Synthetic Data Platforms: Unlocking the Power of Generative AI for Structured Data
The article highlights various use cases of synthetic data, including generating confidential data, rebalancing imbalanced data, and imputing missing data points. It also provides information on popular synthetic data generation tools such as MOSTLY AI, SDV, and YData.

Image by GarryKillian on Freepik
Creating a machine learning or deep learning model is so easy.. Nowadays, there are different tools and platforms available to not only automate the entire process of creating a model but to even help you to select the best model for a particular data set.
One of the essential things you need to solve a problem by creating a model is a dataset that contains all the required attributes describing the problem you are trying to solve.. So, suppose we are looking at a dataset describing the diabetes history of patients. There will be specific columns that are the significant attributes like age, gender, glucose level, etc. which play an essential role in predicting whether a person has diabetes or not. In order to build a diabetes prediction model, we can find multiple datasets that are publicly available. However, we may face difficulty in solving problems where data is not readily available or highly imbalanced.
What is Synthetic Data?
Synthetic data generated by deep learning algorithms is often used in replacement of original data when data access is limited by privacy compliance or when the original data needs to be augmented to fit specific purposes. Synthetic data mimics the real data by recreating the statistical properties. Once trained on real data, the synthetic data generator can create any amount of data that closely resembles the patterns, distributions, and dependencies of the real data. This not only helps generate similar data but also helps in introducing certain constraints to the data, such as new distributions. . Let's explore some use cases where synthetic data can play an important role.
- Generating confidential data: Data in banking, insurance, healthcare and even telecom can be extremely sensitive. Touching this data usually requires special permissions for each project., Synthetic data generation can unlock these data assets and be used to create features, understand user behavior, test models and explore new ideas.
- Rebalancing data: Highly imbalanced data can be effectively and easily rebalanced using synthetic data generators. Works better than naive upsampling and is in cases of high imbalance, like fraud patterns, it can outperform more sophisticated methods, like SMOTE.
- Imputing missing data points: Nul values are an annoying part of life when you work with data. Filling these blanks with meaningful synthetic datapoints can make reading samples a more informative exercise.
How is Synthetic Data Generated?
Generative AI models are crucial in synthetic data production since they are explicitly trained on the original dataset and can replicate its traits and statistical attributes. Models of generative AI, such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), comprehend the underlying data and produce realistic and representative synthetic instances.
There are numerous open-source and closed source synthetic data generators out there, some better than others. When evaluating the performance of synthetic data generators, it’s important to look at two aspects: accuracy and privacy. Accuracy needs to be high without the synthetic data overfitting the original data and the extreme values present in the original data need to be handled in a way that doesn’t endanger the privacy of data subjects. Some synthetic data generators offer automated privacy and accuracy checks - it’s a good idea to start with these first. MOSTLY AI’s synthetic data generator offers this service for free - anyone can set up an account with just an email address.
Benefits of Synthetic Data
Synthetic data is not personal data by definition. As such, it is exempt from GDPR and similar privacy laws, allowing data scientists to freely explore the synthetic versions of datasets. Synthetic data is also one of the best tools to anonymize behavioral data without destroying patterns and correlations. These two qualities make it especially useful in all situations when personal data is used - from simple analytics to training sophisticated machine learning models.
However, privacy is not the only use case. Synthetic data generation can also be used in the following use cases:
- Data augmentation: This helps in the process of improving model performance by diversifying training data.
- Data imputation: Fill in the missing datapoints with meaningful synthetic data.
- Data sharing: Safe to share even beyond the walls of organizations. Think research collaborations or demoing products with realistic data.
- Rebalancing: Addresses issues of class imbalance.
- Downsampling: Creating smaller versions of massive datasets that look the same and mean the same as the original. Useful for initial data explorations, reducing computational costs and times.
The most popular Synthetic Data Generation Tools
In order to generate synthetic data we may use different tools that are available in the market. Let's explore some of these tools and understand how they work.
- MOSTLY AI: MOSTLY AI is the pioneering leader in the creation of structured synthetic data. It enables anyone to generate high-quality, production-like synthetic data for analytics, AI/ML development and data explorations. . Data teams can use it to originate, amend, and share datasets in ways that overcome the ethical and practical challenges of using real, anonymized, or dummy data.
