An overview of synthetic data types and generation methods
Synthetic data can be used to test new products and services, validate models, or test performances because it mimics the statistical property of production data. Today you'll find different types of structured and unstructured synthetic data.
By Elise Devaux & Dr. Christoph Wehmeyer, Statice
Synthetic data became a mainstream resource for various applications. It refers to data algorithmically generated approximating original data. The need for it can be a matter of data availability, cost reduction, security, or privacy concerns.
Virtually all industries relying on personal or sensitive data to function can benefit from synthetic data. Synthetic data can be used to test new products and services, validate models, or test performances because it mimics the statistical property of production data. Today you'll find different types of structured and unstructured synthetic data.
Different types of synthetic data
Text
Synthetic data can be artificially-generated text. Today, machine learning models allow the conception of remarkably performant natural language generation systems to build and train a model to generate text.
In the field of natural language processing, Amazon’s Alexa AI team uses synthetic data to complete the training data of its natural language understanding (NLU) system.
Media
Synthetic data can also be synthetic video, image, or sound. You artificially render media with properties close-enough to real-life data. This similarity allows using the synthetic media as a drop-in replacement for the original data. It can turn particularly helpful if you need to augment the database of a vision recognition system, for example.
For over a year now, the Waymo team has been generating realistic driving datasets from synthetic data. Alphabet's subsidiary company uses these datasets to train its self-driving vehicle systems. This way, they can include more complex and varied scenarios instead of spending significant time and resources to obtain observations.
Tabular data
Tabular synthetic data refers to artificially generated data that mimics real-life data stored in tables. It could be anything ranging from a patient database to users' analytical behavior information or financial logs. Synthetic data can function as a drop-in replacement for any type of behavior, predictive, or transactional analysis.
In the field of insurance, Swiss company La Mobilière used synthetic data to train churn prediction models. The data science team modeled tabular synthetic data after real-life customer data that was too sensitive to use and trained their machine learning models with the synthetic data.
Methods to generate synthetic data
Generating synthetic data comes down to learning the joint probability distribution in an original dataset to generate a new dataset with the same distribution.
Theoretically, with a simple table and very few columns, a very simplistic model mapping joint distribution can be a fast and easy way to get synthetic data. However, the more complex the dataset, the more difficult it is to map dependencies correctly.
The more columns you add, the more combinations appear. At some point, you might just lack data points to learn the distribution properly. It is why we need a more robust model to tackle the complexity of the data.
In the last few years, advancements in machine learning have put a variety of deep models in our hands that can learn a wide range of data types.
Through prediction and correction, Neural Network learns to reproduce the data and generalize beyond it to produce a representation that could have originated the data, making them particularly well-suited for synthetic data generation.
Variational Autoencoders and Generative Adversarial Networks are two commonly-used architectures in the field of synthetic data generation.
Variational Autoencoders
VAEs come from the field of unsupervised training and the autoencoder family. As generative models, they are designed to learn the underlying distribution of original data and are very efficient at generating complex models.
They function in two steps. At first, an encoder network transforms an original complex distribution into a latent distribution. A decoder network then transforms the distribution back to the original space. This double transformation, encoded-decoded, appears cumbersome at first glance but is necessary to formulate a quantifiable reconstruction error. Minimizing this error is the objective of the VAE training and what turns it into the desired transformation function, while an additional regularization objective controls the shape of the latent distribution.
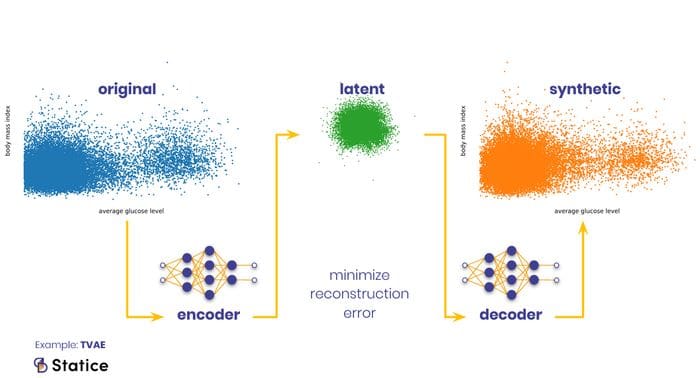
VAEs are a straightforward approach to solve the transformation problem. They are relatively easy to implement and to train. Their weak point, however, lies in their training objective. As your original data becomes more heterogeneous (e.g., mix of categorical, binary, continuous), it also becomes more difficult to formulate a reconstruction error that works well on all data components. If, for example, the reconstruction error puts too much emphasis on getting the continuous parts of the data right, the quality of the categorical parts might suffer.
