Vision Transformers: Natural Language Processing (NLP) Increases Efficiency and Model Generality
Why do we hear so little about transformer models applied to computer vision tasks? What about attention in computer vision networks?
Transformers Are for Natural Language Processing (NLP), Right?
There has been no shortage of developments vying for a share of your attention over the last year or so. However, if you regularly follow the state of machine learning research you may recall a loud contender for a share of your mind in OpenAI’s GPT-3 and accompanying business strategy development from the group. GPT-3 is the latest and by far the largest in OpenAI’s general purpose transformer lineage working on models for natural language processing.
Of course, GPT-3 and GPTs may grab headlines, but it belongs to a much larger superfamily of transformer models, including a plethora of variants based on the Bidirectional Encoder Representations from Transformers (BERT) family originally created by Google, as well as other smaller families of models from Facebook and Microsoft. For an expansive but still not exhaustive overview of major NLP transformers, the leading resource is probably the Apache 2.0 licensed Hugging Face (????) library.
Attention Is All You Need
All of the big NLP transformers share a component of intellectual inheritance from the seminal paper “Attention is all You Need” by Vaswani and colleagues in 2017. The paper laid the groundwork for doing away with architectures sporting recurrent connections in favor of long-sequence inputs coupled with attention. In the years since, transformer models, which are characteristically built out of attention module and do not have recurrent connections, have mostly superseded LSTM-based models like ULMFit, although we can probably credit ULMFit with highlighting the importance of transfer learning in NLP. Given the rapid growth in transformer size as models have scaled to millions and billions of parameters with concomitant energy and monetary costs for training, transfer learning is all but required to do anything useful with large NLP transformers.
If you’ve read a few blog posts in your efforts to stay up-to-date with developments in transformer models, you’ll probably notice something peculiar about a common analogy. Transformers are the most visible and impactful application of attention in machine learning and, while transformers have mostly been used in NLP, the biological inspiration for attention is loosely based on the vision systems of animals.
When humans and other animals look at something, each portion of the scene is experienced at a different level of detail; i.e. it’s easy to notice a difference in detail for objects in your peripheral vision compared to the center of your field of view. A number of mechanisms contribute to this effect, and there is even an anatomical basis for visual attention in the fovea centralis, a pit region in the center of the retina with an increased density of photosensitive cone cells responsible for facilitating detailed visual tasks. The human eye also facilitates visual attention by changing the shape of its lens to bring a particular depth into sharp focus like a photographer manipulating depth of field. At the same time, registering images from both eyes on a specific part of an attended object provides peak stereo vision, aka depth perception. These intuitive examples are often used to describe the concept of attention and form a natural fit for image-processing tasks with direct biological analogues.
So why do we hear so little about transformer models applied to computer vision tasks?
Attention in Computer Vision Networks
The use of attention in computer vision networks has followed a now-familiar pattern. Significant work on visual attention in neural networks was underway decades ago, and yes, Geoffrey Hinton was working on attention more than ten years ago (Larochelle and Hinton 2010). Attention didn’t make a huge impact on image processing until more recently however, following the success of NLP transformers.
Visual attention didn’t seem to be necessary for performance leaps in much of the image classification and processing tasks that kicked off the current deep learning renaissance. This includes AlexNet and subsequent champions of the image recognition competition based on the ImageNet dataset. Instead, deep learning researchers and engineers working in computer vision scrambled to collect the arguably lower hanging fruit of increasingly deep convolutional neural networks and other architectural tweaks. Consequently attention remained a niche area in deep vision models while other innovations like residual connections and dropout took hold.
