How our Obsession with Algorithms Broke Computer Vision: And how Synthetic Computer Vision can fix it
Deep Learning radically improved Machine Learning as a whole. The Data-Centric revolution is about to do the same. In this post, we’ll take a look at the pitfalls of mainstream Computer Vision (CV) and discuss why Synthetic Computer Vision (SCV) is the future.
By Paul Pop, Co-founder and CEO at Neurolabs
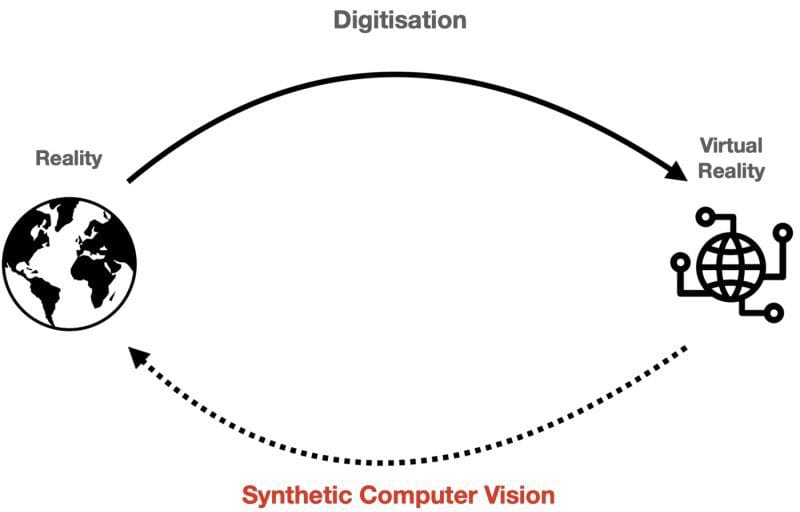
Synthetic Computer Vision aims to translate what’s in the Virtual world back to the Real world. (Image by author)
????️ The Current State of Computer Vision
As of today, there has been over $15B worth of investments in over 1,800 Computer Vision startups in the past 8 years, according to Crunchbase. More than 20 of these companies are currently valued above $1B and there’s a lot more to come according to Forbes.
Why are these companies valued so greatly? To put it simply, they are teaching computers how to see. By doing so, they are automating tasks that have previously been accomplished using human sight.
This boom followed a 2012 technology inflection point in Computer Vision, with the advent of Neural Networks — algorithms that mimic the human brain and are trained using colossal amounts of human-labelled data. Since 2012, algorithms have steadily improved and have become a match for humans in many visual tasks, for example counting objects, lip reading or cancer screening.
In the 10 years that followed everybody did their part: academia led the way with better algorithms; large companies invested in an army of humans who have diligently labelled these image datasets. Some of these efforts were even open sourced for the benefit of the community, such as ImageNet, a 14 million image dataset.
Unfortunately, now as these systems are getting deployed to productions, we are hitting a brick wall:
- The labelled data that we have is unreliable. A systematic study from MIT researchers of popular ML datasets, found an average error rate of incorrect labelling of 5.93% for ImageNet and an average of 3.4% across other datasets.
- There is little effort dedicated to solving the data problem. The intellectual efforts of academia are almost entirely focused on algorithm development, ignoring the fundamental need for good data — a guesstimate by Andrew Ng puts the ratio at 99% algorithm focus vs 1% data.
- Computer Vision algorithms don’t generalise well from one domain to another An algorithm trained to detect cars in the south of France will struggle to detect the same car in snowy Norway. Likewise a system trained on specific cameras might fail with another camera make and model.
♟️ Searching for inspiration
Already in 1946 Alan Turing suggested chess as a benchmark for computer capabilities, which was since throughly researched receiving a lot of media attention.
A commonly accepted way to measure performance in chess is through the Elo rating system, which provides a valid comparison of player skills. The graph below shows world champions and chess game engines. The human performance is hovering around the 2800 rating for the past 50 years, which is then suppressed by computers in 2010.
Until the last decade, we humans have designed chess algorithms to play based on rules we could design and understand. The Deep Learning revolution allowed us to break beyond human understanding, bringing a leap forward — just like it has for Computer Vision.