Generative Adversarial Networks
GANs come from the field of unsupervised training and the generative family. In terms of architecture, they simultaneously train two neural networks in an adversarial fashion: a generator and a discriminator, both trying to outperform each other.
The generator digests random input from some latent distribution and transforms these data points into some other shape without ever directly looking at the original data. The discriminator digests input from the original data and the generator's output, aiming to predict where the input comes from. Both networks are connected in training so that the generator has access to the discriminator’s decision making.
When both networks are trained together, the discriminator needs to learn from patterns in the data whether they look realistic enough, while the generator learns to outsmart the discriminator by producing more realistic samples from its random input.
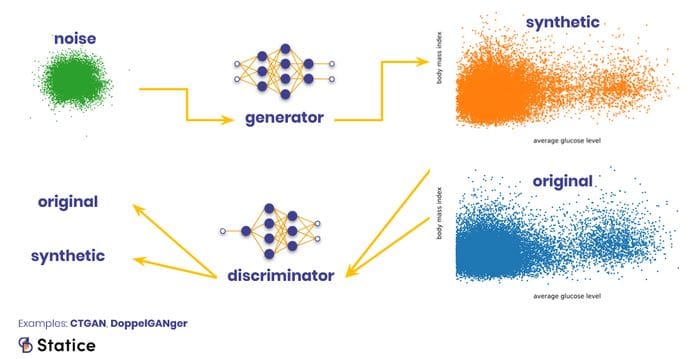
The advantage of GANs is that you don’t need to provide a reconstruction error. The discriminator learns the characteristics of the “real” data. This approach is particularly interesting for synthetic image generation, as it’s not clear how to translate into a function the characteristics of realisticness. In general, GANs are good with unstructured data.
However, GANs are also more challenging to train than VAEs and require more expertise. It is, for starters, not easy to see when to stop training. GANs are also prone to the mode collapse phenomenon, where the generator starts to produce only a small subset of the original data (think of a single image) instead of the full distribution.
What to watch out for when generating synthetic data
Each model has its advantages and disadvantages. Generally speaking, it's challenging to find a model that works with multiple data types and generates use-case agnostic data. In an enterprise context, you’ll need something that works consistently across different data types and structures. The solution won’t probably be a silver bullet solution model. Instead, it's preferable to consider which information you will work with to pick the suitable approaches.
Another element to consider is the original dataset's size, especially in the cases where you wish to maintain privacy. The more data and entries are available in a dataset, the better we can reflect the synthetic records' statistical properties.
The opposite stands true. When you have a very sparse dataset, it's more challenging to generate synthetic data that respect privacy and retain the original data's statistical value. Usually, you end up removing a lot of the data's statistical value. Similarly, the presence of notable outliers will make the balancing of utility and privacy more complex.
Finally, it's important to remember that synthetic data in itself isn't a magical solution to poor data quality and biased data. The quality of the synthetic data is correlated to the model's quality. And the model's quality is depending on the original data's quality.
Elise Devaux (@elise_deux) is a tech enthusiast digital marketing manager, working at Statice, a startup specialized in synthetic data as a privacy-preserving solution.
Christoph Wehmeyer is senior data scientist at Statice, where he plays a key role in the machine learning developments of the product. He holds a Ph.D. in theoretical physics from the Freie Universität of Berlin and prior to Statice, had spent five years as a postdoctoral researcher investigating machine learning methods for molecular biology.
Related:
- Data Protection Techniques Needed to Guarantee Privacy
- 10 Use Cases for Privacy-Preserving Synthetic Data
- How “Anonymous” is Anonymized Data?