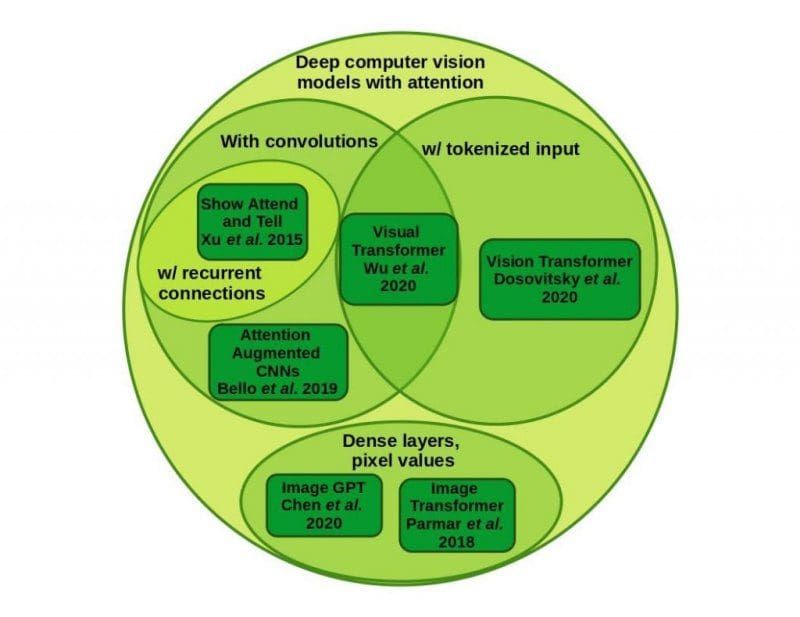
Concurrent with the high profile advances of transformer models for NLP, several image transformer research projects have been quietly underway. The most recent high-profile offerings in the vision transformer space have been 2020 contributions in the form of Vision Transformer from Dosovitsky and colleagues at Google Brain, Image GPT form Chen et al. at OpenAI, and the Visual Transformer from researchers at Facebook. Due in no small part to hard-working PR departments, we’ve come to expect headline advances like these from large commercial labs from the top 10 listings in the S&P 500 (including OpenAI due to their special relationship with Microsoft), but there have been plenty of contributions to attention research for computer vision from smaller labs.
One of the first examples of taking inspiration from the NLP successes following “Attention is all You Need” and applying the lessons learned to image transformers was the eponymous paper from Parmar and colleagues in 2018. Before that, in 2015, a paper from Kelvin Xu et al. under the tutelage of Yoshua Bengio developed deep computer vision models with hard and soft attention in “Show Attend and Tell” to generate image captions. Like NLP models at the time, which were also starting to experiment with attention, Xu et al. used recurrent connections (in the form of an LSTM head) in their caption generation task, and the attention mechanism was a little different from the dot product attention mechanism used by Vaswani et al. that has become prevalent in transformer models.
But attention in computer vision predates the current deep learning era. As mentioned earlier, biological attention mechanisms have long been an inspiration for computer vision algorithms, and an interplay between using algorithms to model biological vision systems and using ideas from biological vision systems to build better computer vision systems has driven research for a number of decades. For example, Leavers and Oegmen both published work on the the subject in the early 1990s.
A Concise Review of Attention in Computer Vision
There have been many attempts over the years to capture the fuzzy concept of attention for better machine learning and computer vision algorithms. However, after the introduction of Vaswani’s Transformer model, the field seems to have settled on scaled dot product self-attention as a dominant mechanism, which we’ll review here graphically. For a more detailed mathematical explanation of this and other attention mechanisms see Lillian Weng’s post.

The attention mechanism people most commonly refer to when discussing self-attention is the scaled dot-product mechanism. In this scheme, an input vector is processed by a linear weight matrix (aka dense layer) that produces key, query, and value vectors. Unlike the tensors produced at each layer by typical deep learning formulations (“representations”), the key, query, value trio each have a specialized role to play.
Taking the dot product of the query and key vectors yields a scalar, which is later used to weight the value vector. To maintain bounded magnitudes in the resulting weighted value vectors, the query-key dot products are all scaled according to the dimension of the input and then subjected to a softmax activation function, ensuring the sum of all weights comes to 1.0. The weighted value vectors are finally summed together and passed to the next layer.
There are some variations across transformers in how the input vectors are embedded/tokenized and how attention modules are put together, but the mechanism described above is truly “all you need” as a building block to put together a transformer.
| Paper | Attention Mechanism |
| Larochelle and Hinton 2010 | Foveal fixation in Restricted Boltzmann Machines (RBMs) |
| Xu et al. 2015 | Soft (differentiable) and hard (non-differentiable) attention |
| Mnih et al. 2015 | Differentiable spatial foveal mechanism |
| Vaswani et al. publish “Attention is All You Need.” 2017 | |
| Parmar et al. 2018 | Scaled dot product self-attention |
| Bello et al. 2019 | Scaled dot product self-attention |
| Wu et al. 2020 | Scaled dot product self-attention |
| Dosovitsky et al. 2020 | Scaled dot product self-attention |
Previous implementations of attention in computer vision models have followed more directly from inspirational examples from biology. Larochelle and Hinton’s foveal fixation and Mnih et al.’s differentiable spatial fovea mechanism are both inspired by the fovea centralis of many vertebrate eyes, for example. With the present dominance of transformer models in NLP and subsequent application of the sequence transformer idea to computer vision, that means that unlike early attention mechanisms image/vision transformers are now typically trained on unwrapped 1-dimensional representations of 2-dimensional images. Interestingly enough this enables the use of nearly the same models to be used for visual tasks, like image generation and classification, as are used for sequence-based tasks, like natural language processing.