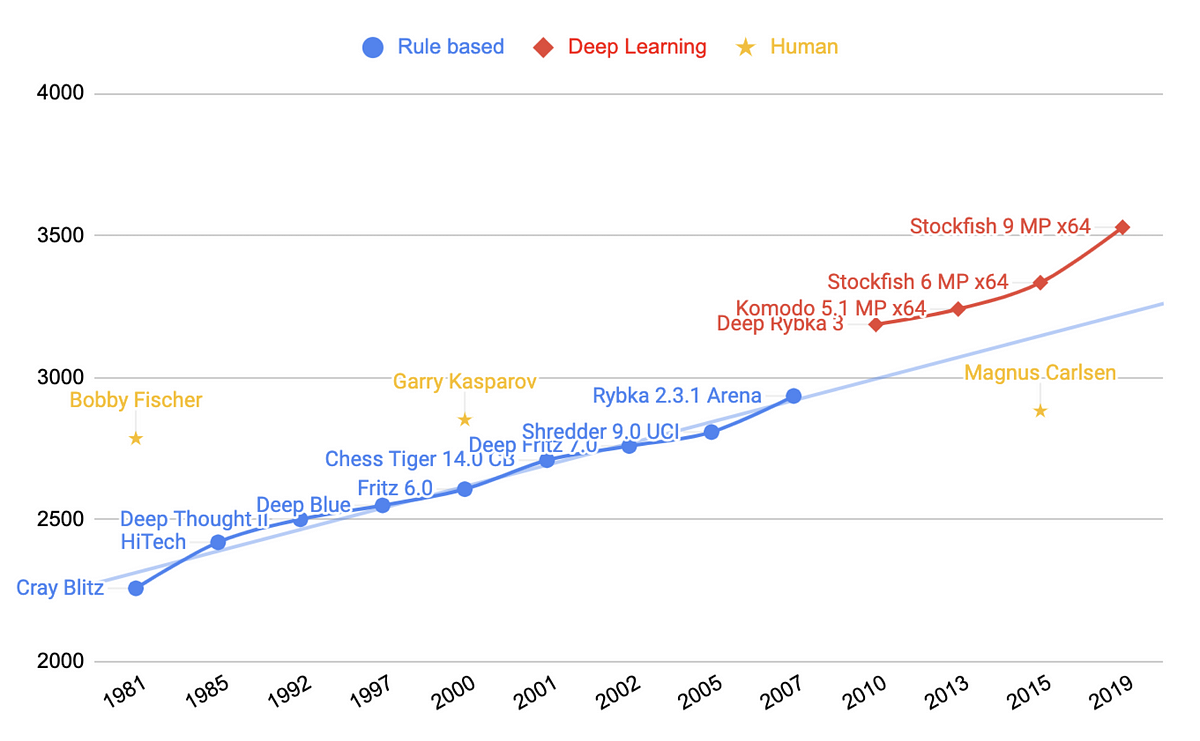
Chess engine and human ELO ratings (Image by author)
As good as the progress of Deep Learning chess game engines was, it has now been suppressed by the next level of chess engine: AlphaZero from DeepMind. What’s more impressive, is that AlphaZero did not use any human sourced data to achieve this performance. It was built without any knowledge of historical chess games, or any human guidance for finding optimal moves. AlphaZero was the teacher and the student — it taught itself how to better play the game by competing against itself and learning through the process.
AlphaZero won against Stockfish 8, best engine at the time, without losing a single game, keeping that edge even when Alpha Zero was given an order of magnitude less time to compute its next move.
Considering the remarkable improvements that AlphaZero, one has to wonder: Can we translate its success in chess to Computer Vision?
???? The new wave: Data-Centric AI
Within the new paradigm of Data Centric AI, the goal is not to create better algorithms, but increase performance by changing the data itself. Even if we disregard the hurdle of obtaining and labelling image datasets in the first place, questions still remain around the quality of the data: are we uniformly covering all possible use cases? is the data covering edge cases?
If we are to follow the path of Data-Centric Computer Vision, one must be in control of the data sourcing process. The data needs to be balanced and we need to have a good understanding of the parameters that are influencing what a Computer Vision model learns.