- SDV: The most popular open-source Python library for synthetic data generation. Not the most sophisticated tool, but it does the job for more simple use cases when high accuracy is not a hard requirement.
- YData: If you want to try synthetic data generation on Azure or the AWS marketplace, YData’s generator is available on both platforms, offering a GDPR-compliant way to generate data for AI and machine learning models.
For a comprehensive list of synthetic data tools and companies, here is a curated list with synthetic data types.
Now as we have discussed the pros and cons of using these above-described tools and libraries for synthetic data generation, now let’s look at How we can use Mostly AI which is one of the best tools available in the market and easy to use.
MOSTLY AI is a synthetic data creation platform that assists enterprises in producing high-quality, privacy-protected synthetic data for a number of use cases such as machine learning, advanced analytics, software testing, and data sharing. It generates synthetic data using a proprietary AI-powered algorithm that learns the statistical aspects of the original data, such as correlations, distributions, and properties. This enables MOSTLY AI to produce synthetic data that is statistically representative of the actual data while simultaneously safeguarding data subjects' privacy.
Its synthetic data is not only private, but it is also simple to use and can be made in minutes. The platform has an easy-to-use interface powered by generative AI that enables organizations to input existing data, choose the appropriate output format, and produce synthetic data in a matter of seconds. Its synthetic data is a beneficial tool for organizations that need to preserve the privacy of their data while still using it for a number of objectives. The technology is simple to use and quickly creates high-quality, statistically representative synthetic data.
Synthetic data from MOSTLY AI is offered in a number of formats, including CSV, JSON, and XML. It can be utilized with several software programs, including SAS, R, and Python. Additionally, MOSTLY AI provides a number of tools and services, such as a data generator, a data explorer, and a data sharing platform, to assist organizations in using synthetic data.
Let’s explore how to use the MOSTLY AI platform. We can start by visiting the link below and creating an account.
MOSTLY AI: The Synthetic Data Generation and Knowledge Hub - MOSTLY AI
Once we have created the account we can see the home page where we can choose from different options related to data generation.
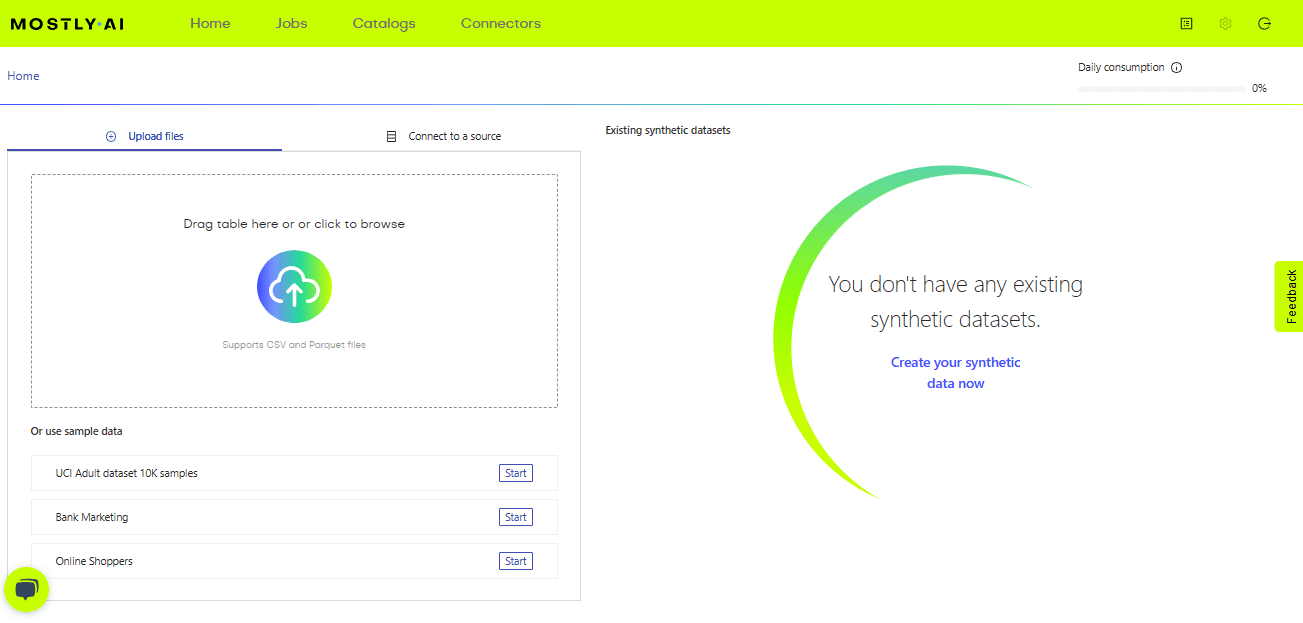
As you can see in the image above on the home page we can upload the original dataset for which we want to generate synthetic data or just to try it out we can use the sample data. We can upload data as per your requirement.
