Text Preprocessing Methods for Deep Learning
While the preprocessing pipeline we are focusing on in this post is mainly centered around Deep Learning, most of it will also be applicable to conventional machine learning models too.

NLP Text Preprocessing Methods
Deep Learning, particularly Natural Language Processing (NLP), has been gathering a huge interest nowadays. Some time ago, there was an NLP competition on Kaggle called Quora Question insincerity challenge. The competition is a text classification problem and it becomes easier to understand after working through the competition, as well as by going through the invaluable kernels put up by the Kaggle experts.
So, first let’s start with explaining a little more about the text classification problem in the competition.
Text classification is a common task in natural language processing, which transforms a sequence of a text of indefinite length into a category of text. How could you use that?
- To find the sentiment of a review
- Find toxic comments on a platform like Facebook
- Find Insincere questions on Quora. A current ongoing competition on Kaggle
- Find fake reviews on websites
- Figure out if a text advert will get clicked or not
Now, each of these problems has something in common. From a Machine Learning perspective, these are essentially the same problem with just the target labels changing and nothing else. With that said, the addition of business knowledge can help make these models more robust and that is what we want to incorporate while preprocessing the data for test classification.
While the preprocessing pipeline we are focusing on in this post is mainly centered around Deep Learning, most of it will also be applicable to conventional machine learning models too.
First, let's go through the flow of a deep learning pipeline for text data before going through all the steps in order to get a higher level perspective about the whole process.
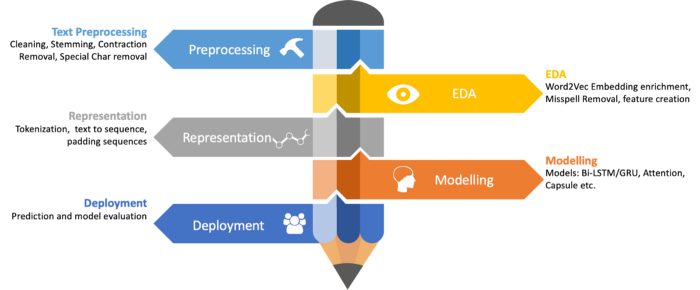
Text preprocessing infographic diagram, Source
We normally start with cleaning up the text data and performing basic EDA. Here we try to improve our data quality by cleaning up the data. We also try to improve the quality of our Word2Vec embeddings by removing OOV (Out-of-Vocabulary) words. These first two steps normally don’t have much order between them and we generally go back and forth between these two steps.
Next, we create a representation for text that could be fed into a deep learning model. We then start with creating our models and training them. Finally, we evaluate the models using appropriate metrics and get approval from respective shareholders to deploy our models. Don’t worry if these terms don’t make much sense now. We will try to explain them through the course of this article.
Here at this junction, let us take a little detour to talk a little about word embeddings. We will have to think about them while preprocessing data for our deep learning models.
Interested in a deep learning solution for NLP research?
Learn more about Exxact workstations starting at $3700
A Primer on Word2Vec Embeddings
We need to have a way to represent words in a vocab. One way to do that could be to use One hot encoding of word vectors but that is not really a good choice. One of the major reasons is that the one-hot word vectors cannot accurately express the similarity between different words, such as the cosine similarity.

Cosine similarity Word2Vec
Given the structure of one hot encoded vectors, the similarity is always going to come as 0 between different words. Another reason is that as the size of vocabulary increases these one hot encoded vectors become very large.
Word2Vec overcomes the above difficulties by providing us with a fixed length vector representation of words and by capturing the similarity and analogy relationships between different words.

Word2Vec Vectors
Word2vec vectors of words are learned in such a way that they allow us to learn different analogies. It enables us to do algebraic manipulations on words which were not possible before. For example: What is king — man + woman? It comes out to be Queen.
Word2Vec vectors also help us to find out the similarity between words. If we try to find similar words to “good”, we will find awesome, great etc. It is this property of word2vec that makes it invaluable for text classification. Now our deep learning network understands that “good” and “great” are essentially words with similar meaning.