Let’s take a simple example in which we look at controlling 3 of such parameters: camera angle, lighting and occlusions. Can you imagine gathering a real dataset in which you have to diligently control the values of only these 3 parameters, whilst gathering 1000s of relevant images? With real data, the task is Sisyphean.
???? How do we manage data today?
In the past 5 years, there we have made tremendous progress in optimising the data gathering process and the quality of the data labels. Moreover, we have learned to make the most of the datasets, by using a variety of data augmentation techniques. Given an image in our dataset, we apply mathematical functions to it in order to create more variety in our data.
There are now over 400 companies with a total market value of $1.3T (a little over the market value of Facebook, ) catering to the data needs of our latest algorithms.
But does the current path lead to a dead end? Are we reaching the limits of the algorithms built on top of human sourced datasets? Like in chess, as long as we’re using human sourced data as input for our algorithms, we’re bound by design not to significantly surpass our own abilities.
In chess, the post-Deep Learning breakthrough came once we’ve stopped building on suboptimal human data and allowed the machines to build their own data in order to optimise what they learn. In computer vision we must do the same, allowing the machine to generate the data they need to optimise its own learning.
???? What’s next for Computer Vision?
The truly scalable way of creating training data is through Virtual Reality engines. In terms of fidelity, the output has become indistinguishable from the real world, giving full scene control to the user. This allows the user to generate smart data, that is truly useful for the Computer Vision model to learn. Synthetic Data can become the bedrock needed for the new Data-Centric AI framework.
We have good reasons to believe that the time for wide adoption of visual Synthetic Data is now.
- Virtual Reality engines have dedicated components for Synthetic Data generation (NVIDIA IsaacSim, Unity Perception) and the resulting data is not only eye-candy, but also essential for training better algorithms.
- 3D assets are quickly becoming a commodity — newest iPhone comes with LiDAR and first generation apps for 3D scans are producing great results.
- The Metaverse is coming and is a big deal. If a fraction of the $60B forecasted growth comes to fruition, we will live in a world where Virtual Reality will become habitual. Digital Twins have real applications today: one example from BMW, the factory of the future and another is Google’s Supply Chain Twin.
- The innovators of the industry have started using Virtual Reality to improve Computer Vision algorithms: Tesla is using virtual worlds to generate edge cases and novel views for driving scenarios.
????️????️ Synthetic Computer Vision (SCV)
Having access to the right tools to build our own data, we can envision a world in which Computer Vision algorithms are developed and trained without the tedious process of manual data labelling. Gartner predicts that Synthetic Data will be more predominant than real data within the next 3 years.
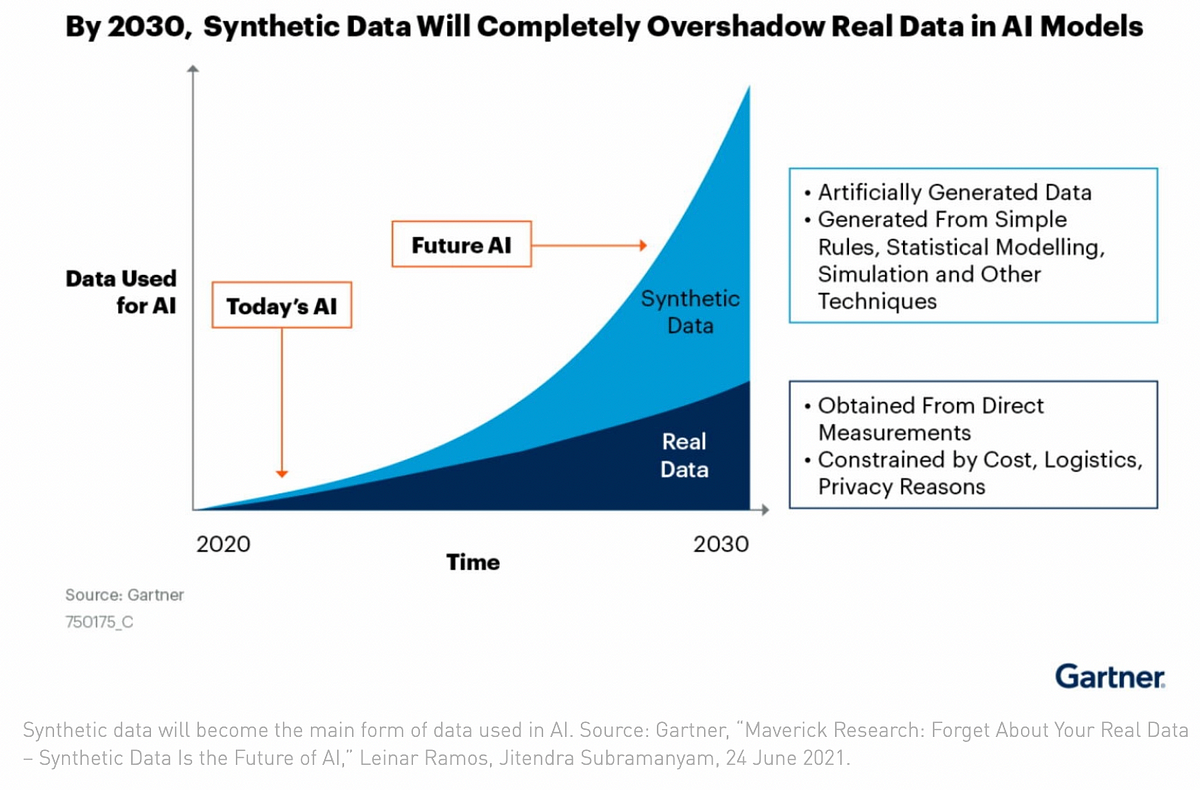
