Schmidhuber (2015): Overview of Highway Networks: First working really deep feedforward neural networks with over 100 layers. (Updated 2020 for 5-year anniversary.)
[HW1] R. K. Srivastava, K. Greff, J. Schmidhuber. Highway networks. Preprints arXiv:1505.00387 (May 2015) and arXiv:1507.06228 (July 2015). Also at NIPS 2015. [The first working very deep feedforward nets with over 100 layers. Let g, t, h, denote non-linear differentiable functions. Each non-input layer of a highway net computes g(x)x + t(x)h(x), where x is the data from the previous layer. (Like LSTM with forget gates [LSTM2] for RNNs.) Resnets [HW2] are a special case of this where the gates are always open: g(x)=t(x)=const=1. Highway Nets perform roughly as well as ResNets [HW2] on ImageNet [HW3]. Highway layers are also often used for natural language processing, where the simpler residual layers do not work as well [HW3]. More.]
[HW1a] R. K. Srivastava, K. Greff, J. Schmidhuber. Highway networks. Presentation at the Deep Learning Workshop, ICML'15, July 10-11, 2015. Link.
[HW2] He, K., Zhang, X., Ren, S., Sun, J. Deep residual learning for image recognition. Preprint arXiv:1512.03385 (Dec 2015). Residual nets are a special case of Highway Nets [HW1] where the gates are open: g(x)=1 (a typical highway net initialization) and t(x)=1. More.
[HW3] K. Greff, R. K. Srivastava, J. Schmidhuber. Highway and Residual Networks learn Unrolled Iterative Estimation. Preprint arxiv:1612.07771 (2016). Also at ICLR 2017.
[LSTM1] S. Hochreiter, J. Schmidhuber. Long Short-Term Memory. Neural Computation, 9(8):1735-1780, 1997. PDF. More.
[LSTM2] F. A. Gers, J. Schmidhuber, F. Cummins. Learning to Forget: Continual Prediction with LSTM. Neural Computation, 12(10):2451-2471, 2000. PDF. [The "vanilla LSTM architecture" with forget gates that everybody is using today, e.g., in Google's Tensorflow.]
[BP1] S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, 1970. See chapters 6-7 and FORTRAN code on pages 58-60. PDF. See also BIT 16, 146-160, 1976. Link. [The first publication of "modern" backpropagation, also known as the reverse mode of automatic differentiation.]
[BP2] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In R. Drenick, F. Kozin, (eds): System Modeling and Optimization: Proc. IFIP, Springer, 1982. PDF. [First application of backpropagation [BP1] to neural networks. Extending preliminary thoughts in his 1974 thesis.]
[BP4] J. Schmidhuber. Who invented backpropagation? More [DL2].
[R5] Reddit/ML, 2019. The 1997 LSTM paper by Hochreiter & Schmidhuber has become the most cited deep learning research paper of the 20th century.
[R6] Reddit/ML, 2019. DanNet, the CUDA CNN of Dan Ciresan in J. Schmidhuber's team, won 4 image recognition challenges prior to AlexNet.
[R7] Reddit/ML, 2019. J. Schmidhuber on Seppo Linnainmaa, inventor of backpropagation in 1970.
[Drop1] Hanson, S. J. (1990). A Stochastic Version of the Delta Rule, PHYSICA D,42, 265-272. [Dropout is a special case of the stochastic delta rule—compare preprint arXiv:1808.03578, 2018.]
[CMB] C. v. d. Malsburg (1973). Self-Organization of Orientation Sensitive Cells in the Striate Cortex. Kybernetik, 14:85-100, 1973. [See Table 1 for rectified linear units or ReLUs. Possibly this was also the first work on applying an EM algorithm to neural nets.]

Original. Reposted with permission.
Related:
- 5 Papers on CNNs Every Data Scientist Should Read
- Introduction to Convolutional Neural Networks
- Deep Learning in Neural Networks: An Overview