Thus, in very simple terms, word2vec creates vectors for words. Thus we have a d dimensional vector for every word (common bigrams too) in a dictionary. We normally use pretrained word vectors which are provided to us by others after training on large corpora of texts like Wikipedia, twitter etc. The most commonly used pretrained word vectors are Glove and Fasttext with 300-dimensional word vectors. We are going to use Glove in this post.
Basic Preprocessing Techniques for Text Data
In most of cases, we observe that text data is not entirely clean. Data coming from different sources have different characteristics and that makes Text Preprocessing one of the most important steps in the classification pipeline.
For example, Text data from Twitter is totally different from text data on Quora, or some news/blogging platform, and thus would need to be treated differently. Helpfully, the techniques we are going to talk about in this post are generic enough for any kind of data you might encounter in the jungles of NLP.
a) Cleaning Special Characters and Removing Punctuations:
Our preprocessing pipeline depends a lot on the word2vec embeddings we are going to use for our classification task. In principle, our preprocessing should match the preprocessing that was used before training the word embedding. Since most of the embeddings don’t provide vector values for punctuations and other special chars, the first thing you want to do is to get rid of the special characters in your text data. These are some of the special chars that were there in the Quora Question data and we use replace function to get rid of these special chars.
# Some preprocesssing that will be common to all the text classification methods you will see.
puncts = [',', '.', '"', ':', ')', '(', '-', '!', '?', '|', ';', "'", '$', '&', '/', '[', ']', '>', '%', '=', '#', '*', '+', '\\', '•', '~', '@', '£',
'·', '_', '{', '}', '©', '^', '®', '`', '<', '→', '°', '€', '™', '›', '♥', '←', '×', '§', '″', '′', ' ', '█', '½', 'à', '…',
'“', '★', '”', '–', '●', 'â', '►', '−', '¢', '²', '¬', '░', '¶', '↑', '±', '¿', '▾', '═', '¦', '║', '―', '¥', '▓', '—', '‹', '─',
'▒', ':', '¼', '⊕', '▼', '▪', '†', '■', '’', '▀', '¨', '▄', '♫', '☆', 'é', '¯', '♦', '¤', '▲', 'è', '¸', '¾', 'Ã', '⋅', '‘', '∞',
'∙', ')', '↓', '、', '│', '(', '»', ',', '♪', '╩', '╚', '³', '・', '╦', '╣', '╔', '╗', '▬', '❤', 'ï', 'Ø', '¹', '≤', '‡', '√', ]
def clean_text(x):
x = str(x)
for punct in puncts:
if punct in x:
x = x.replace(punct, '')
return x
This could also have been done with the help of a simple regex. But we normally like the above way of doing things as it helps to understand the sort of characters we are removing from our data.
def clean_text(x):
pattern = r'[^a-zA-z0-9\s]'
text = re.sub(pattern, '', x)
return x
b) Cleaning Numbers:
Why do we want to replace numbers with #s? Because most embeddings have preprocessed their text like this.
Small Python Trick: We use an if statement in the code below to check beforehand if a number exists in a text. It is as an if is always fast than a re.sub command and most of our text doesn't contain numbers.
def clean_numbers(x):
if bool(re.search(r'\d', x)):
x = re.sub('[0-9]{5,}', '#####', x)
x = re.sub('[0-9]{4}', '####', x)
x = re.sub('[0-9]{3}', '###', x)
x = re.sub('[0-9]{2}', '##', x)
return x
c) Removing Misspells:
It always helps to find out misspells in the data. As those word embeddings are not present in the word2vec, we should replace words with their correct spellings to get better embedding coverage.
The following code artifact is an adaptation of Peter Norvig’s spell checker. It uses word2vec ordering of words to approximate word probabilities. As Google word2vec apparently orders words in decreasing order of frequency in the training corpus. You can use this to find out some misspelled words in the data you have.
# This comes from CPMP script in the Quora questions similarity challenge.
import re
from collections import Counter
import gensim
import heapq
from operator import itemgetter
from multiprocessing import Pool
model = gensim.models.KeyedVectors.load_word2vec_format('../input/embeddings/GoogleNews-vectors-negative300/GoogleNews-vectors-negative300.bin',
binary=True)
words = model.index2word
w_rank = {}
for i,word in enumerate(words):
w_rank[word] = i
WORDS = w_rank
def words(text): return re.findall(r'\w+', text.lower())
def P(word):
"Probability of `word`."