Why not go a step further? What about a world in which humans are not needed to label images for Computer Vision?
???? The future is bright
With Synthetic Computer Vision, we build in Virtual Reality and deploy for the Real world. The same way that AlphaZero taught itself what’s important in chess, we let the algorithms decide what they need to see in order to optimally learn.
In Synthetic Computer Vision (SCV), we train Computer Vision models using Virtual Reality engines and deploy the models in the real world.
????Beyond RGB images
Reality is much more than what the human eye can see. The algorithms that we’ve built are mostly focused on what a human can understand and label. But it does not have to be like that — we can build algorithms for sensors that measure beyond human perception. And we can train these algorithms programatically in Virtual Reality, without having doubts over their validity.
???? Smarter not harder
Instead of building larger models and using more computational power to solve our problems, we can be smart about how we source data from which our algorithms learn. Algorithms don't need more of the same data to learn, they need a variety of everything.
Deep Mind showed that AlphaZero was only the start of the road as they’ve applied the same principles to Go, Starcraft and protein folding. Today, we have all the necessary building blocks to build an AlphaZero for Computer-Vision, a self-learning system that is not limited by human input by design. A system that is capable of creating and manipulating virtual scenes through which it teaches itself how to solve Visual Automation tasks.
???? The pioneers in Synthetic Data generation
The foundation for Synthetic Computer Vision is provided by the Synthetic Data it is built upon. There are roughly 30 early stage companies operating in the visual Synthetic Data Generation space. Some are focused on a specific use case in one vertical, while the majority are operating horizontally across multiple verticals.

Synthetic Data companies grouped by focus (Image by author).
It's 2021 and we are only at the beginning of the road. Keep in mind that Synthetic Data is only one part of the puzzle that awaits to be solved!
❓Questions for you, Dear Reader
- It’s easy to imagine that in 10 years your smartphone will have better capabilities than you do for generic visual perception but how are we going to get there?
- Are (augmented) data labellers here to stay or simply a stepping stone?
- Will labelling move from 2D to the 3D world, or can we do without this approach altogether?
- State-of-the-Art results are achieved using Deep Learning algorithms in Computer Vision — can Synthetic Computer Vision enable a new wave of improved algorithms which were previously unavailable?
Bio: Paul Pop is Co-founder and CEO at Neurolabs. Background in Computer Science and AI from the University of Edinburgh and have been working in Computer Vision for the past decade. Led the team that build the Computer Vision player tracking system used in most European football leagues today, whilst at Hudl.
Related:
- Open Source Datasets for Computer Vision
- An overview of synthetic data types and generation methods
- Teaching AI to Classify Time-series Patterns with Synthetic Data