Should Vision Transformers Be Used for Everything?
In a series of experiments beginning in the 1980s (reviewed in the New York Times here and by Newton and Sur here) , Mriganka Sur and colleagues began to project visual sensory inputs into other parts of the brains of ferrets, most notably the auditory thalamus. As the name suggests, the auditory thalamus and associated cortex is normally associated with processing sounds. A fundamental question in neuroscience is what proportion of brain capability and modular organization is hard-wired by genetic programs, and what proportion is amenable to influences during postnatal development. We’ve seen some of these ideas of “instinctual” modular organization applied to artificial neural networks as well, see “Weight Agnostic Neural Networks” from Gaier and Ha 2019, for example.
With a variety of evidence including trained behavioral distinction of visual cues and electrophysiological recordings in the auditory cortex of neural responses to patterned visual inputs, Sur’s group and collaborators showed that visual inputs could be processed in alternate brain regions like the auditory cortex, making a strong case for developmental plasticity and a general-purpose neural learning substrate.
Why bring up an ethically challenging series of neural ablation experiments in newborn mammals? The idea of a universal learning substrate is a very attractive concept in machine learning, amounting to the polar opposite of the expert systems of “Good Old-Fashioned Artificial Intelligence.” If we can find a basic architecture that is capable of learning any task on any type of input data and couple that with a developmental learning algorithm capable of adjusting the model for both efficiency and efficacy, we’ll be left with an artificial general learner if not a full-blown artificial general intelligence to try and understand.
The image transformers described in this article are perhaps one step in that direction. For the most part (and in particular for the work from 2020 published by OpenAI, Google, and Facebook on their respective image transformer projects) researchers tried to deviate as little as possible from the same models used for NLP. Most notably that meant incorporating little in the way of an intrinsic embodiment of the 2-dimensional nature of the input data. Instead the various image transformers had to learn how to parse images that had been converted to either partially or completely unraveled 1-dimensional sequences.
Shortcomings of Image Transformers
There were shortcomings as well. OpenAI’s Image GPT reportedly has 2 to 3 times more parameters than comparably performing convolutional neural network models. One advantage of the now-standard convolutional architectures used for images is that it’s easy to apply convolution kernels trained on smaller images to images of almost arbitrarily higher resolution (in terms of pixel dimensions, not object scale) at inference time. The parameters remain the same for images that are 64 by 64 as they do for 1920 by 1080 pixels, and it doesn’t really matter where an object appears in an image because convolution is translationally equivariant.
Image GPT, on the other hand, is strongly constrained by memory and compute requirements that come from using dense transformer layers applied directly to pixel values. Consequently, Image GPT sports high computational costs compared to convolutional models with similar performance.
Visual and Vision Transformer from Facebook and Google, respectively, seem to avoid many of the challenges experienced by Image GPT by doing away with pixel values in favor of tokenized vector embeddings, often also invoking some sort of chunking or locality to break up the image. The result is that even though Vision Transformer from Google requires much larger datasets to achieve state-of-the-art results than similar conv-nets, it’s reportedly 2 to 4 times more efficient at inference time.
You Won’t Be Converting Datasets Just Yet…
There is probably too much biological evidence that supports the benefits of sensory-computational networks evolved explicitly to take advantage of 2D data to throw those ideas away, so we don’t recommend converting all datasets to 1D sequences any time soon.
The resemblance of learned convolutional kernels to experimentally observed receptive fields in the biological vision is too good to ignore. We won’t know for a while whether the generality of transformers constitutes a step on the best path to artificial general intelligence, or more of a misleading meander—personally we still have reservations about the scale of computation, energy, and data required to get these models to perform well—but they will at least remain very relevant commercially and warrant careful consideration with regard to AI safety for the foreseeable future.
Original. Reposted with permission.
Related:
- OpenAI Releases Two Transformer Models that Magically Link Language and Computer Vision
- Six Times Bigger than GPT-3: Inside Google’s TRILLION Parameter Switch Transformer Model
- Microsoft Uses Transformer Networks to Answer Questions About Images With Minimum Training