# use inverse of rank as proxy
# returns 0 if the word isn't in the dictionary
return - WORDS.get(word, 0)
def correction(word):
"Most probable spelling correction for word."
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
def build_vocab(texts):
sentences = texts.apply(lambda x: x.split()).values
vocab = {}
for sentence in sentences:
for word in sentence:
try:
vocab[word] += 1
except KeyError:
vocab[word] = 1
return vocab
vocab = build_vocab(train.question_text)
top_90k_words = dict(heapq.nlargest(90000, vocab.items(), key=itemgetter(1)))
pool = Pool(4)
corrected_words = pool.map(correction,list(top_90k_words.keys()))
for word,corrected_word in zip(top_90k_words,corrected_words):
if word!=corrected_word:
print(word,":",corrected_word)
Once we are through with finding misspelled data, the next thing remains to replace them using a misspell mapping and regex functions.
mispell_dict = {'colour': 'color', 'centre': 'center', 'favourite': 'favorite', 'travelling': 'traveling', 'counselling': 'counseling', 'theatre': 'theater', 'cancelled': 'canceled', 'labour': 'labor', 'organisation': 'organization', 'wwii': 'world war 2', 'citicise': 'criticize', 'youtu ': 'youtube ', 'Qoura': 'Quora', 'sallary': 'salary', 'Whta': 'What', 'narcisist': 'narcissist', 'howdo': 'how do', 'whatare': 'what are', 'howcan': 'how can', 'howmuch': 'how much', 'howmany': 'how many', 'whydo': 'why do', 'doI': 'do I', 'theBest': 'the best', 'howdoes': 'how does', 'mastrubation': 'masturbation', 'mastrubate': 'masturbate', "mastrubating": 'masturbating', 'pennis': 'penis', 'Etherium': 'Ethereum', 'narcissit': 'narcissist', 'bigdata': 'big data', '2k17': '2017', '2k18': '2018', 'qouta': 'quota', 'exboyfriend': 'ex boyfriend', 'airhostess': 'air hostess', "whst": 'what', 'watsapp': 'whatsapp', 'demonitisation': 'demonetization', 'demonitization': 'demonetization', 'demonetisation': 'demonetization'}
def _get_mispell(mispell_dict):
mispell_re = re.compile('(%s)' % '|'.join(mispell_dict.keys()))
return mispell_dict, mispell_re
mispellings, mispellings_re = _get_mispell(mispell_dict)
def replace_typical_misspell(text):
def replace(match):
return mispellings[match.group(0)]
return mispellings_re.sub(replace, text)
# Usage
replace_typical_misspell("Whta is demonitisation")
d) Removing Contractions:
Contractions are words that we write with an apostrophe. Examples of contractions are words like “ain’t” or “aren’t”. Since we want to standardize our text, it makes sense to expand these contractions. Below we have done this using a contraction mapping and regex functions.
contraction_dict = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not", "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not", "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is", "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would", "i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would", "it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam", "mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have", "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock", "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have", "she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is", "should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as", "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would", "there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have", "they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have", "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are", "we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are", "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is", "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have", "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have", "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all", "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have","you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have", "you're": "you are", "you've": "you have"}
def _get_contractions(contraction_dict):
contraction_re = re.compile('(%s)' % '|'.join(contraction_dict.keys()))
return contraction_dict, contraction_re
contractions, contractions_re = _get_contractions(contraction_dict)
def replace_contractions(text):
def replace(match):
return contractions[match.group(0)]
return contractions_re.sub(replace, text)
# Usage
replace_contractions("this's a text with contraction")
Apart from the above techniques, there are other preprocessing techniques of text like Stemming, Lemmatization and Stopword Removal. Since these techniques are not used along with Deep Learning NLP models, we won’t talk about them here.
Representation: Sequence Creation
One of the things that has made Deep Learning the "go to" choice for NLP is the fact that we don’t really have to hand-engineer features from the text data. The deep learning algorithms take as input a sequence of text to learn the structure of text just like a human does. Since machines cannot understand words they expect their data in numerical form. So we would like to represent out text data as a series of numbers.