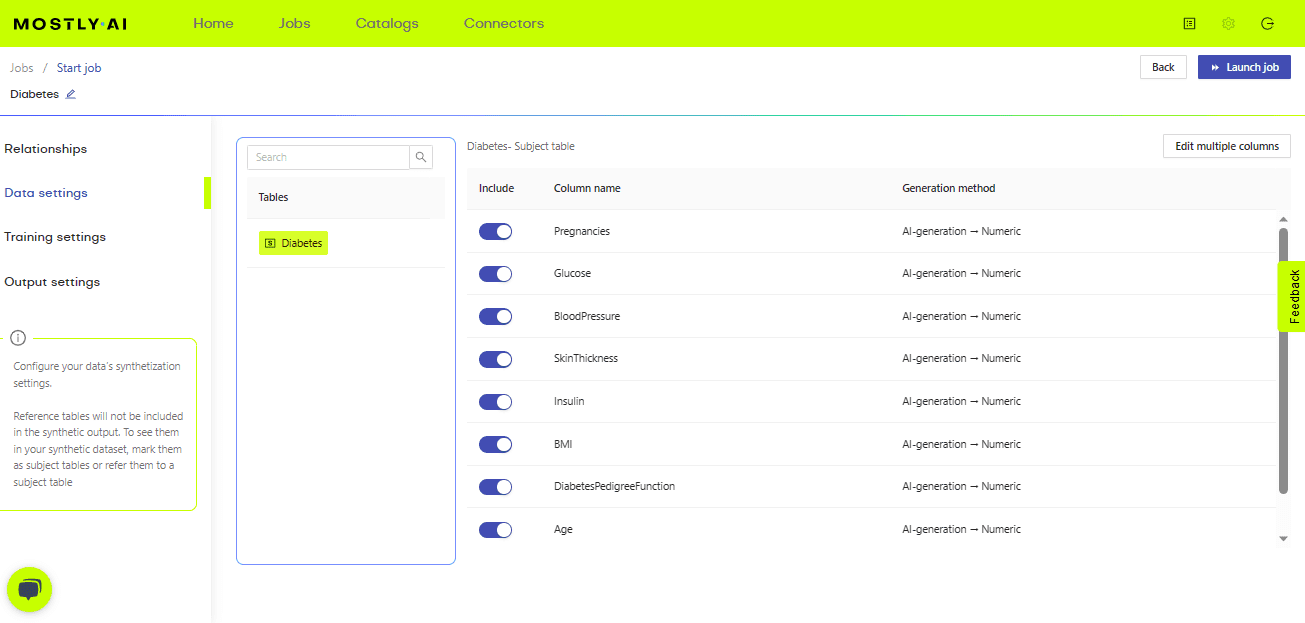
As you can see in the image above, once we upload the data we can make changes in terms of what columns we need to generate and also set different settings related to data, training and output.
Once we set all these properties as per our requirement we need to click on the launch job button to generate the data and it will be generated in real-time. On MOSTLY AI, we can generate 100K rows of data every day for free.
This is how you can use MOSTLY AI to generate synthetic data by setting the properties of data as required and in real time. There can be multiple use cases according to the problem that you are trying to solve. Go ahead and try this with datasets and let us know how useful you think this platform is, in the response section.
Himanshu Sharma is a Post Graduate in Applied Data Science from the Institute of Product Leadership. A self-motivated professional with experience working on Python Programming Language/Data Analysis. Looking to make my mark in the field of Data Science. Product Management. An active blogger with expertise in Technical Content Writing in Data Science, awarded as the Top Writer in the field of AI by Medium.