Transform speech into knowledge with Huggingface/Facebook AI and expert.ai
Speech2Data is a blend of open source and free-to-use AI models and technologies powered by Huggingface, Facebook AI and expert.ai. Learn more here.

Verba volant, scripta manent
(Words are fleeting, text persists)
Hearing isn’t understanding. Studies show that if we listen to a 10-minute speech, on average, we retain 50% of it initially, 25% after 48 hours, and only 10% after a week. In short, we hold on to a very limited amount of what we hear. It's not difficult to see how this cognitive limit can cause inefficiencies in scenarios where listening is key. Additionally, personal biases have an impact on what we grasp from verbal communication. Not to mention all the distractions that constantly interfere with our ability to focus on a conversation.
The size of the global natural language processing (NLP) market for business applications has grown at the speed of light, highlighting the importance of extracting knowledge and insights from unstructured digital text. The amount of data produced worldwide in 2020 is estimated to be around 44 zettabytes and digital text (i.e., emails, news articles, social media, messaging, documents, contracts, research papers, etc.) is a big part of this. While most of the focus for NLP and natural language understanding (NLU) has historically been on processing digital text, verbal communication has been overlooked.
Today, more than ever, it’s imperative to collect and index auditory information. With more people working from home, there’s been a spike in digital communication, often in the form of conference calls and web meetings. To properly classify this content, automatically create briefs and minutes, and generate search results, this content needs to be processed with natural language technologies.
SPEECH2DATA
Speech2Data is a blend of open source and free-to-use AI models and technologies powered by Huggingface, Facebook AI and expert.ai.
This module uses Wav2Vec 2.0 (from Facebook AI/HuggingFace) to transform audio files into actual text and the NL API (from expert.ai) to bring NLU on board, automatically interpreting human language and identifying valuable data in the audio file.
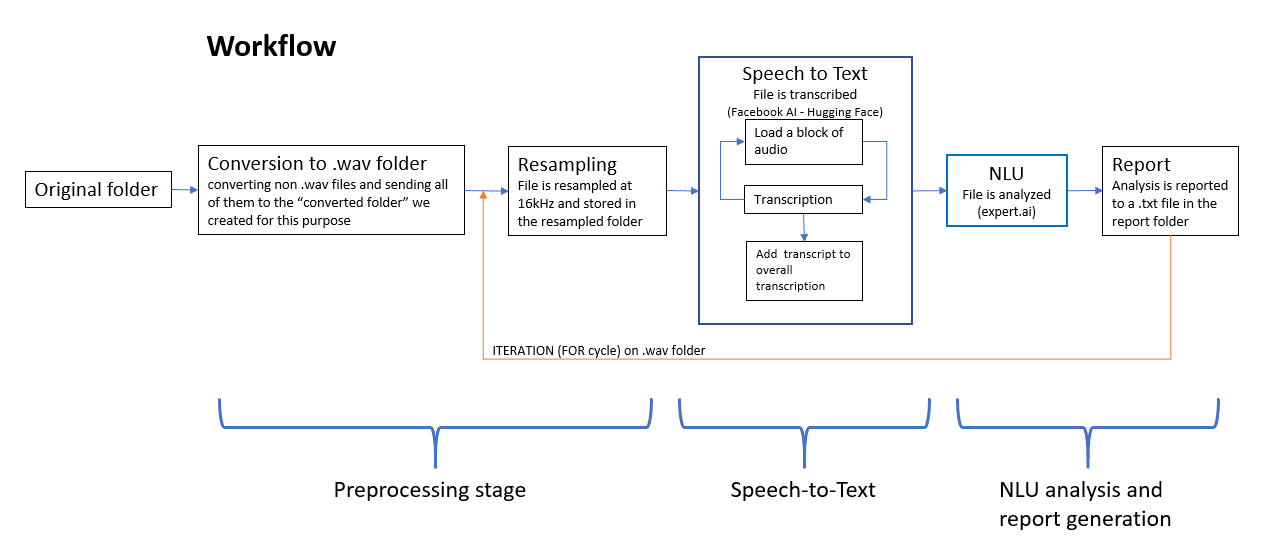
The module collects an audio file from the designated folder, converting it in compliance with Wav2Vec 2.0 (16kHz resampled wav files), and then processing it in 30-second blocks of audio. The pre-processing stage is necessary to set the optimal conditions to maximize the quality of the speech recognition process performed by the Facebook AI/HuggingFace model. Whereas splitting the audio files in multiple 30-second chunks makes it possible to use the model on most consumer laptops (bigger chunks require more computing power / processing time). At the end of this data preparation stage, the speech-2-text performed by Wav2Vec 2.0 produces a converted, processable text.
Adding a NLU layer like expert.ai at this point in the pipeline makes it possible to push the boundaries of speech recognition using NLP to understand text, isolate the relevant information to extract, and therefore produce structured data out of verbal communication. All collected data is then reworked into a report providing multiple types of information like the most relevant words, key phrases and main topics.
We designed this module in the most plug-and-play, easy-to-use way possible. All that is needed is to add a few variables to make it work (such as the source folder of the files, and the expert.ai account credentials – register here!), and it’s done. Any TEDx conference, voice note, or meeting recording can be processed.
This module is fully customizable, and it enables a varied list of possible applications from: automatic meeting minutes creation to news and podcast processing to creating cognitive maps using your favorite Beatles albums. The type of information produced by expert.ai NL API can be tailored to different needs, simply by using expert.ai Studio (here’s an introductory video on how). This solution currently has a 10-minute hard limit on the length of audio files it can process. However, it has fewer limitations when it comes to compatible formats, which include Whatsapp voice notes and mp4 videos.
If you’re interested in the technical details, check out the article at this link. We’re releasing the code behind Speech2Data on Github, so the NLP community can explore it, experiment with it, customize and extend it.