To understand how this is done we need to understand a little about the Keras Tokenizer function. One can use any other tokenizer, but Keras tokenizer is a popular choice.
a) Tokenizer:
In simple words, a tokenizer is a utility function to split a sentence into words. keras.preprocessing.text.Tokenizer tokenizes(splits) the texts into tokens(words) while keeping only the most occurring words in the text corpus.
#Signature:
Tokenizer(num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' ', char_level=False, oov_token=None, document_count=0, **kwargs)
The num_words parameter keeps a pre-specified number of words in the text only. This is helpful as we don’t want our models to get a lot of noise by considering words that occur very infrequently. In real-world data, most of the words we leave using num_words param are normally misspells. The tokenizer also filters some non-wanted tokens by default and converts the text into lowercase.
The tokenizer once fitted to the data also keeps an index of words (dictionary of words which we can use to assign a unique number to a word) which can be accessed by:
tokenizer.word_index
The words in the indexed dictionary are ranked in order of frequencies.

Tokenizer training for text preprocessing
So the whole code to use tokenizer is as follows:
from keras.preprocessing.text import Tokenizer
## Tokenize the sentences
tokenizer = Tokenizer(num_words=max_features)
tokenizer.fit_on_texts(list(train_X)+list(test_X))
train_X = tokenizer.texts_to_sequences(train_X)
test_X = tokenizer.texts_to_sequences(test_X)
where train_X and test_X are lists of documents in the corpus.
b) Pad Sequence:
Normally our model expects that each sequence (each training example) will be of the same length (same number of words/tokens). We can control this using the maxlen parameter.
For example:

Tokenizer training sequences
train_X = pad_sequences(train_X, maxlen=maxlen)
test_X = pad_sequences(test_X, maxlen=maxlen)
Now our train data contains a list of numbers. Each list has the same length. And we also have the word_index which is a dictionary of the words occurring most in the text corpus.
Embedding Enrichment
As mentioned above, we will be using GLoVE Word2Vec embeddings to explain the enrichment. GLoVE pretrained vectors are trained on the Wikipedia corpus. (You can download them here).
That means some of the words that might be present in your data might not be present in the embeddings. How could we deal with that? Let’s first load the Glove Embeddings first.
def load_glove_index():
EMBEDDING_FILE = '../input/embeddings/glove.840B.300d/glove.840B.300d.txt'
def get_coefs(word,*arr): return word, np.asarray(arr, dtype='float32')[:300]
embeddings_index = dict(get_coefs(*o.split(" ")) for o in open(EMBEDDING_FILE))
return embeddings_index
glove_embedding_index = load_glove_index()
Be sure to put the path of the folder where you download these GLoVE vectors.
What does this glove_embedding_index contain? It is just a dictionary in which the key is the word and the value is the word vector, a np.array of length 300. The length of this dictionary is somewhere around a billion. Since we only want the embeddings of words that are in our word_index, we will create a matrix which just contains required embeddings.

tokenizer.word index for text preprocessing
def create_glove(word_index,embeddings_index):
emb_mean,emb_std = -0.005838499,0.48782197
all_embs = np.stack(embeddings_index.values())
embed_size = all_embs.shape[1]
nb_words = min(max_features, len(word_index))
embedding_matrix = np.random.normal(emb_mean, emb_std, (nb_words, embed_size))
count_found = nb_words
for word, i in tqdm(word_index.items()):
if i >= max_features: continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
else:
count_found-=1
print("Got embedding for ",count_found," words.")
return embedding_matrix
The above code works fine but is there a way that we can use the preprocessing in GLoVE to our advantage?
Yes. When preprocessing was done for glove, the creators didn’t convert the words to lowercase. That means that it contains multiple variations of a word like ‘USA’, ‘usa’ and ‘Usa’. That also means that in some cases while a word like ‘Word’ is present, its analog in lowercase i.e. ‘word’ is not present.
We can get through this situation by using the below code.
def create_glove(word_index,embeddings_index):
emb_mean,emb_std = -0.005838499,0.48782197
all_embs = np.stack(embeddings_index.values())
embed_size = all_embs.shape[1]
nb_words = min(max_features, len(word_index))
embedding_matrix = np.random.normal(emb_mean, emb_std, (nb_words, embed_size))
count_found = nb_words
for word, i in tqdm(word_index.items()):
if i >= max_features: continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
else:
if word.islower():
# try to get the embedding of word in titlecase if lowercase is not present
embedding_vector = embeddings_index.get(word.capitalize())
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
else:
count_found-=1
else:
count_found-=1
print("Got embedding for ",count_found," words.")
return embedding_matrix
The above was just an example of how we can use our knowledge of an embedding to get better coverage. Sometimes, depending on the problem, one might also derive value by adding extra information to the embeddings using some domain knowledge and NLP skills.
For example, we can add external knowledge to the embeddings themselves by adding polarity and subjectivity of a word from the TextBlob package in Python.
from textblob import TextBlob
word_sent = TextBlob("good").sentiment
print(word_sent.polarity,word_sent.subjectivity)
# 0.7 0.6
We can get the polarity and subjectivity of any word using TextBlob. Pretty neat! So, let us try to add this extra information to our embeddings.
def create_glove(word_index,embeddings_index):
emb_mean,emb_std = -0.005838499,0.48782197
all_embs = np.stack(embeddings_index.values())
embed_size = all_embs.shape[1]
nb_words = min(max_features, len(word_index))
embedding_matrix = np.random.normal(emb_mean, emb_std, (nb_words, embed_size+4))
count_found = nb_words
for word, i in tqdm(word_index.items()):
if i >= max_features: continue
embedding_vector = embeddings_index.get(word)
word_sent = TextBlob(word).sentiment
# Extra information we are passing to our embeddings
extra_embed = [word_sent.polarity,word_sent.subjectivity]
if embedding_vector is not None:
embedding_matrix[i] = np.append(embedding_vector,extra_embed)
else:
if word.islower():
embedding_vector = embeddings_index.get(word.capitalize())
if embedding_vector is not None:
embedding_matrix[i] = np.append(embedding_vector,extra_embed)
else:
embedding_matrix[i,300:] = extra_embed
count_found-=1
else:
embedding_matrix[i,300:] = extra_embed
count_found-=1
print("Got embedding for ",count_found," words.")
return embedding_matrix
Engineering embeddings is an essential part of getting better performance from the deep learning models at a later stage. Generally, we will revisit this part of code multiple times during the stage of a project while trying to improve our models even further. You can show up a lot of creativity here to improve coverage over your word_index and to include extra features in your embedding.
More Engineered Features

Embedding_matrix text preprocessing methods
One can always add sentence specific features like sentence length, number of unique words, etc. as another input layer to give extra information to the Deep Neural Network.
For example, we created these extra features as part of a feature engineering pipeline for Quora Insincerity Classification Challenge.
def add_features(df):
df['question_text'] = df['question_text'].progress_apply(lambda x:str(x))
df["lower_question_text"] = df["question_text"].apply(lambda x: x.lower())
df['total_length'] = df['question_text'].progress_apply(len)
df['capitals'] = df['question_text'].progress_apply(lambda comment: sum(1 for c in comment if c.isupper()))
df['caps_vs_length'] = df.progress_apply(lambda row: float(row['capitals'])/float(row['total_length']),
axis=1)
df['num_words'] = df.question_text.str.count('\S+')
df['num_unique_words'] = df['question_text'].progress_apply(lambda comment: len(set(w for w in comment.split())))
df['words_vs_unique'] = df['num_unique_words'] / df['num_words']
return df
Conclusion
NLP is still a very interesting problem in the deep learning space, so we would encourage you to do a lot of experimentation to see what works and what doesn’t. We have tried to provide a wholesome perspective of the preprocessing steps for a deep learning neural network for any NLP problem, but that doesn’t mean it is definitive.
Original. Reposted with permission.
Related:
- Understanding BERT with Hugging Face
- Vision Transformers: Natural Language Processing (NLP) Increases Efficiency and Model Generality
- Open Source Datasets for Computer Vision